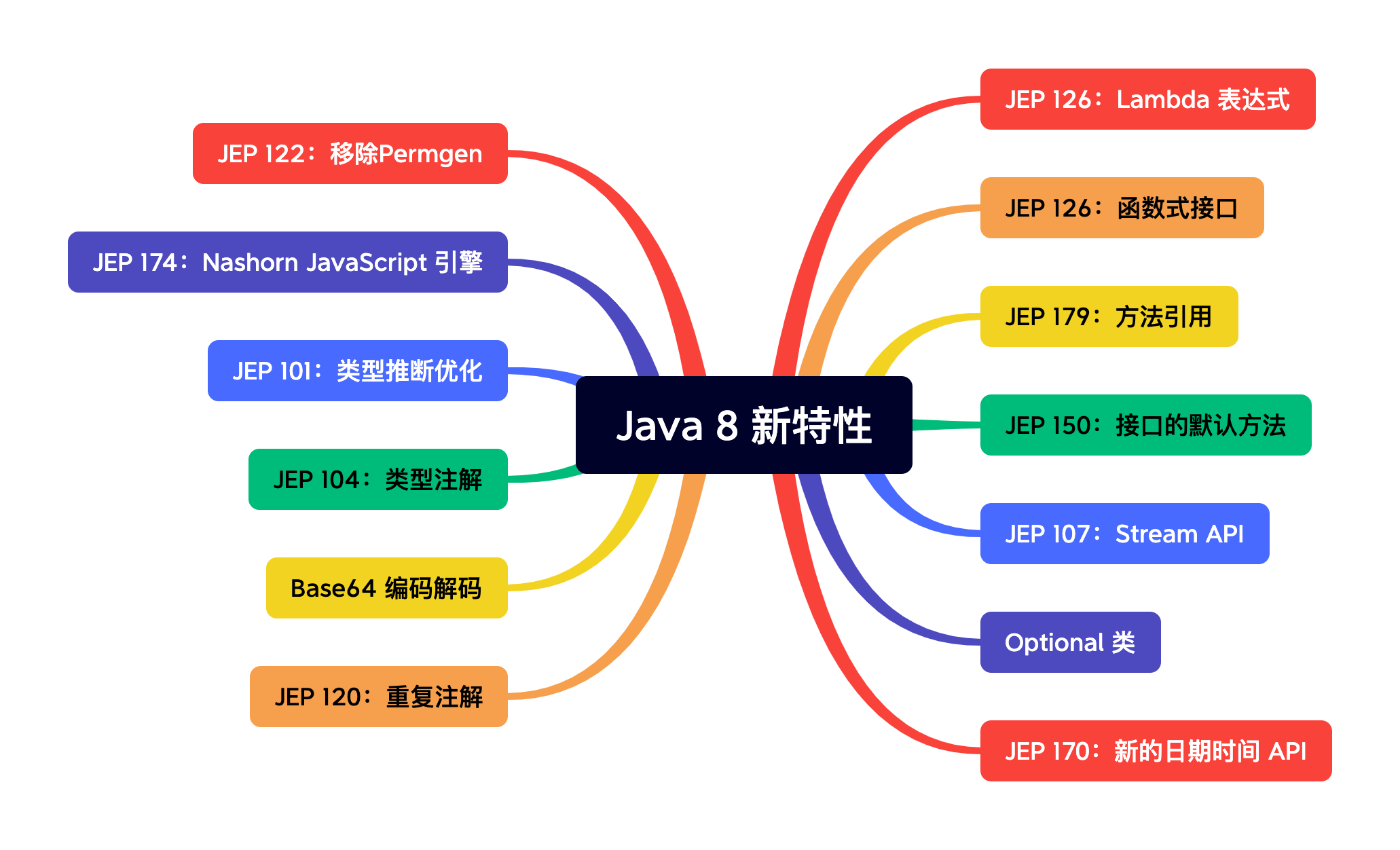
Java 8 新特性总结
Java 8 新特性总结
Java 8 新特性—概述
Java 8 是Java历史上一个重大的版本更新,发布于2014年3月18日。
JEP 126:Lambda 表达式
Lambda 表达式是 Java 8 新特性中最重要且最显著的一个,为 Java 增加了函数式编程的能力,使得代码变得更加简洁和易读。Lambda 表达式主要用于简化匿名内部类的实现。
Lambda 表达式的基本语法:
(parameters) -> expression 或 (parameters) -> { statements; }
parameters:是 Lambda表达式的参数列表,可以为空或包含一个或多个参数。->:是 Lambda 操作符,用于将参数和 Lambda 主体分开。expression:是 Lambda 表达式的返回值,或者在主体中执行的单一表达式。{ statements; }:是 Lambda 主体,包含了一系列语句,如果需要执行多个操作,就需要使用这种形式。
它具有如下几个特点:
- 无需声明类型:Lambda 表达式不需要声明参数类型,编译器可以自动推断参数类型。
- 可选的参数圆括号:当只有一个参数时,可以省略圆括号。但是当参数个数大于一个时,圆括号是必需的。空括号用于表示空参数集。
- 可选的大括号:当 Lambda 表达式的主体只包含一个表达式时,可以省略大括号。当表达式需要包含多个语句时,需要使用大括号。
- 可选的返回关键字:当 Lambda 表达式主体只有一个表达式,且该表达式会自动返回结果时,可以省略 return 关键字。
JEP 126:函数式接口
Java 8 引入函数式接口的主要目的是支持函数式编程范式,也就是 Lambda 表达式。在函数式编程语言中,函数被当做一等公民对待,Lambda 表达式的类型是函数,它可以像其他数据类型一样进行传递、赋值和操作。但是在 Java 中,“一切皆对象”是不可违背的宗旨,所以 Lambda 表达式是对象,而不是函数,他们必须要依附于一类特别的对象类型:函数式接口。所以函数式接口是与Lambda表达式紧密相连的,它为Java添加了一种新的抽象层次,允许将方法作为一等公民对待。
函数式接口具有两个特点:
- 只包含一个抽象方法:函数式接口只能有一个抽象方法,但可以包含多个默认方法或静态方法。
- 用**
@FunctionalInterface**注解标记:该注解不强制,但通常会使用它来标记该接口为函数式接口。这样做可以让编译器检查接口是否符合函数式接口的定义,以避免不必要的错误。
一般来说函数式接口有两个最主要的用途:
- 与 Lambda表达式一起使用,为Java带来更加函数式的编程风格。
- 用于实现简单的函数策略或行为,如回调、事件处理等。
更多阅读:Java 8 新特性—函数式接口
JEP 179:方法引用
为了提升 Java 编程语言的表达力和可读性,特别是在配合 Lambda 表达式和函数式编程风格,Java 8 引入方法引用。
方法引用实际上是一个简化版的 Lambda 表达式,它允许我们以更简洁的方式引用方法。它有如下几种类型:
静态方法引用
:使用
类名::静态方法名的形式。
- 例如,
String::valueOf相当于x -> String.valueOf(x)。
- 例如,
实例方法引用(对象的实例方法)
:使用
实例对象::实例方法名的形式。
- 例如,假设有一个
String对象myString,那么myString::length相当于() -> myString.length()。
- 例如,假设有一个
特定类型的任意对象的实例方法引用
:使用
类名::实例方法名。
- 例如,
String::length相当于str -> str.length()。这里不是调用特定对象的length方法,而是用于任意的String对象。
- 例如,
构造器引用
:使用
类名::new。
- 例如,
ArrayList::new相当于() -> new ArrayList<>()。
- 例如,
JEP 150:接口的默认方法
在 Java 8 之前,接口中可以申明方法和变量的,只不过变量必须是 public、static、final 的,方法必须是 public、abstract的。我们知道接口的设计是一项巨大的工作,因为如果我们需要在接口中新增一个方法,需要对它的所有实现类都进行修改,如果它的实现类比较少还可以接受,如果实现类比较多则工作量就比较大了。
为了解决这个问题,Java 8 引入了默认方法,默认方法允许在接口中添加具有默认实现的方法,它使得接口可以包含方法的实现,而不仅仅是抽象方法的定义。
默认方法是接口中带有 default 关键字的非抽象方法。这种方法可以有自己的实现,而不需要子类去覆盖它。
默认方法允许我们向接口添加新方法而不破坏现有的实现。它解决了在 Java 8 之前,向接口添加新方法意味着所有实现该接口的类都必须修改的问题。
JEP 107:Stream API
为了解决 Java 8 之前版本中集合操作的一些限制和不足,提高数据处理的效率和代码的简洁性,Java 8 引入 Stream API,它的引入标志着 Java 对集合操作迎来了的一种全新的处理方式,它在处理集合类时提供了一种更高效、声明式的方法。
Stream API 的核心思想是将数据处理操作以函数式的方式链式连接,以便于执行各种操作,如过滤、映射、排序、归约等,而无需显式编写传统的循环代码。
下面是 Stream API 的一些重要概念和操作:
Stream(流):
Stream是 Java 8 中处理集合的关键抽象概念,它是数据渠道,用于操作数据源所生成的元素序列。这些数据源可以来自集合(
Collection)、数组、
I/O操作等等。它具有如下几个特点:
Stream不会存储数据。Stream不会改变源数据对象,它返回一个持有结果的新的Stream。Stream操作是延迟执行的,这就意味着他们要等到需要结果的时候才会去执行。
中间操作:这些操作允许您在
Stream上执行一系列的数据处理。常见的中间操作有filter(过滤)、map(映射)、distinct(去重)、sorted(排序)、limit(截断)、skip(跳过)等。这些操作返回的仍然是一个 Stream。终端操作:终端操作是对流进行最终处理的操作。当调用终端操作时,流将被消费,不能再进行进一步的中间操作。常见的终端操作包括
forEach(遍历元素)、collect(将元素收集到集合中)、reduce(归约操作,如求和、求最大值)、count(计数)等。惰性求值:Stream 操作是惰性的,只有在调用终端操作时才会执行中间操作。这可以提高性能,因为只处理需要的数据。
Optional 类
Java 8 引入了 Optional 类,这是一个为了解决空指针异常(NullPointerException)而设计的容器类。它可以帮助开发者在编程时更优雅地处理可能为 null 的情况。
JEP 170:新的日期时间 API
作为 Java 开发者你一定直接或者间接使用过 java.util.Date 、java.util.Calendar、java.text.SimpleDateFormat 这三个类吧,这三个类是 Java 用于处理日期、日历、日期时间格式化的。由于他们存在一些问题,诸如:
线程不安全
:
java.util.Date和java.util.Calendar线程不安全,这就导致我们在多线程环境使用需要额外注意。java.text.SimpleDateFormat也是线程不安全的,这可能导致性能问题和日期格式化错误。而且它的模式字符串容易出错,且不够直观。
可变性:
java.util.Date类是可变的,这意味着我们可以随时修改它,如果一不小心就会导致数据不一致问题。时区处理困难:Java 8 版本以前的日期 API 在时区处理上存在问题,例如时区转换和夏令时处理不够灵活和准确。而且时区信息在
Date对象中存储不明确,这使得正确处理时区变得复杂。设计不佳
:
- 日期和日期格式化分布在多个包中。
java.util.Date的默认日期,年竟然是从 1900 开始,月从 1 开始,日从 1 开始,没有统一性。而且java.util.Date类也缺少直接操作日期的相关方法。- 日期和时间处理通常需要大量的样板代码,使得代码变得冗长和难以维护。
基于上述原因,Java 8 重新设计了日期时间 API,以提供更好的性能、可读性和可用性,同时解决了这些问题,使得在 Java 中处理日期和时间变得更加方便和可靠。相比 Java 8 之前的版本,Java 8 版本的日期时间 API 具有如下几个优点:
- 不可变性(Immutability):Java 8的日期时间类(如
LocalDate、LocalTime和LocalDateTime)都是不可变的,一旦创建就不能被修改。这确保了线程安全,避免了并发问题。 - 清晰的API设计:Java 8 的日期时间 API 采用了更清晰、更一致的设计,相比于以前版本的
Date和Calendar更易于理解和使用。而且它们还提供了丰富的方法来执行日期和时间的各种操作,如加减、比较、格式化等。 - 本地化支持:Java 8 的日期时间 API 支持本地化,可以轻松处理不同地区和语言的日期和时间格式。它们能够自动适应不同的时区和夏令时规则。
- 新的时区处理:Java 8引入了
ZoneId和ZoneOffset等新的时区类,使时区处理更加精确和灵活。这有助于解决以前版本中时区处理的问题。 - 新的格式化API:Java 8引入了
DateTimeFormatter类,用于格式化和解析日期和时间,支持自定义格式和本地化。这提供了更强大和灵活的格式化选项。 - 更好的性能:Java 8 的日期时间API 比以前的API 性能更佳。
JEP 120:重复注解
在 Java 8 之前的版本中,对于一个特定的类型,一个注解在同一个声明上只能使用一次。Java 8 引入了重复注解,它允许对同一个类型的注解在同一声明或类型上多次使用。
工作原理如下:
- 定义重复注解:您需要定义一个注解,并用
@Repeatable元注解标注它。@Repeatable接收一个参数,该参数是一个容器注解,用于存储重复注解的实例。 - 定义容器注解:容器注解定义了一个注解数组,用于存放重复注解的多个实例。这个容器注解也需要具有运行时的保留策略(
@Retention(RetentionPolicy.RUNTIME))。
