Java 10 新特性总结
Java 10 新特性总结
Java 10 新特性—概述
Java 10 是Java历史上的一个较小的版本,发布于2018年3月。
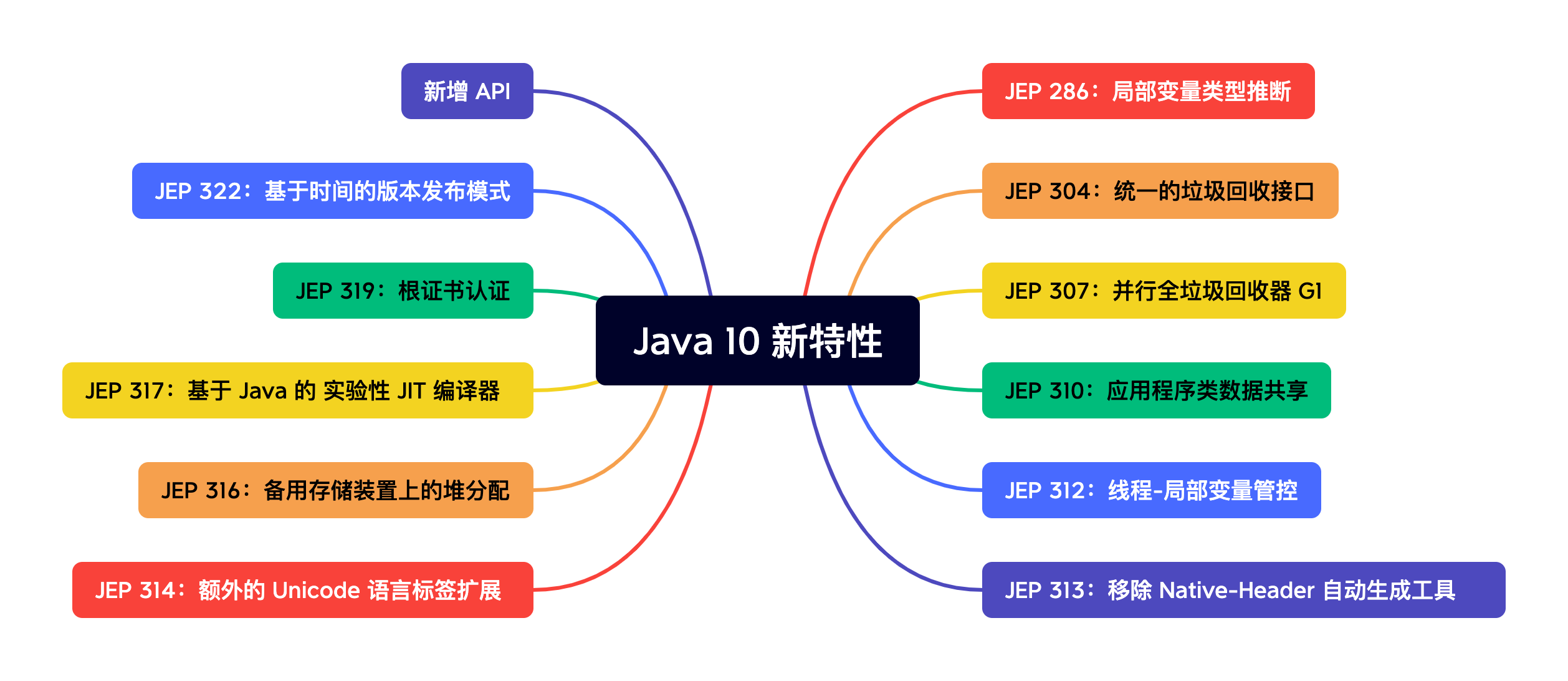
JEP 286:局部变量类型推断
Java 10中引入了var关键字,允许开发者在声明局部变量时不必显式声明变量的类型,编译器会自动根据变量的初始值推断变量的类型。这使得代码更加简洁,尤其是在处理泛型时。例如:
var list = new ArrayList<String>(); // 编译器推断 list 是 ArrayList<String> 类型
var stream = list.stream(); // 编译器推断 stream 是 Stream<String> 类型
**需要注意的是,****var**只能用在局部变量上,不能用于类的成员变量、方法参数或返回类型。
详情请参考:Java 10 新特性—局部变量类型推断
JEP 304:统一的垃圾回收接口
在当前的 Java 结构中,组成垃圾回收器(GC)实现的组件分散在代码库的各个部分。尽管这些惯例对于使用 GC 计划的 JDK 开发者来说比较熟悉,但对新的开发人员来说,对于在哪里查找特定 GC 的源代码,或者实现一个新的垃圾收集器常常会感到困惑。更重要的是,随着 Java modules 的出现,我们希望在构建过程中排除不需要的 GC,但是当前 GC 接口的横向结构会给排除、定位问题带来困难。
为解决此问题,需要整合并清理 GC 接口,以便更容易地实现新的 GC,并更好地维护现有的 GC。Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。这种方式提供了足够的灵活性来实现全新 GC 接口,同时允许以混合搭配方式重复使用现有代码,并且能够保持代码更加干净、整洁,便于排查收集器问题。
JEP 307:并行全垃圾回收器 G1
从 Java9 开始 G1 就了默认的垃圾回收器,G1 是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是 Java9 的 G1 的 FullGC 依然是使用单线程去完成标记清除算法,这可能会导致垃圾回收期在无法回收内存的时候触发 Full GC。
为了最大限度地减少 Full GC 造成的应用停顿的影响,Java 10 为 G1 引入多线程并行 GC,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
为了利用并行 Full GC,通常不需要特别的配置,因为 G1 在 Java 10 及以上版本默认就是并行执行 Full GC 的。但是,可以通过 JVM 参数来调整并行线程的数量, -XX:ParallelGCThreads=<N> 参数,其中 <N> 是希望使用的线程数。
JEP 310:应用程序类数据共享
应用程序类数据共享(Application Class-Data Sharing, 简称 AppCDS),旨在减少应用程序的启动时间,并减少Java应用程序在运行时的内存占用。
AppCDS 是在 Java 5 中引入的类数据共享(Class-Data Sharing, CDS)的一个扩展。CDS 的主要目的是通过共享已知库(比如 Java 核心库)的元数据,来加快 JVM 的启动时间和减少内存占用。在 Java 9 之前,CDS 仅限于 JDK 内置的类加载器和 Java 核心类。而从 Java 10 开始,AppCDS 允许开发者将应用程序自己的类包含进共享归档中,从而提升了启动性能和减少了资源占用。其工作原理如下:
- 静态归档: 在第一次执行时,JVM 会进行一个标准的类加载过程。在这个过程中,JVM 会解析所有的类和生成相应的元数据。使用
AppCDS时,可以通过-Xshare:dump选项指示 JVM 保存这些元数据到一个静态归档文件中(通常是一个.jsa文件)。 - 共享使用: 在接下来的启动过程中,可以通过