Base64 编码解码
在 Java 8 之前,我们通常需要依赖于第三方库(如 Apache Commons Codec)或者使用 Java 内部类(如 sun.misc.BASE64Encoder 和 sun.misc.BASE64Decoder)来处理 Base64 编解码。但是这些内部类并非 Java 官方的一部分,它们的使用并不推荐,因为它们可能会在未来的版本中发生变化,造成兼容性问题。同时使用非官方或内部 API 可能导致安全漏洞或运行时错误,所以 Java 8 引入一个新的 Base64 编解码 API,它处理 Base64 编码和解码的官方、标准化的方法。
Java 8 中的 Base64 API 包含在 java.util 包中。它提供了以下三种类型的 Base64 编解码器:
- 基本型(Basic):用于处理常规的 Base64 编码和解码。它不对输出进行换行处理,适合于在URLs和文件名中使用。
- URL和文件名安全型(URL and Filename Safe):输出映射到一组 URL 和文件名安全的字符集。它使用 '-' 和 '_' 替换标准 Base64 中的 '+' 和 '/' 字符。
- MIME型:用于处理 MIME 类型的数据(例如,邮件)。它在每行生成 76 个字符后插入一个换行符。
JEP 104:类型注解
在 Java 8 之前,注解仅限于声明(如类、方法或字段)。这种限制意味着注解的用途在许多编程情景中受到限制,特别是在需要对类型本身(而不仅仅是声明)进行描述时。为了提高注解的能力,Java 8 引入类型注解来增强注解的功能。
该特性扩展了注解的应用范围,允许我们将注解应用于任何使用类型的地方,而不仅仅是声明。包括以下情况:
- 对象创建(如
new表达式) - 类型转换和强制类型转换
- 实现(implements)语句
- 泛型类型参数(如
List<@NonNull String>)
更多阅读:Java 8 新特性—类型注解
JEP 101:类型推断优化
在 Java 8 之前,Java 的类型推断主要局限于泛型方法调用的返回类型。这意味着在许多情况下,我们不得不显式指定泛型参数,即使它们可以从上下文中推断出来。这种限制使得代码变得冗长且不够直观,特别是在使用泛型集合和泛型方法时。
为了提高编码效率和可读性,同时简化泛型使用,Java 8 中引入了对类型推断机制的优化,扩大了类型推断的范围,使其能在更多情况下自动推断出类型信息,包括:
- Lambda 表达式中的类型推断:在使用 Lambda 表达式时,编译器可以根据上下文推断出参数类型,从而减少了在某些情况下编写显式类型的需求。
- 泛型方法调用的改进:在调用泛型方法时,编译器可以更好地推断方法参数、返回类型以及链式调用中间步骤的类型。
- 泛型构造器的类型推断:在创建泛型对象时,编译器能够推断出构造器参数的类型。
更多阅读:Java 8 新特性—类型推断优化
JEP 174:Nashorn JavaScript 引擎
在 Java 8 之前,Java 平台的主要 JavaScript 引擎是 Mozilla 的 Rhino。Rhino 是一个成熟的引擎,但由于其架构和设计年代较早,它在性能和与 Java 的集成方面存在一些限制。随着 JavaScript 在 Web 和服务器端应用中日益重要,需要一个更现代、更高效的 JavaScript 引擎来提供更好的性能和更深度的 Java 集成。因此,Nashorn 引擎被引入作为 Java 平台的一部分。
Nashorn 是一个基于 Java 的 JavaScript 引擎,它完全用 Java 语言编写,并且是 Rhino 的替代品。主要特点:
- 基于 JVM 的执行:Nashorn 是作为 Java 虚拟机的一个原生组件实现的,它直接编译 JavaScript 代码到 Java 字节码。这意味着它可以充分利用 JVM 的性能优化和管理能力。
- 高性能:与 Rhino 相比,Nashorn 提供了显著的性能提升,特别是在执行 JavaScript 代码方面。
- 与 Java 的深度集成:Nashorn 允许 JavaScript 代码和 Java 代码之间有更紧密的交互。开发者可以在 JavaScript 中方便地调用 Java 类库和对象,反之亦然。
- ECMAScript 5.1 支持:Nashorn 支持 ECMAScript 5.1 规范,为开发者提供了一个符合标准的现代 JavaScript 编程环境。
JEP 122:移除Permgen
在 Java 8 之前,JJVM使用永久代(PermGen)的内存区域来存储类的元数据和方法数据。随着时间的推移,这个设计开始显现出一些问题,特别是在应用程序频繁加载和卸载类的场景中,比如在 Java EE 应用服务器和热部署环境中。
永久代有一个固定的大小限制,当类的数量和大小超过这个限制时,就会抛出 OutOfMemoryError: PermGen space 错误。这种设计限制了 Java 的灵活性和可伸缩性。
Java 8 移除永久代并用元空间(Metaspace)的新内存区域来取代它。相比永久代,元空间的具有如下优势:
- 基于本地内存:元空间不在 JVM 的堆内存中,而是直接使用本地内存(操作系统的内存)。这意味着它不再受到 Java 堆大小的限制。
- 动态调整大小:元空间的大小可以根据应用程序的需求动态调整。这减少了内存溢出的风险,并允许应用更高效地管理内存。
- 更好的性能:由于移除了固定大小的限制,元空间可以提供更好的性能,尤其是在大型应用和复杂的部署环境中。
Java 8 新特性—Lambda 表达式
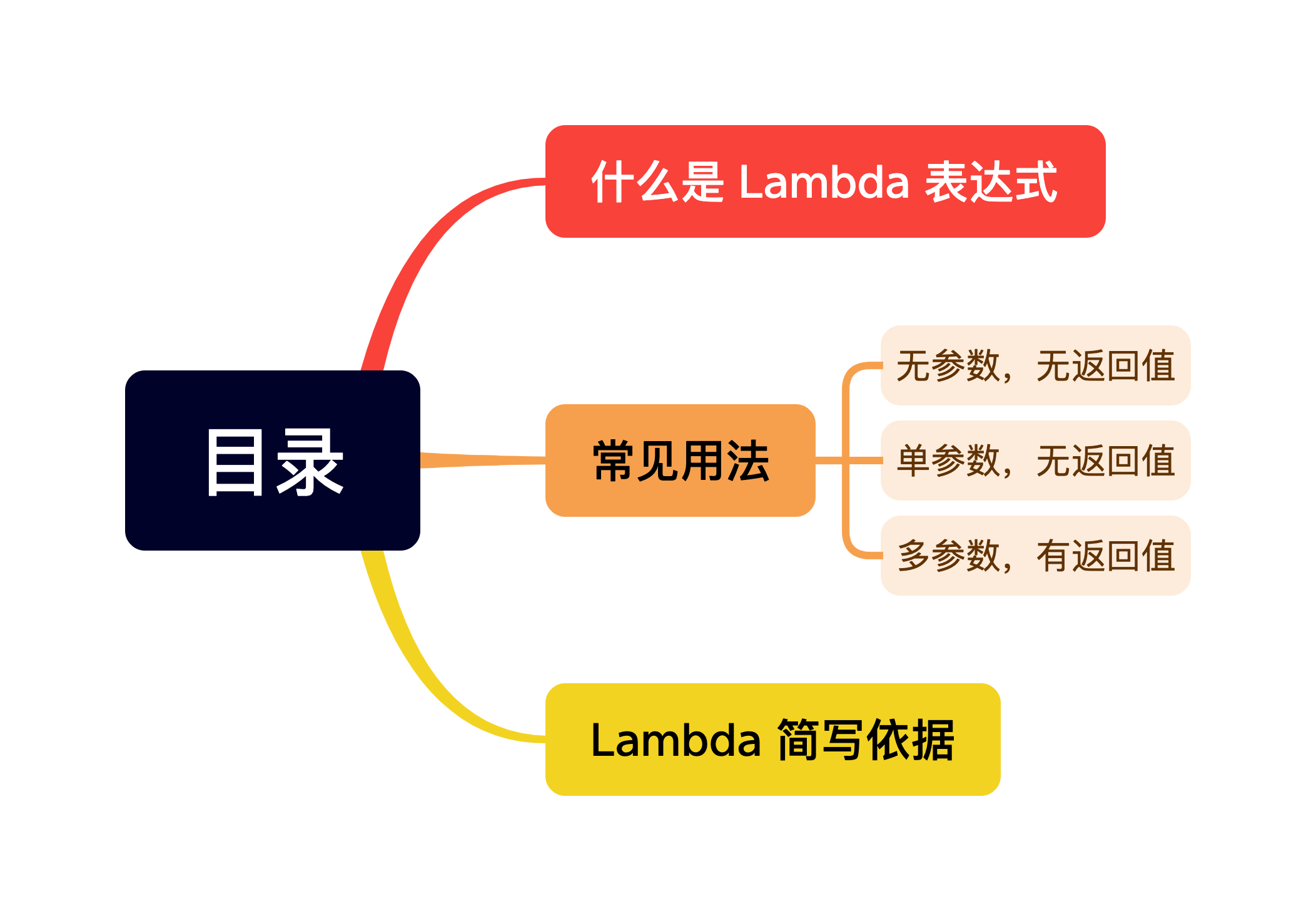
什么是 Lambda 表达式
Lambda 表达式是在 Java 8 中引入,并且被吹捧为 Java 8 最大的特性。它是函数式编程的的一个重要特性,标志着 Java 向函数式编程迈出了重要的第一步。
它的语法如下:
(parameters) -> expression
或者
(parameters) -> { statements; }
其中
parameters:是 Lambda表达式的参数列表,可以为空或包含一个或多个参数。->:是 Lambda 操作符,用于将参数和 Lambda 主体分开。expression:是 Lambda 表达式的返回值,或者在主体中执行的单一表达式。{ statements; }:是 Lambda 主体,包含了一系列语句,如果需要执行多个操作,就需要使用这种形式。
Java 8 引入 Lambda 表达式的主要作用是简化部分匿名内部类的写法。使用它可以完成用少量的代码实现复杂的功能,极大的简化代码代码量和代码结构。同时,JDK 中也增加了大量的内置函数式接口供我们使用,使得在使用 Lambda 表达式时更加简单、高效。
下面我们就来看它的一些常见用法。
常见用法
无参数,无返回值
例如 Runnable 接口的 run()。
在 Java 8 版本之前的版本,我们一般都是这样用:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("死磕 Java 就是牛逼...");
}
}).start();
从 Java 8 开始,无参数匿名内部类可以简写成如下这种方式:
() -> {
执行语句
}
所以上面代码可以简写成这样的:
new Thread(() -> System.out.println("死磕 Java 就是牛逼...")).start();
单参数,无返回值
只有一个参数,无返回值,如下:
(x) -> System.out.println(x);
在 Java 8 中,有一个函数式接口 Consumer,它定义如下:
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
}
我们用它来演示下:
Consumer<String> consumer = (String s) -> {
System.out.println(s);
};
consumer.accept("死磕 Java 就是牛...");
是不是比较简便,但是这段代码还不够简便,它还可以进行多次优化,
- 如果 Lambda 主体只有一条语句,则
{、}可以省略
Consumer<String> consumer = (String s) -> System.out.println(s);
- Lambda 表达式有一个依据:类型推断机制。在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。所以
(String s)可以简写为(s):
Consumer<String> consumer = (s) -> System.out.println(s);
- 对于只有一个参数的情况,左侧括号可以省略:
Consumer<String> consumer = s -> System.out.println(s);
多参数,有返回值
如 Comparator 接口的 compare(T o1, T o2) 方法,在 Java 8 之前,写法如下:
Comparator<Integer> comparator = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("o1:" + o1);
System.out.println("o2:" + o2);
return o1.compareTo(o2);
}
};
comparator.compare(12,13);
使用 Lambda 表达式后:
Comparator<Integer> comparator = (o1, o2) -> {
System.out.println("o1:" + o1);
System.out.println("o2:" + o2);
return o1.compareTo(o2);
};
comparator.compare(12,13);
当然,如果去掉 System.out.println(),还可以简写为 Comparator<Integer> comparator = (o1, o2) -> o1.compareTo(o2); ,这里是可以省略 return 关键字的。
这里就 Lambda 的简写做一个总结:
- 类型推断:编译器可以根据上下文推断 Lambda 表达式的参数类型,从而可以省略参数类型的声明。
- 单一参数:当 Lambda 表达式只有一个参数时,可以省略参数外的括号。如:
(x) → x * 2可以简写为x → x * 2。 - 单表达式:当 Lambda 表达式只有一行代码时,可以省略大括号和 return 关键字。如
(x,y) → {return x + y}可以简写为(x,y) → x + y。
Lambda 简写依据
Lambda 简写的依据有两个:
1、必须有相应的函数式接口
所谓函数式接口函数式就是指只包含一个抽象方法的接口,它是在 Java 8 版本中引入的,其主要目的是支持函数式编程,有了函数式接口我们可以将函数作为参数传递、将函数作为返回值返回,同时也为使用 Lambda 表达式提供了支持。
函数式接口具有以下特征:
- 只包含一个抽象方法:函数式接口只能有一个抽象方法,但可以包含多个默认方法或静态方法(Java 8 中有另一个新特性:
default关键字)。这个唯一的抽象方法通常用来表示某种功能或操作。 - 用**
@FunctionalInterface**注解标记:注解不强制,但通常会使用它来标记该接口为函数式接口。这样做可以让编译器检查接口是否符合函数式接口的定义,以避免不必要的错误。
2、类型推断机制
类型推断机制则是允许编译器根据上下文自动推断 Lambda 表达式的参数类型。这个推断过程包括两个方面:
- 目标类型推断
编译器会根据 Lambda 表达式在赋值、传参等地方的上下文来推断Lambda表达式的目标类型。例如,如果Lambda表达式被赋值给一个接口类型的变量,编译器会根据该接口的抽象方法来推断Lambda表达式的参数类型。
Runnable runnable = () -> System.out.println("死磕 Java 就是牛...");
Lambda表达式被赋值给了 Runnable 类型的变量,所以编译器知道 Lambda 表达式需要没有参数且返回类型为void的方法。
- 参数类型推断
如果 Lambda 表达式的参数类型可以从上下文中唯一确定,编译器会自动推断参数的类型。例如:
List<String> skList = Arrays.asList("死磕 Java 并发", "死磕 Netty", "死磕 NIO","死磕 Spring");
skList.forEach(sk -> System.out.println(sk));
forEach方法期望一个参数类型为Consumer<String>的函数,编译器可以从 sk的类型推断出Lambda表达式的参数类型为String。
虽然类型推断机制允许省略Lambda表达式的参数类型,但有时候显式声明参数类型可以增强代码的可读性和处理复杂的泛型情况,这个时候我们还是将参数类型写上会显得更加友好。
Java 8 新特性—函数式接口
在文章 Lambda 表达式 提过,Lambda 能够简化的一个依据就是函数式接口,这篇文章我们就来深入了解函数式接口。
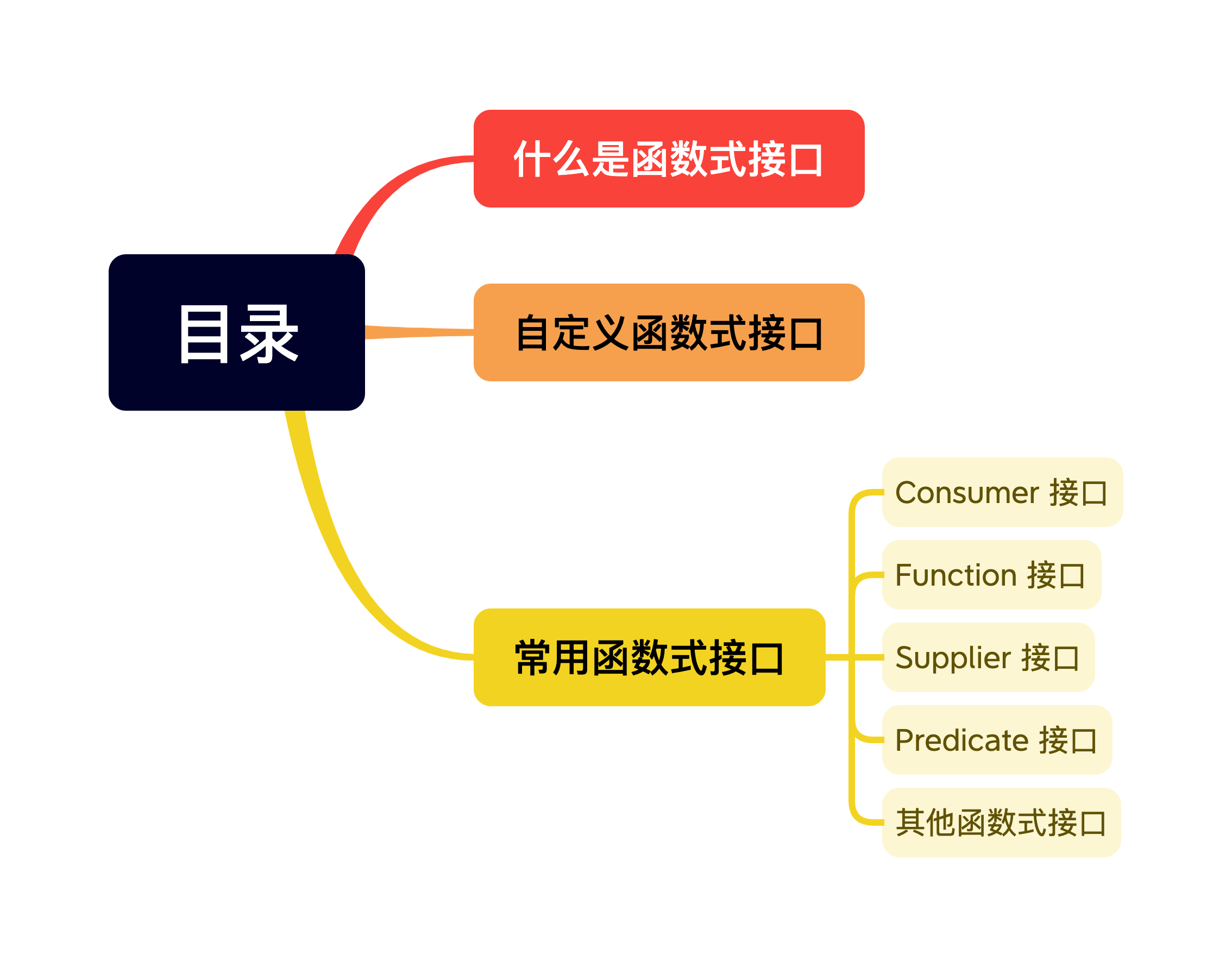
什么是函数式接口
函数式接口是一个只有一个抽象方法的接口,最开始的时候也叫做 SAM 类型的接口(Single Abstract Method)。它具有两个特点:
- 只包含一个抽象方法:函数式接口只能有一个抽象方法,但可以包含多个默认方法或静态方法。
- 用**
@FunctionalInterface**注解标记:该注解不强制,但通常会使用它来标记该接口为函数式接口。这样做可以让编译器检查接口是否符合函数式接口的定义,以避免不必要的错误。
Java 引入函数式接口的主要目的是支持函数式编程范式,也就是 Lambda 表达式。在函数式编程语言中,函数被当做一等公民对待,Lambda 表达式的类型是函数,它可以像其他数据类型一样进行传递、赋值和操作。但是在 Java 中,“一切皆对象”是不可违背的宗旨,所以 Lambda 表达式是对象,而不是函数,他们必须要依附于一类特别的对象类型:函数式接口。
所以,从本质上来说 Lambda 表达式就是一个函数式接口的实例。这就是 Lambda 表达式和函数式接口的关系。简单理解就是只要一个对象时函数式接口的实例,那么该对象就可以用 Lambda 表达式来表示。
自定义函数式接口
根据函数式接口的定义和特点,我们可以自定义函数式接口:
@FunctionalInterface
public interface FunctionInterface {
/**
* 抽象方法
*/
void doSomething();
/**
* 默认方法
* @param s
*/
default void defaultMethod(String s) {
System.out.println("默认方法:" + s);
}
/**
* 静态方法
* @param s
*/
static void staticMethod(String s) {
System.out.println("静态方法:" + s);
}
}
FunctionInterface 是一个自定义函数式接口,它只包含一个抽象方法 doSomething(),还包含一个默认方法 defaultMethod(String s) 和一个静态方法 staticMethod(String s),这两个方法都是可选的。
@FunctionalInterface 注解是可写可可不写的,但是我们一般都推荐写,写上他可以让编译器检查接口是否符合函数式接口的定义,以避免不必要的错误,比如:
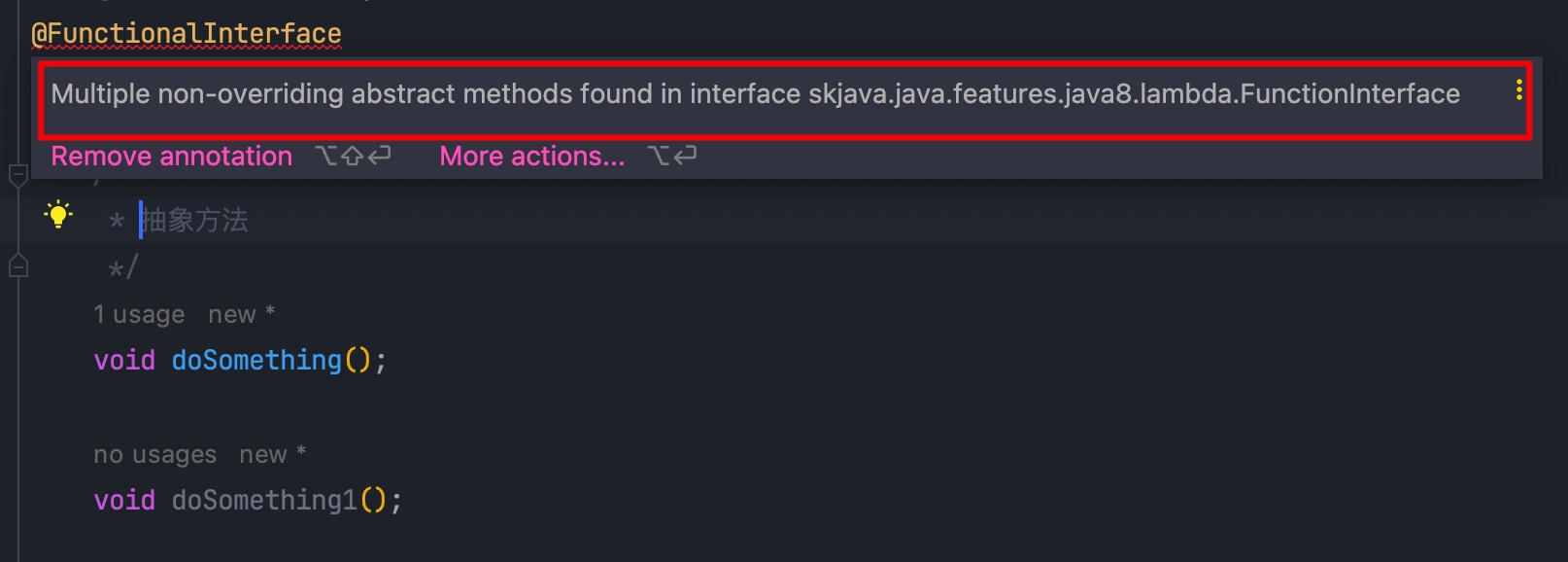
上面接口定义了两个抽象方法,它会明确告诉你错误了。
使用如下:
FunctionInterface functionInterface = () -> {
System.out.println("死磕 Java 就是牛...");
};
// 调用抽象方法
functionInterface.doSomething();
// 调用默认方法
functionInterface.defaultMethod("死磕 Netty 就是牛...");
// 调用静态方法
FunctionInterface.staticMethod("死磕 Java 并发就是牛...");
执行如下:

常用函数式接口
其实在 Java 8 之前就已经有了大量的函数式接口,我们最熟悉的就是 java.lang.Runnable接口了。Java 8 之前已有的函数式接口:
java.lang.Runnablejava.util.concurrent.Callablejava.security.PrivilegedActionjava.util.Comparatorjava.io.FileFilterjava.nio.file.PathMatcherjava.lang.reflect.InvocationHandlerjava.beans.PropertyChangeListenerjava.awt.event.ActionListenerjavax.swing.event.ChangeListener
而在 Java 8 中,新增的函数式接口都在 java.util.function 包中,里面有很多函数式接口,用来支持 Java 的函数式编程,从而丰富了 Lambda 表达式的使用场景。我们使用最多的也是最核心的函数式接口有四个:
java.util.function.Consumer:消费型接口java.util.function.Function:函数型接口java.util.function.Supplier:供给型接口java.util.function.Predicate:断定型接口
下面我们就来看这四个函数式接口的使用方法
Consumer 接口
Consumer 代表这一个接受一个输入参数并且不返回任何结果的操作。它包含一个抽象方法 accept(T t),该方法接受一个参数 t,并对该参数执行某种操作:
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
}
由于 Consumer 接口中包含的抽象方法不返回结果,所以它通常用于对对象进行一些操作,如修改、输出、打印等。它的使用方法也比较简单,分为两步。
- 创建一个 Consumer 对象:使用 Lambda 表达式来创建一个对象,定义在
accept(T t)中要执行的操作。
Consumer<String> consumer = str -> System.out.println(str);
- 使用 Consumer 对象
consumer.accept("死磕 Java 就是牛...");
// 输出结果...
死磕 Java 就是牛...
在 Consumer 接口中还有一个默认方法 andThen(),该方法接受一个 Consumer 实例对象 after,它允许我们将两个 Consumer 对象组合在一起,形成一个新的 Consumer 对象,该新对象按照顺序执行这两个 Consumer 对象的操作。先执行调用andThen()接口的accept(),然后再执行andThen()参数after中的accept()。
Consumer<String> consumer1 = str -> System.out.println("consumer1:" + str);
Consumer<String> consumer2 = str -> System.out.println("consumer2:" + str);
consumer1.andThen(consumer2).accept("死磕 Java 就是牛..");
// 输出结果...
consumer1:死磕 Java 就是牛..
consumer2:死磕 Java 就是牛..
Function 接口
Function 代表一个接受一个输入参数并且产生一个输出结果的函数。它包含一个抽象方法 R apply(T t),该方法接受一个参数 t(类型为 T),并返回一个结果(类型为 R),我们可以理解为根据一个数据类型 T ,经过一系列的操作后得到类型 R。Function 接口是非常通用的,应该是他们四个当中使用最为广泛的。
用途一:函数转换
Function 可以用于将一个类型的值转换为另一个类型的值。它可以用于各种转换操作,如类型转换、数据映射等。
Function<String,Integer> function = str -> Integer.parseInt(str);
int result = function.apply("456");
// 输出结果...
456
用途二:数据处理
Function 可用于对输入数据进行处理并生成输出结果。它可以用于执行各种操作,如过滤、计算、提取、格式化等。
Function<List<String>, String> function = list -> {
StringBuilder result = new StringBuilder();
for (String str : list) {
if (str.startsWith("李")) {
result.append(str).append(",");
}
}
return result.toString();
};
List<String> list = Arrays.asList("张三","李四","李武","李柳");
System.out.println(function.apply(list));
// 输出结果...
李四,李武,李柳,
andThen():方法链式调用
andThen() 接受一个 Function 作为参数,并返回一个新的 Function,该新函数首先应用当前函数,然后将结果传递给参数函数。这种方法链的方式可以用于将多个函数组合在一起,以执行一系列操作。
Function<String,Integer> function1 = t -> Integer.parseInt(t);
Function<Integer,Integer> function2 = t -> t * 10;
System.out.println(function1.andThen(function2).apply("20"));
先将 String 转换为 Integer,然后再 * 10,利用 andThen() 我们可以进行一系列复杂的操作。
compose():顺序执行
compose() 与 andThen()相反,它首先应用参数函数,然后再应用当前函数,这种可能更加好理解些,常用于一些顺序执行。
Function<String,Integer> function1 = t -> {
System.out.println("function1");
return Integer.parseInt(t);
};
Function<Integer,Integer> function2 = t -> {
System.out.println("function2");
return t * 10;
};
Function<Integer,String> function3 = t -> {
System.out.println("function3");
return t.toString();
};
System.out.println(function3.compose(function2.compose(function1)).apply("20"));
// 输出结果...
function1
function2
function3
200
从输出结果中可以更加直观地看清楚他们的执行顺序。
identity():恒等函数
identity() 返回一个恒等函数,它仅返回其输入值,对输入值不进行任何操作。源码如下:
static <T> Function<T, T> identity() {
return t -> t;
}
一看感觉 identity() 没啥用处,其实它在某些场景大有用处,例如
- 作为默认函数
identity() 可以作为函数组合链中的起点或默认函数。当我们想构建一个函数组合链时,可以使用 identity 作为初始函数,然后使用 andThen() 或 compose() 方法添加其他函数。这种方式允许您以一种优雅的方式处理链的起点。
Function<String,String> function1 = Function.identity();
Function<String,String> function2 = str -> str.toUpperCase();
Function<String,String> function3 = str -> str + " WORLD!!!";
System.out.println(function3.compose(function2.compose(function1)).apply("hello"));
- 保持一致性
在某些情况下,我们可能需要一个函数,但不需要对输入进行任何操作。使用 identity() 可以确保函数的签名(输入和输出类型)与其他函数一致。
Supplier 接口
Supplier 是一个代表生产(或供应)某种结果的接口,它不接受任何参数,但能够提供一个结果。它定义了一个 get() 的抽象方法,用于获取结果。
接口定义简单,使用也简单:
Supplier<LocalDate> supplier = () -> LocalDate.now();
LocalDate localDate = supplier.get();
Supplier 接口通常用于惰性求值,只有在需要结果的时候才会执行 get() 。这对于延迟计算和性能优化非常有用。
Predicate 接口
Predicate 表示一个谓词,它接受一个输入参数并返回一个布尔值,用于表示某个条件是否满足。抽象方法为 test(),使用如下:
Predicate<String> predicate = str -> str.length() > 10;
boolean result = predicate.test("www.skjava.com");
判断某个字符长度是否大于 10。
and():表示两个 Predicate 的 与操作
Predicate<Integer> predicate1 = x -> x > 10;
Predicate<Integer> predicate2 = x -> x % 2 == 0;
boolean result = predicate1.and(predicate2).test(13);
or():表示两个 Predicate 的或操作
Predicate<Integer> predicate1 = x -> x > 10;
Predicate<Integer> predicate2 = x -> x % 2 == 0;
boolean result = predicate1.or(predicate2).test(13);
negate():表示 Predicate 的逻辑非操作
Predicate<Integer> predicate1 = x -> x > 10;
boolean result = predicate1.negate().test(14);
其他函数式接口
除了上面四个常用的函数式接口外,java.util.function 包下面还定义了很多函数式接口,下面做一个简单的介绍:
| 接口 | 说明 |
|---|---|
| BiConsumer<T,U> | 表示接受两个不同类型的参数,但不返回任何结果的操作 |
| BiFunction<T,U,R> | 表示接受两个不同类型的参数,并返回一个其它类型的结果的操作 |
| BinaryOperator | 表示接受两个相同类型的参数,并返回一个同一类型的结果的操作 |
| BiPredicate<T,U> | 表示接受两个不同诶行的参数,且返回布尔类型的结果的操作 |
| BooleanSupplier | 不接受任何参数,且返回一个布尔类型的结果的操作 |
| DoubleBinaryOperator | 表示接受两个double类型的参数,并返回double类型结果的操作 |
| DoubleConsumer | 表示接受一个double类型的参数,但不返回任何结果的操作 |
| DoubleFunction | 表示接受一个double类型的参数,且返回一个R类型的结果的操作 |
| DoublePredicate | 表示一个接受两个double类型的参数,且返回一个布尔类型的结果的操作 |
| DoubleSupplier | 表示一个不接受任何参数,但返回布尔类型的结果的操作 |
| DoubleToIntFunction | 表示接受两个double类型的参数,但返回一个int类型的结果的操作 |
| DoubleToLongFunction | 表示接受两个double类型的参数,但返回一个long类型的结果的操作 |
| DoubleUnaryOperator | 表示接受一个double类型的参数,且返回一个double类型的结果的操作 |
| IntBinaryOperator | 表示一个接受两个int类型的参数,且返回一个int类型的结果的操作 |
| IntConsumer | 表示接受一个int类型的参数,但不返回任何结果的操作 |
| IntFunction | 表示接受一个int类型的参数,但返回一个R类型的结果的操作 |
| IntPredicate | 表示接受一个int类型的参数,但返回布尔类型的结果的操作 |
| IntSupplier | 表示不接受任何参数,但返回一个int类型的结果的操作 |
| IntToDoubleFunction | 表示接受一个int类型的参数,但返回一个double类型的结果的操作 |
| IntToLongFunction | 表示接受一个int类型的参数,但返回一个long类型的结果的操作 |
| IntUnaryOperator | 表示接受一个int类型的参数,且返回一个int类型的结果的操作 |
| LongBinaryOperator | 表示接受两个long类型的参数,且返回一个long类型的结果的操作 |
| LongConsumer | 表示不接受任何参数,但返回一个long类型的结果的操作 |
| LongFunction | 表示接受一个loing类型的参数,但返回一个R类型的结果的操作 |
| LongPredicate | 表示接受一个long类型的参数,但返回布尔类型的结果的操作 |
| LongSupplier | 表示不接受任何参数,但返回一个long类型的结果的操作 |
| LongToDoubleFunction | 表示接受一个long类型的参数,但返回一个double类型的结果的函数 |
| LongToIntFunction | 表示接受一个long类型的参数,但返回int类型的结果的函数 |
| LongUnaryOperator | 表示接受一个long类型的参数,并返回一个long类型的结果的操作 |
| ObjDoubleConsumer | 表示接受两个参数,一个为T类型的对象,另一个double类型,但不返回任何结果的操作 |
| ObjIntConsumer | 表示接受两个参数,一个为T类型的对象,另一个int类型,但不返回任何结果的操作 |
| ObjLongConsumer | 表示接受两个参数,一个为T类型的对象,另一个double类型,但不返回任何结果的操作 |
| ToDoubleBiFunction<T,U> | 表示接受两个不同类型的参数,但返回一个double类型的结果的操作 |
| ToDoubleFunction | 表示一个接受指定类型T的参数,并返回一个double类型的结果的操作 |
| ToIntBiFunction<T,U> | 表示接受两个不同类型的参数,但返回一个int类型的结果的操作 |
| ToIntFunction | 表示一个接受指定类型T的参数,并返回一个int类型的结果的操作 |
| ToLongBiFunction<T,U> | 表示接受两个不同类型的参数,但返回一个long类型的结果的操作 |
| ToLongFunction | 表示一个接受指定类型的参数,并返回一个long类型的结果的操作 |
| UnaryOperator | 表示接受一个参数,并返回一个与参数类型相同的结果的操作 |
函数式接口使用非常灵活,上面的举例都是很简单的 demo,它需要我们在日常开发过程中多多使用才能灵活地运用它。
Java 8 新特性—方法引用和构造器引用
在前面我们了解了 Lambda 表达式,它能够简化我们的程序,但是它还不是最简单的,Java 8 引入了方法引用可以对 Lambda 表达式再进一步简化。
什么是方法引用
我们先看一个例子。首先定义一个 Student 类:
public class Student {
private String name;
private Integer age;
public static int compareByAge(Student a,Student b) {
return a.getAge().compareTo(b.getAge());
}
}
Student 中含有一个静态方法 compareByAge(),它是用来比较年龄的。
现在需要实现一个需求,有一批学生我们希望能够根据 age 进行排序。
在没有学习 Lambda 表达式时,我们这样写:
public class MethodReferenceTest {
public static void main(String[] args) {
List<Student> studentList = Arrays.asList(
new Student("小明",16),
new Student("小红",14),
new Student("小兰",15),
new Student("小李",18),
new Student("小张",14),
new Student("小林",15)
);
Collections.sort(studentList, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge().compareTo(o2.getAge());
}
});
System.out.println(studentList);
}
}
学习了 Lambda 表达式后,我们知道 Comparator 接口是一个函数式接口,因此我们可以使用Lambda表达式,而不需要使用这种匿名内部类的方式:
public class MethodReferenceTest {
public static void main(String[] args) {
// 省略代码...
Collections.sort(studentList, (o1,o2) -> Student.compareByAge(o1,o2));
System.out.println(studentList);
}
}
注意,这里我们是使用 Student 类中的静态方法:compareByAge()。到这里后其实还有进一步的优化空间:
public class MethodReferenceTest {
public static void main(String[] args) {
// 省略代码...
Collections.sort(studentList, Student::compareByAge);
System.out.println(studentList);
}
}
这段代码将 Lambda 表达式 (o1,o2) -> Student.compareByAge(o1,o2) 转变为了 Student::compareByAge 是不是很懵逼?
Student::compareByAge 写法就是我们这篇文章要讲的方法引用。那什么是方法引用呢?