-Xshare:on与-XX:SharedArchiveFile=path_to_jsa_file选项来指示 JVM 使用先前创建的归档文件。这样,JVM 可以快速地映射归档文件中的数据到内存中,而不是重新解析所有类。 - 动态归档: Java 10 引入了动态类数据共享,即在应用程序运行时动态生成共享归档,这允许共享更多的类和加载器类型。
JEP 312:线程-局部变量管控
这是在 JVM 内部相当低级别的更改,现在将允许在不运行全局虚拟机安全点的情况下实现线程回调。这将使得停止单个线程变得可能和便宜,而不是只能启用或停止所有线程。
JEP 313:移除 Native-Header 自动生成工具
在 Java 9 之前,javah 是一个用来生成 C 头文件(即 .h 文件)的工具,这些头文件是从 Java 代码中定义的 native 方法所必需的,通常用于 Java 与本地代码(如 C 或 C++ 代码)之间的互操作。
但是它在 Java 9 被废弃,并在 Java 10 中被移除,原因是 javac 编译器已经提供了相同的功能。从 Java 8 开始,javac 编译器引入了 -h 选项,使得开发者可以在编译 Java 源代码的同时生成对应的本地方法头文件。因此,保留 javah 就显得多余,也使得工具链更加简化。
JEP 314:额外的 Unicode 语言标签扩展
该扩展主要是为了提升了java.util.Locale 类的能力,使得它能够更好地支持 BCP 47 语言标签以及 Unicode 扩展。
BCP 47 是“Best Current Practice 47”的缩写,它定义了一套用于标识人类语言的标签系统。这个标准不仅包括了 ISO 语言代码,还包括了扩展语言子标签、脚本、区域以及变体等。在 Java 7 中引入了对 BCP 47 语言标签的基本支持,但对扩展的支持并不完整。
Unicode 扩展是一系列的代码,用来标识与特定区域设置相关联的特定行为,例如,日历类型、数字系统等。在此次升级中增加了如下扩展支持:
| 编码 | 注释 |
|---|---|
| cu | 货币类型 |
| fw | 一周的第一天 |
| rg | 区域覆盖 |
| tz | 时区 |
Java 10 提升了对这些 Unicode 扩展的支持,特别是与区域设置相关的功能。这项增强允许开发者在 Java 应用程序中指定更详细的语言和区域设置偏好。
JEP 316:备用存储装置上的堆分配
传统上,Java 的堆内存(heap memory)是在主内存(RAM)中分配的。随着新型内存技术的出现,特别是非易失性内存(Non-Volatile Memory, NVM),出现了新的使用可能性。
Java 10 新特性(备用存储装置上的堆分配)允许 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配。这么做的目的是为了允许使用那些具有不同性能特征存储设备的系统上的 JVM 更好地管理其内存。
**注:**NVM 是一种保持存储信息即使在没有电力的情况下也不会丢失数据的内存类型,这对于数据的持久性和快速访问有很大的优势。
使用参数 -XX:+UseNVDIMM 来开启。
需要注意的是该项特性是一个实验性特性,意味着在未来的 Java 版本中可能会有变更,且需要相应的硬件设备和操作系统需要支持 NVM。
JEP 317:基于 Java 的 实验性 JIT 编译器
Java 10 引入了一项名为 "基于 Java 的实验性 JIT 编译器" 的新特性,该编译器是基于 Graal 开源项目,用 Java 编写的。Java 10 将其用作 Linux/x64 平台上的实验性 JIT 编译器开始进行测试和调试工作,以作为 Java HotSpot VM 的一个实验性替代品。
由于 Graal 是一个相对较新的项目,并且 JIT 编译器对于 JVM 的性能至关重要,因此 Graal JIT 被标记为实验性特性。这意味着它不是默认激活的,并且在未来的版本中可能会有较大的改变。开启方式如下:
-XX:+ UnlockExperimentalVMOptions -XX:+ UseJVMCICompiler
JEP 319:根证书认证