方法引用是 Java 8 引入的特性,它提供了一种更加简洁的可用作 Lambda 表达式的表达方式。 定义:方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。
我们可以简单认为,方法引用是一种更加简洁易懂的 Lambda表达式。当 Lambda 表达式的主体中只有一个执行方法的调用时,我们可以不使用 Lambda 表达式,而是选择更加简洁的方法引用,这样可读性更高一些。
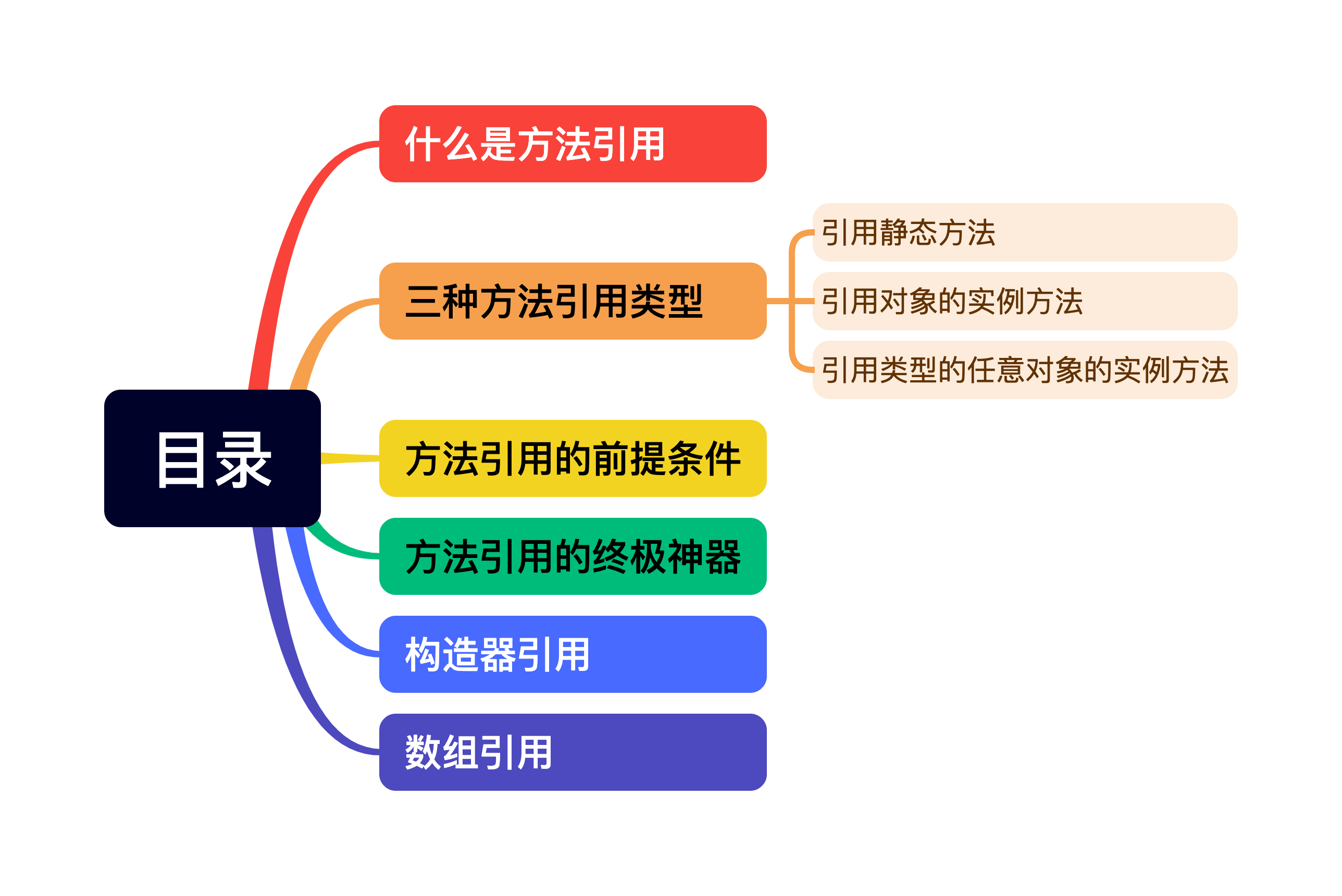
三种方法引用类型
方法引用的标准格式是:类名::方法名。它有如下三种类型:
| 类型 | 格式 |
|---|---|
| 引用静态方法 | 类名::静态方法名 |
| 引用对象的实例方法 | 实例对象::方法名 |
| 引用类型的任意对象的实例方法 | 类名::实例方法名 |
下面我们来看这三种类型的使用方法。
引用静态方法
引用静态方法的格式是:类名::静态方法名。这个是其实和我们使用静态方法一样,只不过是将 “.” 替换成了 “::”。其实我们上面那个例子就是引用静态方法的例子,这里大明哥再举一个示例,java.lang.Math 中有很多静态方法,比如:
// Lambda 表达式
Function<Integer,Integer> function1 = t -> Math.abs(t);
int result1 = function1.apply(-123);
// 方法引用
Function<Integer,Integer> function2 = Math::abs;
int result2 = function2.apply(-123);
引用对象的实例方法
引用对象的实力方法格式是:实例对象名::实例方法名,这种方式引用的是一个实例方法,所以需要提供一个对象实例来引用,如下:
Student student = new Student("小明",15);
// Lambda 表达式
Supplier<String> supplier1 = () -> student.getName();
String name1 = supplier1.get();
// 方法引用
Supplier<String> supplier2 = student::getName;
String name2 = supplier2.get();
这种方式在我们使用 Stream 来操作集合时用得非常多。
引用类型的任意对象的实例方法
引用类型的任意对象的实例方法的格式是:类名::实例方法名,这个有点儿不是很好理解。这种引用方式引用的是一个特定对象的实例方法,通常在函数式接口中作为第一个参数传递给方法引用,怎么理解呢?我们看下面两个例子:
比如 Comparator 中的 int compare(T o1, T o2),我们需要比较两个字符串的大小,使用方式如下:
Comparator<String> comparator = (o1,o2) -> o1.compareTo(o2);
System.out.println(comparator.compare("sike","sk"));
改成 类名::实例方法名 怎么改呢?
Comparator<String> comparator = String::compareTo;
System.out.println(comparator.compare("sike","sk"));
是不是比较懵逼?再看一个:
// Lambda 表达式
List<String> list = Arrays.asList("xiaoming","xiaohong","xiaoli","xiaodu");
list.forEach(name -> name.toUpperCase());
// 方法引用
List<String> list = Arrays.asList("xiaoming","xiaohong","xiaoli","xiaodu");
list.forEach(String::toUpperCase);
是不是比较懵?其实大明哥看到这个也比较懵,确实是不好理解,但是没关系,最后面大明哥教你们一个终极神器,让你使用方法引用不再困难。
方法引用的前提条件
方法引用确实可以极大地降低我们的代码量也更加清晰了,但是并不是所有的 Lambda 表达式都可以转换为方法引用。它有如下几个前提条件。
1、Lambda 表达式中只有一个调用方法的代码
注意这个一个调用方法的含义,它包含两重意思。
- 只有一行代码
List<String> list = Arrays.asList("xiaoming","xiaohong","xiaoli","xiaodu");
list.forEach(name -> {
System.out.println("www.skjava.com");
name.toUpperCase();
});
这个 Lambda 中有两行代码,这是无法转换为方法引用的。
- 只有一个调用方法
List<String> list = Arrays.asList("xiaoming","xiaohong","xiaoli","xiaodu");
list.forEach(name -> System.out.println(name.toUpperCase()));
这种写法也是转换不了的,虽然只有一行代码,但是它调用了两个方法。
2、方法引用的目标方法必须与Lambda 表达式的函数接口的抽象方法参数类型和返回类型相匹配
这就意味着目标方法的参数数量、类型以及返回类型必须与函数接口的要求一致。但是它只能规范引用静态方法和引用对象的实例方法,而引用类型的任意对象的实例方法这种类型其实是不适用。
3、如果方法引用是通过对象引用来实现的,那么 Lambda 表达式中的参数列表的第一个参数必须是方法引用的目标方法的隐式参数,而其余参数(如果有的话)必须与方法引用的目标方法的参数一致。
比如:
BiConsumer<Student,Integer> consumer = (stu,age) -> stu.setAge(age);
改成
BiConsumer<Student,Integer> consumer = Student::setAge;
Lambda 表达式有两个参数 (stu,age),第一个参数 stu 是目标方法 setAge() 的隐式参数,其余参数 (age)与方法引用的目标方法 (setAge(Integer age) )的参数 (Integer age) 是一致的。这种就可以改写。
又如:
Comparator<String> comparator = (o1,o2) -> o1.compareTo(o2);
改为
Comparator<String> comparator = String::compareTo;
方法引用简单是简单,就是不好理解,尤其是 类名::实例方法 格式的,直接会让人懵逼,还有我们有终极神器。
方法引用的终极神器
这个终极神器其实就是 idea。idea 不管是对于 Lambda 表达式还是方法引用其实都是有提示的,例如:
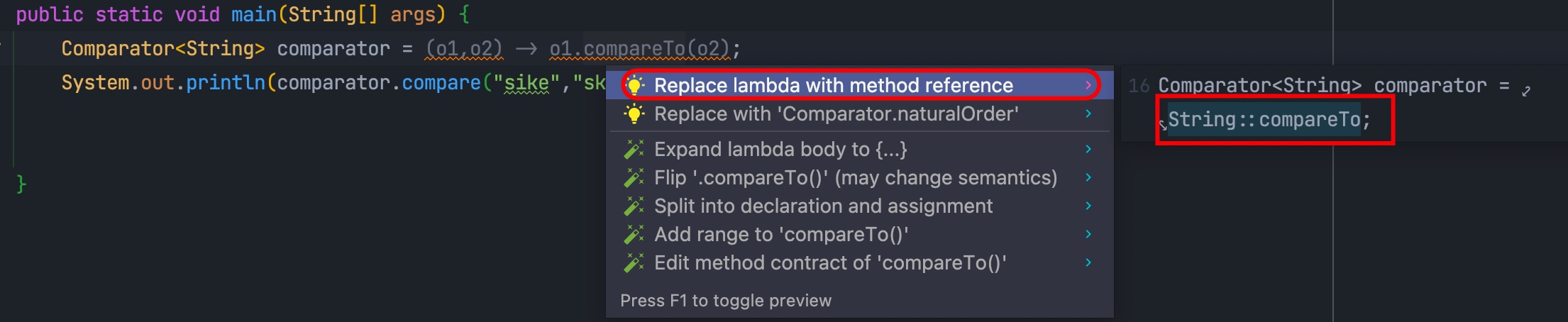
idea 会直接提示你该 Lambda 表达式可以简化为 String::compareTo,是不是很给力。再如:

直接提示你可以简化为 Lambda 表达式。所以工欲善其事必先利其器。
构造器引用
构造器引用提供了一种更加简介的方式来创建对象,语法格式是 :类::new。调用哪个构造器取决于函数式接口中的方法形参的定义,Lambda 表达式会自动根据接口方法推断出你要调用的构造器。
- 调用无参构造器
// Lambda 表达式
Supplier<Student> supplier = () -> new Student();
// 方法引用
Supplier<Student> supplier = Student::new;
- 调用有参构造器
例如:
// Lambda 表达式
Function<String,Student> function = name -> new Student(name);
// 方法引用
Function<String,Student> function = Student::new;
这个是调用的构造器为:
public Student(String name) {
this.name = name;
}
再如:
// Lambda 表达式
BiFunction<String,Integer,Student> function = (name,age) -> new Student(name,age);
// 方法引用
BiFunction<String,Integer,Student> function = Student::new;
到这里各位小伙伴应该明白是怎么回事了吧?但是这里有一个漏洞,因为 Function 只有一个参数,所以它只支持带有一个参数的构造器,BiFunction 有两个参数,所以它只支持带有两个参数的构造器,如果我的 Student 有四个属性呢?怎么办?自定义函数式接口。
@Data
@AllArgsConstructor
public class Student {
private String name;
private Integer age;
private String birthday;
private String className;
}
我们需要自定义一个函数式接口,它需要有四个参数,一个返回值,如下:
@FunctionalInterface
public interface FunctionInterface<T,U,O,P,R> {
R apply(T t, U u,O o,P p);
}
然后就可以利用构造器引用来构造 Student 对象了:
FunctionInterface<String,Integer,String,String,Student> functionInterface = Student::new;
System.out.println(functionInterface.apply("xiaoming",8,"06-19","二年三班"));
这种方式确实是简单了,但是没有必要为了多个参数来自定义一个函数式接口。在实际项目过程中我觉得还不如 new Student 来的直接明了。
数组引用
数组引用和构造器引用的语法格式一样,Type[]::new。Type 是数组元素的类型,后面的::new表示引用该类型的数组构造方法来创建新数组。例如:
Function<Integer, int[]> function = int[]::new;
int[] arrays = function.apply(5);
创建一个包含5个整数的一维数组。对于多维数组,大明哥其实不是很建议使用这种方式,因为有点儿鸡肋,多维的数组内容还是需要我们处理。
Java 8 新特性—Optional
NullPointerException 是我们最常见也是最烦的异常处理,它非常常见,处理起来有很简单,但是你又不得不去处理,超级烦。
引言
我们先看一个简单的例子:
@Data
public class User {
private String name;
private Address address;
}
@Data
public class Address {
private String province;
private String city;
private String area;
}
如果我们需要获取用户所在城市,我们会这么写:
public static String getUserCity(User user) {
return user.getAddress().getCity();
}
String city = getUserCity(user);
这种写法有可能会报 NullPointerException,因为 user 可能为 null,user.getAddress() 也有可能为 null,所以为了解决这个问题 ,我们会采用这种写法:
public static String getUserCity(User user) {
if (user != null) {
Address address = user.getAddress();
if (address != null) {
return address.getCity();
}
}
return null;
}
就问这种写法丑不丑?繁琐不繁琐?为了避免这种丑陋的写法,让丑陋的设计变得优雅,Java 8 提供了 Optional。
Optional 是什么
Optional 是 Java 8 提供了一个类库。被设计出来的目的是为了减少因为null而引发的NullPointerException异常,并提供更安全和优雅的处理方式。
Java 中臭名昭著的 NullPointerException 是导致 Java 应用程序失败最常见的原因,没有之一,没有一个 Java 开发程序员没有遇到这个异常。为了解决 NullPointerException,Google Guava 引入了 Optional 类,它提供了一种在处理可能为null值时更灵活和优雅的方式,受 Google Guava 的影响,Java 8 引入 Optional 来处理 null 值。
在 Javadoc 中是这样描述它的:一个可以为 null 的容器对象。所以 java.util.Optional<T> 是一个容器类,它可以保存类型为 T 的值,T 可以是实际 Java 对象,也可以是 null。
API 介绍
我们先看 Optional 的定义:
public final class Optional<T> {
/**
* 如果非空,则为该值;如果为空,则表示没有值存在。
*/
private final T value;
//...
}
从这里可以看出,Optional 的本质就是内部存储了一个真实的值 T,如果 T 非空,就为该值,如果为空,则表示该值不存在。
构造 Optional 对象
Optional 的构造函数是 private 权限的,它对外提供了三个方法用于构造 Optional 对象。
Optional.of(T value)
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
private Optional(T value) {
this.value = Objects.requireNonNull(value);
}
所以 Optional.of(T value) 是创建一个包含非null值的 Optional 对象。如果传入的值为null,将抛出NullPointerException 异常信息。
Optional.ofNullable(T value)
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
创建一个包含可能为null值的Optional对象。如果传入的值为null,则会创建一个空的Optional对象。
Optional.empty()
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
private static final Optional<?> EMPTY = new Optional<>();
创建一个空的Optional对象,表示没有值。
检查是否有值
Optional 提供了两个方法用来检查是否有值。
isPresent()
isPresent() 用于检查Optional对象是否包含一个非null值,源码如下:
public boolean isPresent() {
return value != null;
}
示例如下:
User user = null;
Optional<User> optional = Optional.ofNullable(user);
System.out.println(optional.isPresent());
// 结果......
false
ifPresent(Consumer<? super T> action)
该方法用来执行一个操作,该操作只有在 Optional 包含非null值时才会执行。源码如下:
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
需要注意的是,这是 Consumer,是没有返回值的。
示例如下:
User user = new User("xiaoming");
Optional.ofNullable(user).ifPresent(value-> System.out.println("名字是:" + value.getName()));
获取值
获取值是 Optional 中的核心 API,Optional 为该功能提供了四个方法。
get()
get() 用来获取 Optional 对象中的值。如果 Optional 对象的值为空,会抛出NoSuchElementException异常。源码如下:
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
orElse(T other)
orElse() 用来获取 Optional 对象中的值,如果值为空,则返回指定的默认值。源码如下:
public T orElse(T other) {
return value != null ? value : other;
}
示例如下:
User user = null;
user = Optional.ofNullable(user).orElse(new User("xiaohong"));
System.out.println(user);
// 结果......
User(name=xiaohong, address=null)
orElseGet(Supplier<? extends T> other)
orElseGet()用来获取 Optional 对象中的值,如果值为空,则通过 Supplier 提供的逻辑来生成默认值。源码如下:
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
示例如下:
User user = null;
user = Optional.ofNullable(user).orElseGet(() -> {
Address address = new Address("湖南省","长沙市","岳麓区");
return new User("xiaohong",address);
});
System.out.println(user);
// 结果......
User(name=xiaohong, address=Address(province=湖南省, city=长沙市, area=岳麓区))
orElseGet() 和 orElse()的区别是:当 T 不为 null 的时候,orElse() 依然执行 other 的部分代码,而 orElseGet() 不会,验证如下:
public class OptionalTest {
public static void main(String[] args) {
User user = new User("xiaoming");
User user1 = Optional.ofNullable(user).orElse(createUser());
System.out.println(user);
System.out.println("=========================");
User user2 = Optional.ofNullable(user).orElseGet(() -> createUser());
System.out.println(user2);
}
public static User createUser() {
System.out.println("执行了 createUser() 方法");
Address address = new Address("湖南省","长沙市","岳麓区");
return new User("xiaohong",address);
}
}
执行结果如下:

是不是 orElse() 执行了 createUser() ,而 orElseGet() 没有执行?一般而言,orElseGet() 比 orElse() 会更加灵活些。
orElseThrow(Supplier<? extends X> exceptionSupplier)
orElseThrow() 用来获取 Optional 对象中的值,如果值为空,则通过 Supplier 提供的逻辑抛出异常。源码如下:
public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
if (value != null) {
return value;
} else {
throw exceptionSupplier.get();
}
}
示例如下:
User user = null;
user = Optional.ofNullable(user).orElseThrow(() -> new RuntimeException("用户不存在"));
类型转换
Optional 提供 map() 和 flatMap() 用来进行类型转换。
map(Function<? super T, ? extends U> mapper)
map() 允许我们对 Optional 对象中的值进行转换,并将结果包装在一个新的 Optional 对象中。该方法接受一个 Function 函数,该函数将当前 Optional 对象中的值映射成另一种类型的值,并返回一个新的 Optional 对应,这个新的 Optional 对象中的值就是映射后的值。如果当前 Optional 对象的值为空,则返回一个空的 Optional 对象,且 Function 不会执行,源码如下:
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
比如我们要获取 User 对象中的 name,如下:
User user = new User("xiaolan");
String name = Optional.ofNullable(user).map(value -> value.getName()).get();
System.out.println(name);
// 结果......
xiaolan
Function<? super T, Optional<U>> mapper
flatMap() 与 map() 相似,不同之处在于 flatMap()的映射函数返回的是一个 Optional 对象而不是直接的值,它是将当前 Optional 对象映射为另外一个 Optional 对象。
public<U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Objects.requireNonNull(mapper.apply(value));
}
}
上面获取 name 的代码如下:
String name = Optional.ofNullable(user).flatMap(value -> Optional.ofNullable(value.getName())).get();
flatMap() 内部需要再次封装一个 Optional 对象,所以 flatMap() 通常用于在一系列操作中处理嵌套的Optional对象,以避免层层嵌套的情况,使代码更加清晰和简洁。
过滤
Optional 提供了 filter() 用于在 Optional 对象中的值满足特定条件时进行过滤操作,源码如下:
public Optional<T> filter(Predicate<? super T> predicate) {
Objects.requireNonNull(predicate);
if (!isPresent())
return this;
else
return predicate.test(value) ? this : empty();
}
filter() 接受 一个Predicate 来对 Optional 中包含的值进行过滤,如果满足条件,那么还是返回这个 Optional;否则返回 Optional.empty。
实战应用
这里大明哥利用 Optional 的 API 举几个例子。
- 示例一
Java 8 以前:
public static String getUserCity(User user) {
if (user != null) {
Address address = user.getAddress();
if (address != null) {
return address.getCity();
}
}
return null;
}
常规点的,笨点的方法:
public static String getUserCity(User user) {
Optional<User> userOptional = Optional.of(user);
return Optional.of(userOptional.get().getAddress()).get().getCity();
}
高级一点的:
public static String getUserCity(User user) {
return Optional.ofNullable(user)
.map(User::getAddress)
.map(Address::getCity)
.orElseThrow(() -> new RuntimeException("值不存在"));
}
是不是比上面高级多了?
- 示例二
比如我们要获取末尾为"ming"的用户的 city,不是的统一返回 "深圳市"。
Java 8 以前
public static String getUserCity(User user) {
if (user != null && user.getName() != null) {
if (user.getName().endsWith("ming")) {
Address address = user.getAddress();
if (address != null) {
return address.getCity();
} else {
return "深圳市";
}
} else {
return "深圳市";
}
}
return "深圳市";
}
Java 8
public static String getUserCity2(User user) {
return Optional.ofNullable(user)
.filter(u -> u.getName().endsWith("ming"))
.map(User::getAddress)
.map(Address::getCity)
.orElse("深圳市1");
}
这种写法确实是优雅了很多。其余的例子大明哥就不一一举例了,这个也没有其他技巧,唯手熟尔!!
Java 8 新特性—日期时间 API
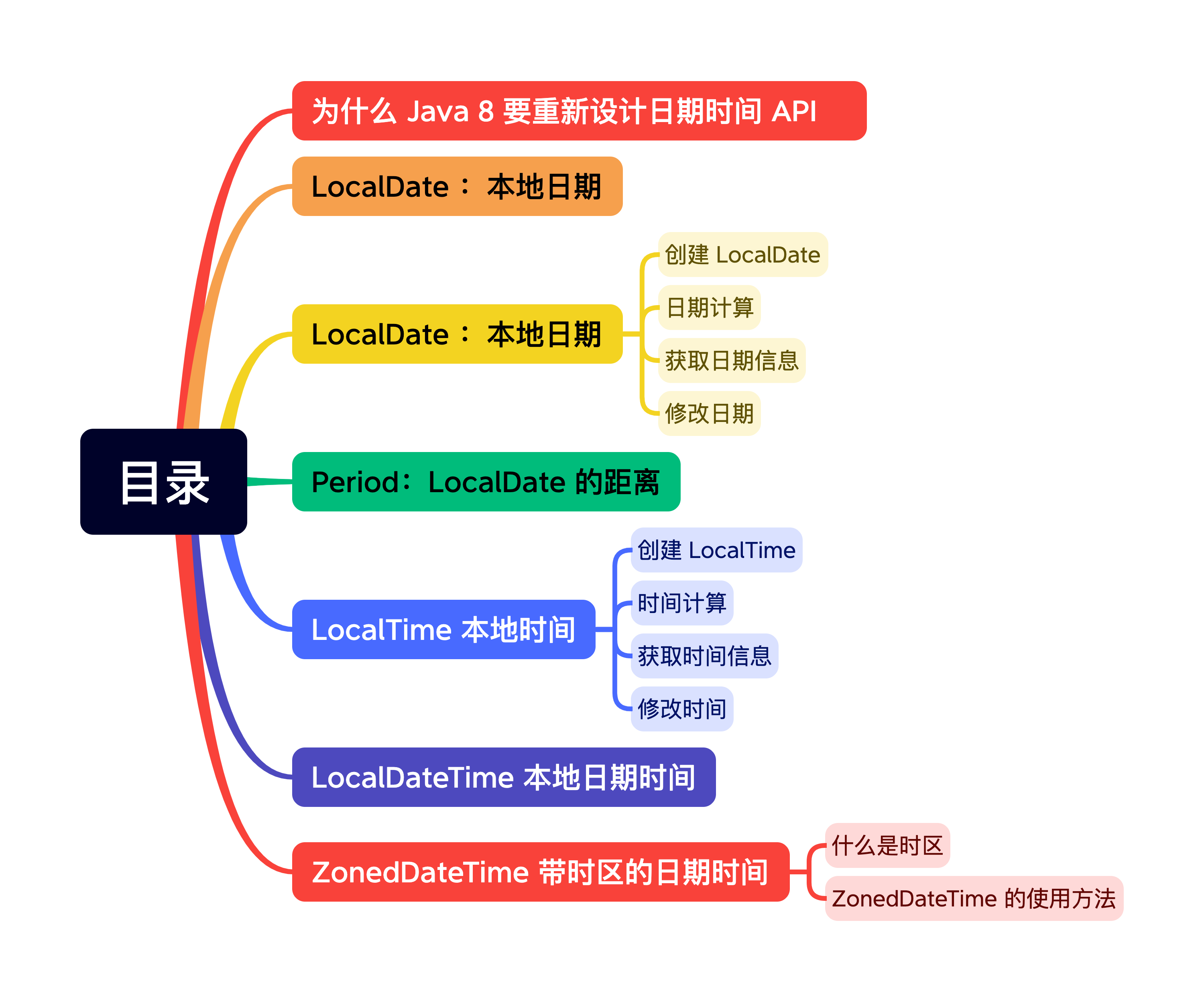
为什么 Java 8 要重新设计日期时间 API
作为 Java 开发者你一定直接或者间接使用过 java.util.Date 、java.util.Calendar、java.text.SimpleDateFormat 这三个类吧,这三个类是 Java 用于处理日期、日历、日期时间格式化的。由于他们存在一些问题,诸如:
线程不安全
:
java.util.Date和java.util.Calendar线程不安全,这就导致我们在多线程环境使用需要额外注意。java.text.SimpleDateFormat也是线程不安全的,这可能导致性能问题和日期格式化错误。而且它的模式字符串容易出错,且不够直观。
可变性:
java.util.Date类是可变的,这意味着我们可以随时修改它,如果一不小心就会导致数据不一致问题。时区处理困难:Java 8 版本以前的日期 API 在时区处理上存在问题,例如时区转换和夏令时处理不够灵活和准确。而且时区信息在
Date对象中存储不明确,这使得正确处理时区变得复杂。设计不佳
:
- 日期和日期格式化分布在多个包中。
java.util.Date的默认日期,年竟然是从 1900 开始,月从 1 开始,日从 1 开始,没有统一性。而且java.util.Date类也缺少直接操作日期的相关方法。- 日期和时间处理通常需要大量的样板代码,使得代码变得冗长和难以维护。
基于上述原因,Java 8 重新设计了日期时间 API,以提供更好的性能、可读性和可用性,同时解决了这些问题,使得在 Java 中处理日期和时间变得更加方便和可靠。相比 Java 8 之前的版本,Java 8 版本的日期时间 API 具有如下几个优点:
- 不可变性(Immutability):Java 8的日期时间类(如
LocalDate、LocalTime和LocalDateTime)都是不可变的,一旦创建就不能被修改。这确保了线程安全,避免了并发问题。 - 清晰的API设计:Java 8 的日期时间 API 采用了更清晰、更一致的设计,相比于以前版本的
Date和Calendar更易于理解和使用。而且它们还提供了丰富的方法来执行日期和时间的各种操作,如加减、比较、格式化等。 - 本地化支持:Java 8 的日期时间 API 支持本地化,可以轻松处理不同地区和语言的日期和时间格式。它们能够自动适应不同的时区和夏令时规则。
- 新的时区处理:Java 8引入了
ZoneId和ZoneOffset等新的时区类,使时区处理更加精确和灵活。这有助于解决以前版本中时区处理的问题。 - 新的格式化API:Java 8引入了
DateTimeFormatter类,用于格式化和解析日期和时间,支持自定义格式和本地化。这提供了更强大和灵活的格式化选项。 - 更好的性能:Java 8 的日期时间API 比以前的API 性能更佳。
Instant:时间点
Instant 用于表示时间线上的点,即一个瞬间。它是不可变的,以纳秒为单位精确表示时间,可以用于在不考虑时区的情况下进行时间的计算和比较。
Instant 参考点是标准的 Java 纪元(epoch),即1970-01-01T00:00:00Z(1970年1月1日00:00 GMT)。 Instant 类的 EPOCH 属性返回表示 Java 纪元的 Instant 实例。 在纪元之后的时间是正值,而在此之前的时间即是负值。
- 使用
Instant.now()创建当前的时间点:
Instant now = Instant.now();
getEpochSecond() 返回自纪元以来经过的秒数。 getNano() 返回自上一秒开始以来的纳秒数。
- 从
java.util.Date或java.util.Calendar转换为Instant
Instant instant = new Date().toInstant();
Instant 在以下场景特别有用:
- 计算事件发生的时间戳,无论时区如何。
- 进行时间计算,如计算时间差、定时任务等。
例如:
public class InstantTest {
@test
public void test() {
Instant start = Instant.now();
// do something here
Instant end = Instant.now();
System.out.println(Duration.between(start, end).toMillis());
}
}
LocalDate :本地日期
LocalDate 用于表示不包含时间信息的日期。它是不可变的。
创建 LocalDate
Java 提供了三种方式用来创建一个 LocalDate 对象。
- 使用
LocalDate.now()方法创建当前日期
LocalDate currentDate = LocalDate.now();
- 使用 LocalDate.of() 来创建指定年、月、日的 LocalDate 对象
LocalDate date = LocalDate.of(2023, 10, 8)
- 使用 DateTimeFormatter 解析一个 LocalDate 对象
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate parsedDate = LocalDate.parse("2023-10-08", formatter);
日期计算
LocalDate 提供了 plus 和 minus 类方法用于在日期上增加或者减少一定数量的年、月、日:
plusYears()、plusMonths()和plusDays():分别用于在日期上增加年、月和日。minusYears()、minusMonths()和minusDays():分别用于从日期中减去年、月和日。
这 6 个方法都是返回一个新的 LocalDate 对象,原始 LocalDate 对象不受影响。
@test
public void test() {
LocalDate localDate = LocalDate.now();
LocalDate plusYears = localDate.plusYears(1);
LocalDate plusMonths = localDate.plusMonths(1);
LocalDate plusDays = localDate.plusDays(1);
LocalDate minusYears = localDate.minusYears(1);
LocalDate minusMonths = localDate.minusMonths(1);
LocalDate minusDays = localDate.minusDays(1);
System.out.println("原始 LocalDate:" + localDate);
System.out.println("plusYears(1):" + plusYears);
System.out.println("plusMonths(1):" + plusMonths);
System.out.println("plusDays(1):" + plusDays);
System.out.println("minusYears(1):" + minusYears);
System.out.println("minusMonths(1):" + minusMonths);
System.out.println("minusDays(1):" + minusDays);
}
// 结果......