在 Java 应用中,安全的网络通信经常依赖于 SSL/TLS 协议。这些协议使用证书来实现服务器的身份验证,以保护用户免受中间人攻击。证书通常由证书颁发机构(CAs)签发。为了验证一个给定的证书,Java 运行时需要访问可信的 CA 根证书。如果没有这些根证书,Java 应用可能无法与使用 SSL/TLS 的服务通信,或者需要额外的配置才能工作。
然而,自 Java 9 起在 keytool 中加入参数 -cacerts ,可以查看当前 JDK 管理的根证书,但是 Java 9 中 cacerts 目录为空,需要手动安装和管理根证书,这样会给开发者带来很多不便。所以从 Java 10 开始,将会在 JDK 中提供一套默认的 CA 根证书。该跟证书是 OpenJDK 提供的一组开源的 CA 根证书,这样就不再需要手动配置 CA 根证书,因为它们已经包含在 JDK 中了。
JEP 322:基于时间的版本发布模式
以前 Java 的更新和新版本发布没有固定的时间表。新的特性是在它们完成后发布,这就会导致 Java 长时间没有更新,或者更新之间的时间间隔不确定。这种模式对于希望规划未来功能和改进的开发者和企业来说是个挑战。
所以 Java 10 引入了一种新的版本发布模式,标志着 Oracle 对 Java 发布策略的一次重大改变。这一新模式被称为基于时间的发布版本模式,这就意味着 Java 将会有更加频繁且可预测的版本更新。
在基于时间的版本发布模式下,Java 版本将在每个季度(1 月,4 月,7 月,10 月)发布。 更新版本将严格限于安全性问题,回归和较新特性中的错误的修复。 按照进度计划,可以说每个特性版本在下一个特性版本发布之前都会收到两个更新。
新的版本好格式如下:
$FEATURE.$INTERIM.$UPDATE.$PATCH
| 名称 | 描述 |
|---|---|
$FEATURE | 它会每 6 个月增加一次,具体取决于特性发布版本,例如:JDK 10,JDK11。(以前为$MAJOR。) |
$INTERIM | 通常为零,因为六个月内不会有任何中期发布。 对于包含兼容的错误修复和增强特性但不兼容的更改,不删除的特性以及对标准 API 的更改的非特性版本,它将增加。 (以前为$MINOR。) |
$UPDATE | 对于解决安全问题,回归和较新特性中的错误的兼容更新版本,它将递增。 (以前为$SECURITY。) |
$PATCH | 仅在需要紧急发布以解决关键问题时才会增加。 |
新增 API
Java 10 中添加了 73 个新 API,下面是一些最主要的:
| API | 描述 |
|---|---|
List.copyOf, Set.copyOf, Map.copyOf | 这些方法提供了一种创建不可修改集合的快捷方式,参数是现有的集合。 |
Collectors.toUnmodifiableList, Collectors.toUnmodifiableSet, Collectors.toUnmodifiableMap | 这些方法允许将Stream的元素收集到不可修改的集合中 |
Optional.orElseThrow() | Optional.get()的一个更易读的替代,它在值不存在时抛出NoSuchElementException。 |
关于 copyOf() 更多信息参考文章:Java 10 新特性—不可变集合的增强
Java 10 新特性—局部变量类型推断
局部变量类型推断是 Java 10 中引入的一项重要特性,通过使用var关键字,允许我们在声明局部变量时省略显式类型。类型推断意味着编译器会查看变量的初始化器并推断出变量的类型。
产生背景
刚刚学 Java 语法时,我们就被告知:在 Java 中,所有的变量在使用前必须声明,所以我们就有了如下代码:
int i = 10;
String str = "死磕 Java 新特性";
List<String> list = new ArrayList<>();
甚至很多小伙伴已经养成了习惯,在声明变量时永远都是从左写到右,即先写变量类型,然后变量名,最后初始化,这样写有问题吗?没有问题,但是比较繁琐,简单的变量类型还可以接受,但是如果复杂呢?比如这个:
Map<String, List<String>> myMap = new HashMap<>();
又或者这个:
List<Map<String,List<String>>> list = new ArrayList<>();
确实很繁琐,对于很多变量声明通常需要重复类型信息,这显得冗余又不增加任何价值。而且许多其他现代编程语言,如Scala、Kotlin和C#,都已经提供了类型推断的能力,Java 作为一门与时俱进的现代化编程语言,怎么能不跟进呢?
好处
- 减少样板代:减少了啰嗦和形式的代码,避免了信息冗余,使得代码更易于编写和阅读。例如用
var list = new ArrayList<String>();代替ArrayList<String> list = new ArrayList<>();。 - 增强代码的可读性:很多时候我们在阅读代码时并不关注变量的类型,或者变量类型显而易见,而
var使得变量的意图变得更清晰。 - 提高开发效率:减少编写显式类型所需的时间和努力,可以让开发者更专注于业务逻辑本身,毕竟太多的类型声明只会分散注意力,不会带来额外的好处。
使用场景
局部变量声明
在局部代码块中声明临时变量,特别是当这些变量的类型很明显时,使用var可以减少代码的冗余。比如
var i = 10;
var str = "死磕 Java 新特性";
这是最简单明了的使用方式 了,尤其是局部变量的类型常常非常长或复杂,使用var能够使代码更简洁。。
初始化集合和泛型表达式
在使用集合或泛型类时,类型通常很复杂,使用 var 可以避免在声明和初始化时重复复杂的类型。
List<String> list = new ArrayList<>();
// 变成
var list = new ArrayList<String>();
Map<String,List<String>> map = new HashMap<>();
// 变成
var map = new HashMap<String,List<String>>();
在 Java 7 以前,我们声明集合变量时需要这样写:
List<String> list = new ArrayList<String>(); // 两侧都需要加上泛型类型
可能你觉得在声明变量的时候已经指明了参数类型,为什么还要在初始化对象时再指定?所以在 Java 7 中引入泛型类型推断,于是写法可以简化这样的:
List<String> list = new ArrayList<>(); // 只需要在左侧加上泛型类型
编译器会根据变量声明时的泛型类型自动推断出实例化 List 时的泛型类型。但是我们一定要加上 “<>”,只有加上这个 “<>” 才表示是自动类型推断。
现在 Java 10 又引入了局部变量类型推断,所以又可以进一步简化:
var list = new ArrayList<String>();
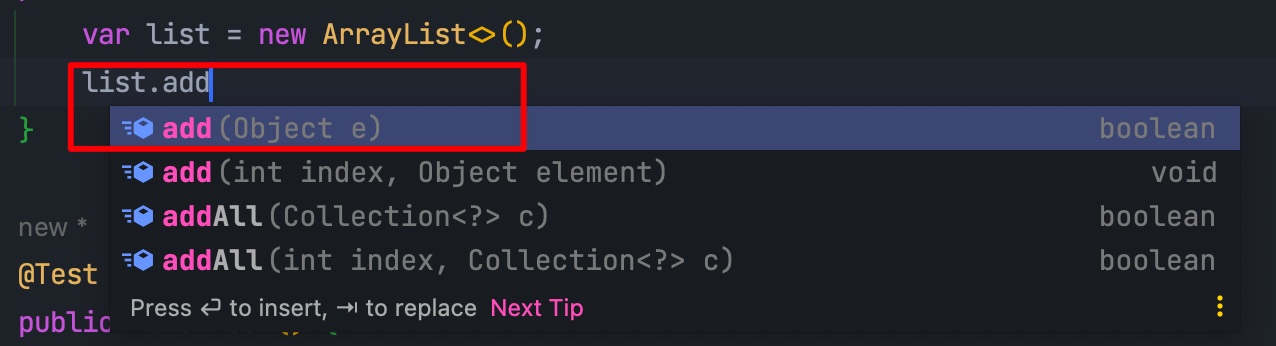
可能有小伙伴会问,可以写成下面这种格式么:
var list = new ArrayList<>();
可以,只不过这个时候类型就变成了 Object:
遍历操作
迭代时,使用 var 可以避免编写冗长的类型名称。例如:
- 常规写法
@Test
public void varTest() {
var list = new ArrayList<String>();
list.add("死磕 Java 新特性");
list.add("死磕 Java 并发");
list.add("死磕 Netty");
for (String str : list) {
System.out.println(str);
}
}
for-each 里面指明了变量 str 的类型,但是我们明明都知道 list 的类型是 String,为什么还要指明呢?不是多此一举么:
@Test
public void varTest() {
//
for (var str : list) {
System.out.println(str);
}
}
在try-with-resources语句中
try-with-resources要求变量是final或事实上的final,在这里使用var可以减少冗余代码。比如:
try (var reader = new BufferedReader(new FileReader(path))) {
// 使用reader
}
不适用场景
虽然局部变量类型推断可以提高代码的简洁性,但在某些情况下使用var可能并不合适,因为它可能会降低代码的可读性和可维护性。
- 使用null初始化变量时
不能使用 var 来声明一个初始化为 null 的变量,因为 var 需要足够的信息来推断出变量的类型。
var object = null; // 错误的使用方式,因为 null 不能推断出具体类型
- 需要使用具体类特定方法时
如果需要调用一个特定类的方法,而这个方法不是由其所有可能的子类共有的,那么最好显式声明这个类类型。比如:
- 类型信息很重要
有些时候变量的类型对于我们理解代码很重要,这个时候我们就不能省略变量的类型,尽管可以省略。
- 数组静态初始化
数组静态初始化是不能省略的。
int[] arr1 = new int[]{1,2,3,4,5} // 情况①:正常情况
int[] arr1 = {1,2,3,4,5}; // 情况②:从左边推断后面,可以省略
var arr2 = new int[]{1,2,3,4,5}; // 情况③:从右边推断前面,可以省略
var arr3 = {1,2,3,4,5} // 情况④:无法推断,不能省略
这里这是一些场景,还有其他一些场景也是不能使用的,我们把握一个核心原则就行:能够让编译器推断出是什么类型的都可以使用。
注意事项
- 使用类型推断时,必须在变量声明时初始化变量,这样编译器才能推断出类型。它只适用于局部变量,不能用于方法参数、返回类型、字段等。
- 类型推断可能使得代码阅读者不清楚变量的实际类型,尤其是当初始化器的表达式不直接显露类型时。应当避免过度使用**
var**。
Java 10 新特性—不可变集合的增强
Java 9 开始引入不可变集合,我们通过 of() 即可创建一个不可变集合(详情见:Java 9 新特性—新增只读集合和工厂方法)。但是有时候我们需要利用现有集合来创建一个不可变副本,然而 Java 9 并没有提供该方法,所以 Java10 对其进行了增强。
Java 10 新增 copyOf() 用于创建现有集合的不可变副本。分为以下两种情况:
- 如果原集合已经是不可变的,那么则返回原集合,
- 如果元集合不是不可变的,那么则创建一个新的对象。
如下:
@Test
public void copyOfTest() {
var list1 = List.of("死磕 Java 新特性","死磕 Java 并发","死磕 Netty");
var copyList1 = List.copyOf(list1);
System.out.println(list1 == copyList1);
var list2 = Arrays.asList("死磕 Java 新特性","死磕 Java 并发","死磕 Netty");
var copyList2 = List.copyOf(list2);
System.out.println(list2 == copyList2);
}
执行结果:
true
false
List.copyOf(list1) 由于 list1 本身是不可变集合,所以就直接将 list1 返回了,所以 list1 == copyList1,而 list2 是可变的,所以需要新建一个不可变对象,所以 list2 != copyList2。
从 copyOf() 的源码中我们也可以看出:
static <E> List<E> listCopy(Collection<? extends E> coll) {
if (coll instanceof List12 || (coll instanceof ListN && ! ((ListN<?>)coll).allowNulls)) {
return (List<E>)coll;
} else {
return (List<E>)List.of(coll.toArray()); // implicit nullcheck of coll
}
}