原始 LocalDate:2023-10-08
plusYears(1):2024-10-08
plusMonths(1):2023-11-08
plusDays(1):2023-10-09
minusYears(1):2022-10-08
minusMonths(1):2023-09-08
minusDays(1):2023-10-07
获取日期信息
LocalDate 提供了 get 类方法用于获取日期信息:
getYear():获取年份。getMonth():获取月份(返回Month枚举类型)。getDayOfMonth():获取月中的天数。getDayOfWeek():获取星期几(返回DayOfWeek枚举类型)。
@Test
public void test() {
LocalDate localDate = LocalDate.now();
System.out.println("getYear():" + localDate.getYear());
System.out.println("getMonthValue():" + localDate.getMonthValue());
System.out.println("getDayOfMonth():" + localDate.getDayOfMonth());
System.out.println("getDayOfWeek():" + localDate.getDayOfWeek());
}
// 结果......
getYear():2023
getMonthValue():10
getDayOfMonth():8
getDayOfWeek():SUNDAY
修改日期
LocalDate 提供了 with 类方法用于修改 LocalDate 对象,它返回的也是一个新的 LocalDate 对象。
withDayOfMonth():修改月中的天数字段withMonth():修改月份字段withYear():修改年份字段
@Test
public void test() {
LocalDate localDate = LocalDate.now();
LocalDate withYear = localDate.withYear(2022);
LocalDate withMonth = localDate.withMonth(12);
LocalDate withDayOfMonth = localDate.withDayOfMonth(22);
System.out.println("原始 localDate:" + localDate);
System.out.println("withYear(2022):" + withYear);
System.out.println("withMonth(12):" + withMonth);
System.out.println("withDayOfMonth(22):" + withDayOfMonth);
}
// 结果......
原始 localDate:2023-10-08
withYear(2022):2022-10-08
withMonth(12):2023-12-08
withDayOfMonth(22):2023-10-22
设置的值的时候注意时间范围,你别 withDayOfMonth(99) 肯定报异常。
Period:LocalDate 的距离
Period 是用于处理日期间隔的类,通常用于计算两个日期之间的间隔,如天数、月数和年数。
Period.of() 用于创建一个表示日期间隔的 Period 对象,该方法接受三个参数:年、月、日:
Period period = Period.of(5,10,8);
同时,Period 也提供了对应的 get 方法用于获取间隔的年、月、日,对应的方法分别为 getYears()、getMonths()、getDays():
@Test
public void test() {
Period period = Period.of(5,10,8);
int years = period.getYears();
int months = period.getMonths();
int days = period.getDays();
}
Period 提供的 between() 用于计算两个日期之间的间隔:
@Test
public void test() {
LocalDate begin = LocalDate.of(2023,10,8);
LocalDate end = LocalDate.of(2025,9,12);
Period period = Period.between(begin,end);
System.out.println("years:" + period.getYears());
System.out.println("getMonths:" + period.getMonths());
System.out.println("getDays:" + period.getDays());
}
// 结果......
years:1
getMonths:11
getDays:4
Period.between() 返回的是一个 Period 对象,我们可以利用对应的 get 方法获取相应的数据。
LocalTime 本地时间
LocalTime 用于不包含日期信息的时间,它只表示一天中的时间。
创建 LocalTime
LocalTime 提供了四种方式来创建 LocalTime 对象。
LocalTime.now():获取当前系统时间。
LocalTime localTime = LocalTime.now(); //11:44:47.123
LocalTime.of(int hour, int minute):创建指定的小时和分钟的时间
LocalTime localTime = LocalTime.of(12,46); //12:46
LocalTime.of(int hour, int minute, int second):创建指定的小时、分钟和秒的时间。
LocalTime localTime = LocalTime.of(12,46,50); //12:46:50
LocalTime.of(int hour, int minute, int second, int nanoOfSecond):创建指定的小时、分钟、秒和纳秒的时间。
LocalTime localTime = LocalTime.of(12,46,50,500000000); // 12:46:50.500
LocalTime 和 LocalDate 提供的方法都差不多,plus 增加时分秒、minus 减少时分秒,get 获取时分秒,with 修改时分秒,同时 LocalTime 也是不变的,所以也是线程安全的。
时间计算
LocalTime 提供了 plus 和 minus 类型方法用于对时间进行加减操作。
plusHours()、plusMinutes()、plusSeconds():分别用于在时间上增加时、分、秒。minusHours()、minusMinutes()、minusSeconds():分别用于在时间上减少时、分、秒。
@Test
public void test() {
LocalTime localTime = LocalTime.now();
LocalTime plusHours = localTime.plusHours(1);
LocalTime plusMinutes = localTime.plusMinutes(1);
LocalTime plusSeconds = localTime.plusSeconds(1);
LocalTime minusHours = localTime.minusHours(1);
LocalTime minusMinutes = localTime.minusMinutes(1);
LocalTime minusSeconds = localTime.minusSeconds(1);
System.out.println("localTime:" + localTime);
System.out.println("plusHours(1):" + plusHours);
System.out.println("plusMinutes(1):" + plusMinutes);
System.out.println("plusSeconds(1):" + plusSeconds);
System.out.println("minusHours(1):" + minusHours);
System.out.println("minusMinutes(1):" + minusMinutes);
System.out.println("minusSeconds(1):" + minusSeconds);
}
// 结果......
localTime:15:40:01.160
plusHours(1):16:40:01.160
plusMinutes(1):15:41:01.160
plusSeconds(1):15:40:02.160
minusHours(1):14:40:01.160
minusMinutes(1):15:39:01.160
minusSeconds(1):15:40:00.160
获取时间信息
LocalTime 提供了 get 类方法用于获取时间相关的信息。
getHour()、getMinute()、getSecond()、getNano():分别用于获取时间的时、分、秒、纳秒。
@Test
public void test() {
LocalTime localTime = LocalTime.now();
System.out.println("localTime:" + localTime);
System.out.println("getHour():" + localTime.getHour());
System.out.println("getMinute():" + localTime.getMinute());
System.out.println("getSecond():" + localTime.getSecond());
System.out.println("getNano():" + localTime.getNano());
}
// 结果......
localTime:15:43:38.300
getHour():15
getMinute():43
getSecond():38
getNano():300000000
修改时间
LocalTime 提供了 with 类方法用于修改时分秒:
withHour()、withMinute()、withSecond() 分别用于修改时间上的时、分、秒。
@Test
public void test() {
LocalTime localTime = LocalTime.now();
System.out.println("withHour(22):" + localTime.withHour(22));
System.out.println("withMinute(22):" + localTime.withMinute(22));
System.out.println("withMinute(22):" + localTime.withSecond(22));
System.out.println("localTime:" + localTime);
}
// 结果......
withHour(22):22:49:41.755
withMinute(22):15:22:41.755
withMinute(22):15:49:22.755
localTime:15:49:41.755
LocalDateTime 本地日期时间
在大部分时间我们不仅仅只是需要日期或者时间,而是日期和时间,这是时候我们就需要使用 LocalDateTime。LocalDateTime 是用于处理日期和时间的,它不包含时区信息,它提供了一种简单、便捷的方式处理日期和时间,可以代替旧的 java.util.Date 和 java.util.Calendar 类,并且提供更多的功能和灵活性。
LocalDateTime 是表示日期和时间的,包括年、月、日、小时、分钟、秒以及毫秒,但是不包括时区。它里面很多方法和 LocalDate 、LocalTime 一致,所以大明哥在这里就不过多介绍了。
plus类:增加日期或时间minus类:减少日期或时间get类:获取日期或时间with类:修改日期或时间isBefore、isAfter:比较两个 LocalDateTime 对象
ZonedDateTime 带时区的日期时间
ZonedDateTime 是一个用于表示包含时区信息的日期和时间对象,它用于解决处理日期和时间时的时区问题,以便更好地支持全球化的时间操作。
有了一个 LocalDateTime 不够,为什么还需要在增加一个 ZonedDateTime 呢?要明白这个问题我们就需要先了解什么是时区,为什么需要它。
什么是时区
由于地球自转,不同经度上的地方会在不同时刻经历日出和日落,因此当你在一个地方看到太阳高悬在天空中时,在另一个地方可能是夜晚。当你 9 点起来上班时,别人可能刚刚吃完晚饭准备带老婆孩子去遛弯,所以我们需要创建时区机制,来保证能更合理地安排生产生活。
时区是地球上的不同区域,每个区域都使用统一的时间标准,使人们能够在不同地方协调时间。时区基于经度划分,地球被分成24个主要时区,每个时区大致相当于地球上的一个经度带。每个时区都有自己的标准时间,该时间是该时区内所有地方的参考时间。
ZonedDateTime 的使用方法
ZonedDateTime 和 LocalDateTime 中的方法几乎都一样,知道 LocalDateTime 的方法含义就一定知道 ZonedDateTime 的方法含义。下面大明哥讲解下与 LocalDateTime 不一样的地方。
ZonedDateTime 也是提供了now() 和 of() 来创建 ZonedDateTime :
ZonedDateTime zonedDateTime = ZonedDateTime.now();
// 当前日期时间,时区为系统默认时区
使用 of() 需要指明时区 ZoneId,ZoneId 是 Java 中用于表示时区的类,目前 Java 8 中共包含 599 个时区。
Set<String> availableZoneId = ZoneId.getAvailableZoneIds(); // 获取所有的时区
// 根据时区 id 获取 ZoneId 对象
ZoneId GMT= ZoneId.of("GMT");
得到 ZoneId 对象后就可以利用 of() 来构建 ZonedDateTime 对象:
ZonedDateTime zonedDateTime = ZonedDateTime.of(2023, 10, 9, 21, 10, 0, 0, ZoneId.of("America/New_York"));
也可以将一个 LocalDateTime 转换为 ZonedDateTime:
LocalDateTime localDateTime = LocalDateTime.now();
ZonedDateTime zonedDateTime = ZonedDateTime.of(localDateTime,ZoneId.of("America/New_York"));
ZonedDateTime 也提供了时区转换的功能:
withZoneSameInstant():保持时间点不变,但切换到另一个时区withZoneSameLocal():会保持本地时间不变,但根据新时区调整偏移量
ZonedDateTime newYorkTime = zonedDateTime.withZoneSameInstant(ZoneId.of("America/New_York"));
ZonedDateTime londonTime = zonedDateTime.withZoneSameInstant(ZoneId.of("Europe/London"));
Java 8 新特性—日期时间格式化
通过前一篇文章(日期时间 API)我们知道如何在 Java 8 中得到我们需要的日期和时间,但是有时候我们需要将日期和时间对象转换为字符串又或者将字符串解析为日期时间对象,这个时候我们需要用到 Java 8 提供的日期时间格式化工具:DateTimeFormatter。

DateTimeFormatter
DateTimeFormatter 用于格式化和解析日期和时间,它能够轻松地将日期时间对象转换为字符串以及将字符串解析为日期时间对象。而且它是不可变的,线程安全的。
创建 DateTimeFormatter
DateTimeFormatter 提供了 ofPattern() 静态方法用于构建 DateTimeFormatter 对象:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
其他静态方法如下:
ofPattern(String pattern, Locale locale):使用给定的模式和区域设置创建格式化器。ofLocalizedDate(FormatStyle dateStyle):创建具有当地特定日期格式的格式化器。FormatStyle是一个枚举,其值可以是FULL, LONG, MEDIUM, SHORT。ofLocalizedDateTime(FormatStyle dateTimeStyle):创建具有特定地区日期时间(date-time)格式的格式化器。ofLocalizedDateTime(FormatStyle dateStyle, FormatStyle timeStyle): 创建具有特定地区日期时间(date-time)格式的格式化器。我们需要为日期和时间分别传递FormatStyle。例如,日期可以是LONG,时间可以是SHORT。ofLocalizedTime(FormatStyle timeStyle): 创建具有当地特定时间格式的格式化器。
我们也可以使用预定义的格式化器,DateTimeFormatter 提供了大量的预定义格式化器,如下:
| Formatter | Example |
|---|---|
| BASIC_ISO_DATE | ‘20181203’ |
| ISO_LOCAL_DATE | ‘2018-12-03’ |
| ISO_OFFSET_DATE | ‘2018-12-03+01:00’ |
| ISO_DATE | ‘2018-12-03+01:00’; ‘2018-12-03’ |
| ISO_LOCAL_TIME | ‘11:15:30’ |
| ISO_OFFSET_TIME | ‘11:15:30+01:00’ |
| ISO_TIME | ‘11:15:30+01:00’; ‘11:15:30’ |
| ISO_LOCAL_DATE_TIME | ‘2018-12-03T11:15:30’ |
| ISO_OFFSET_DATE_TIME | ‘2018-12-03T11:15:30+01:00’ |
| ISO_ZONED_DATE_TIME | ‘2018-12-03T11:15:30+01:00[Europe/Paris]’ |
| ISO_DATE_TIME | ‘2018-12-03T11:15:30+01:00[Europe/Paris]’ |
| ISO_ORDINAL_DATE | ‘2018-337’ |
| ISO_WEEK_DATE | ‘2018-W48-6’ |
| ISO_INSTANT | ‘2018-12-03T11:15:30Z’ |
| RFC_1123_DATE_TIME | ‘Tue, 3 Jun 2018 11:05:30 GMT’ |
例如,我们使用 ISO_DATE_TIME 格式化一个日期时间:
DateTimeFormatter formatter = DateTimeFormatter.ISO_DATE_TIME;
String dateTime = formatter.format(LocalDateTime.now()); //2023-10-10T15:36:03.626
如果我们需要的不再是简单的 yyyy-MM-dd 格式的日期,而是更加复杂的日期格式,我们可以使用 DateTimeFormatterBuilder 来构建更加复杂的日期格式。
格式转换
将日期时间对象转换为字符串
为了格式化一个日期、时间或日期时间,DateTimeFormatter提供了两个 format 方法:
format(TemporalAccessor temporal):将日期时间对象格式化为字符串,返回的是一个字符串对象。
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
System.out.println(dateTimeFormatter.format(LocalDateTime.now())); //2023-10-09 22:12:55
formatTo(TemporalAccessor temporal, Appendable appendable):将日期时间对象格式化,但是它没有返回值,而是将结果附加到给定的Appendable对象中。Appendable对象可以是StringBuffer、StringBuilder等的实例,这样可以提供性能,因为它避免创建了不必要的字符串对象。
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
StringBuilder stringBuilder = new StringBuilder();
dateTimeFormatter.formatTo(LocalDateTime.now(),stringBuilder);
System.out.println(stringBuilder.toString()); // 2023-10-09 22:23:43
也可以将日期时间格式的字符串转换为 LocalDateTime、ZonedDateTime 等日期时间对象:
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
System.out.println(LocalDateTime.parse("2023-10-09 22:12:55",dateTimeFormatter)); //2023-10-09T22:12:55
将字符串解析为日期时间对象
DateTimeFormatter 用于将字符串解析为日期时间对象的方法主要是 parse(),但是它返回的是 TemporalAccessor,我们需要再次将 TemporalAccessor 进一步转换:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy/MM/dd");
TemporalAccessor temporalAccessor = formatter.parse("2023-10-10");
LocalDate localDate = LocalDate.from(temporalAccessor);
有点儿繁琐,所以如果我们明确了要解析的类型,可以直接使用 来将字符串解析为指定的日期时间对象:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy/MM/dd");
LocalDate localDate = formatter.parse("2023-10-10", LocalDate::from);
或者直接使用具体的日期时间对象的 parse() 来转换:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy/MM/dd");
LocalDate localDate = LocalDate.parse("2023-10-10",formatter);
DateTimeFormatterBuilder
DateTimeFormatter 虽然能够帮忙我们格式化标准的日期时间,但是有时候我们需要更加复杂的日期时间格式,比如这种格式:Day is:17, month is:10, and year:2014 with the time:23:35 ,你使用 DateTimeFormatter 是会报错的:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("Day is:dd, month is:MM, and year:yyyy with the time:HH:mm");
String dateTime = formatter.format(LocalDateTime.now());
报错如下:

碰到这种比较灵活,个性化的日期格式时,DateTimeFormatter 无法处理或者处理起来比较麻烦时,我们可以使用更加强大灵活的 DateTimeFormatterBuilder。
DateTimeFormatterBuilder 是 Java 中用于构建自定义日期时间的格式化神器。它允许我们按照自己的需求来构建日期和时间,包括自定义的日期和时间分隔符时区、日期元素的顺序等等。
DateTimeFormatter 中的预定义格式化器就是采用 DateTimeFormatterBuilder 来构建的,例如 ISO_DATE_TIME:
public static final DateTimeFormatter ISO_DATE_TIME;
static {
ISO_DATE_TIME = new DateTimeFormatterBuilder()
.append(ISO_LOCAL_DATE_TIME)
.optionalStart()
.appendOffsetId()
.optionalStart()
.appendLiteral('[')
.parseCaseSensitive()
.appendZoneRegionId()
.appendLiteral(']')
.toFormatter(ResolverStyle.STRICT, IsoChronology.INSTANCE);
}
当我们通过构造函数构建出一个 DateTimeFormatterBuilder 实例对象后,就可以通过它的实例方法来添加不同的元素构造成我们的格式化器。常见的方法有:
| 方法 | 描述 |
|---|---|
appendPattern(String pattern) | 根据传入的模式字符串添加格式化元素。 |
appendLiteral(char literal) | 添加字面文字。 |
appendValue(TemporalField field, int width) | 添加字段值。 |
appendText(TemporalField field) | 添加字段的文本表示。 |
appendZoneId() | 添加时区标识。 |
appendOffset(String pattern, String noOffsetText) | 添加偏移量信息。 |
示例:
builder.appendPattern("yyyy-MM-dd HH:mm:ss");
builder.appendLiteral('T');
builder.appendValue(ChronoField.HOUR_OF_DAY, 2);
builder.appendLiteral(':');
builder.appendValue(ChronoField.MINUTE_OF_HOUR, 2);
当我们构建完毕后,使用 toFormatter() 方法就可以将其转换为 DateTimeFormatter。下面我们就用 DateTimeFormatterBuilder 来完成上面那个示例。
Day is: 这种是字面文字,所以使用 appendLiteral(char literal) 直接添加就可以了。年月日这样的实际值我们需要 appendValue(TemporalField field, int width) 来添加,该方法中的 width 表示字面的宽度,即显示字段的位数,比如 9 月份,如果 width 为 2 ,则显示为 09,如果不设置的话则显示为 9,代码如下:
@Test
public void test() {
DateTimeFormatter formatter = new DateTimeFormatterBuilder().appendLiteral("Day is:")
.appendValue(ChronoField.DAY_OF_MONTH,2)
.appendLiteral(", month is:")
.appendValue(ChronoField.MONTH_OF_YEAR,2)
.appendLiteral(", and year:")
.appendValue(ChronoField.YEAR,4)
.appendLiteral(" with the time:")
.appendValue(ChronoField.HOUR_OF_DAY)
.appendLiteral(":")
.appendValue(ChronoField.MINUTE_OF_HOUR)
.toFormatter();
LocalDateTime dateTime = LocalDateTime.of(2023,9,13,22,34,25,0);
String str = dateTime.format(formatter);
System.out.println(str);
}
// 结果......
Day is:13, month is:09, and year:2023 with the time:22:34
是不是很完美地呈现出来了?
DateTimeFormatterBuilder 是一个非常灵活的格式化工具,我们可以利用它创建各种各样的自定义日期时间格式化器,以满足我们的特定需求。
Java 8 新特性—CompletableFuture
CompletableFuture 是 Java 8 中引入用于处理异步编程的核心类,它引入了一种基于 Future 的编程模型,允许我们以更加直观的方式执行异步操作,并处理它们的结果或异常。
Future 的局限性
学过 Java 并发或者接触过异步开发的小伙伴应该都知道 Future,通过 Future 我们能够知道异步执行的操作结果,它提供了 isDone() 来检测异步是否已经完成,也可以通过 get() 方法来获取计算结果。在异步计算中,Future 确实是一个非常优秀的接口,但是它依然存在一些局限性:
- 缺乏回调机制:Future 没有内置的回调机制,这就意味着我们必须轮询 Future 对象来检查任务是否完成,而不是等待通知。
- 无法取消任务:虽然可以通过
cancel()方法来取消 Future 中的任务,但这并不保证任务会被取消。如果任务已经开始执行,那么cancel()方法可能无法终止任务的执行。 - 缺乏异常处理机制:Future 通过
get()方法返回任务的结果或异常,但它无法提供更多的异常处理功能。如果任务抛出异常,你必须在客户端代码中捕获这些异常。 - 单一结果:每个 Future 对象只能关联一个任务,这就限制了它的使用,如果我们需要并行执行多个任务并收集它们的结果,我们只能自己管理多个 Future 对象。
- 无法进行链式调用:如果我们希望在计算完成后执行特定操作,比如通知用户,这个时候我们就无法使用 Future 来实现了。
- 无法组合多任务:在处理多个任务时,Future 并没有提供很好的组合方式,比如我们需要等待 10 任务全部完成后再执行特定操作,这个时候使用 Future 就不是很好操作了。
什么是 CompletableFuture
为了克服 Future 的局限性,Java 8 提供了 CompletableFuture,它构建在 Future 之上,提供了更加强大的异步编程功能,相比 Future 它具备如下优势:
- 提供了回调机制:CompletableFuture 提供了回调功能,我们可以注册回调函数来处理任务完成时的结果,而不必阻塞线程等待任务完成。这样可以提高并发性能,减少线程的阻塞时间。
- 提供了异常处理:CompletableFutur 具备丰富的异常处理机制,可以捕获任务执行中的异常,并允许我们定义自定义的异常处理策略。
- 能够取消任务:我们可以使用
cancel()取消任务的执行,同时还可以指定是否中断正在执行的任务。这提供了更好的任务控制能力。 - 强大的异步编程能力:CompletableFuture 提供了丰富的方法来处理异步操作,包括组合、转换、处理异常以及执行自定义的操作。这使得异步编程更加灵活,可以更轻松地实现复杂的异步任务组合。
- 支持组合、链式操作:CompletableFutur 提供了一系列支持组合操作的方法,例如
thenCombine(),thenCompose(),thenApplyAsync()等等,使得多个 CompletableFuture 可以轻松组合成一个新的 CompletableFuture,从而更容易构建复杂的异步操作流。
CompletableFuture 提供了比传统 Future 更加强大、更加灵活的异步编程能力,能够更好地满足复杂异步任务处理的需求,能够更加方便地构建复杂的异步操作流,是 Java 8 及以后的版本中,处理异步操作的首选。
CompletableFuture 的核心 API
构建异步操作
CompletableFuture 提供了多种方法用于构建异步操作。
runAsync(): 用于异步执行没有返回值的任务。
它有两个重载方法:
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
这两个方法的区别在于:
runAsync(Runnable runnable)会使用 ForkJoinPool 作为它的线程池执行异步代码。runAsync(Runnable runnable, Executor executor)则是使用指定的线程池执行异步代码。
示例:
@Test
public void runAsyncTest(){
CompletableFuture.runAsync(() ->{
log.info("死磕 Java 新特性 - 01");
});
CompletableFuture.runAsync(() -> {
log.info("死磕 Java 新特性 - 02");
}, Executors.newFixedThreadPool(10));
}
结果

supplyAsync(): 用于异步执行有返回值的任务。
supplyAsync() 也有两个重载方法,区别 runAsync() 和一样:
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor
示例:
@Test
public void supplyAsyncTest() throws Exception {
CompletableFuture<String> completableFuture1 = CompletableFuture.supplyAsync(() ->{
log.info("死磕 Java 新特性 - 01");
return "死磕 Java 新特性 - 01";
});
CompletableFuture<String> completableFuture2 = CompletableFuture.supplyAsync(() ->{
log.info("死磕 Java 新特性 - 02");
return "死磕 Java 新特性 - 02";
},Executors.newFixedThreadPool(10));
log.info(completableFuture1.get());
log.info(completableFuture2.get());
}
结果:

completedFuture(): 创建一个已完成的 CompletableFuture,它包含特定的结果。
@Test
public void completedFutureTest() {
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("死磕 Java 就是牛");
System.out.println(completableFuture.join());
}
// 结果......
死磕 Java 就是牛
注意:使用默认线程池会有一个:在主线程任务执行完以后,如果异步线程执行任务还没执行完,它会直接把异步任务线程清除掉,因为默认线程池中的都是守护线程 ForkJoinPool,当没有用户线程以后,会随着 JVM 一起清除。
@Test
public void runAsyncTest(){
CompletableFuture.runAsync(() ->{
log.info("CompletableFuture 任务开始执行...");
for (int i = 0; i < 100 ; i++) {
log.info("CompletableFuture 任务执行中[{}]...",i);
}
log.info("CompletableFuture 任务执行完毕...");
});
log.info("主线程执行完毕...");
}
结果:
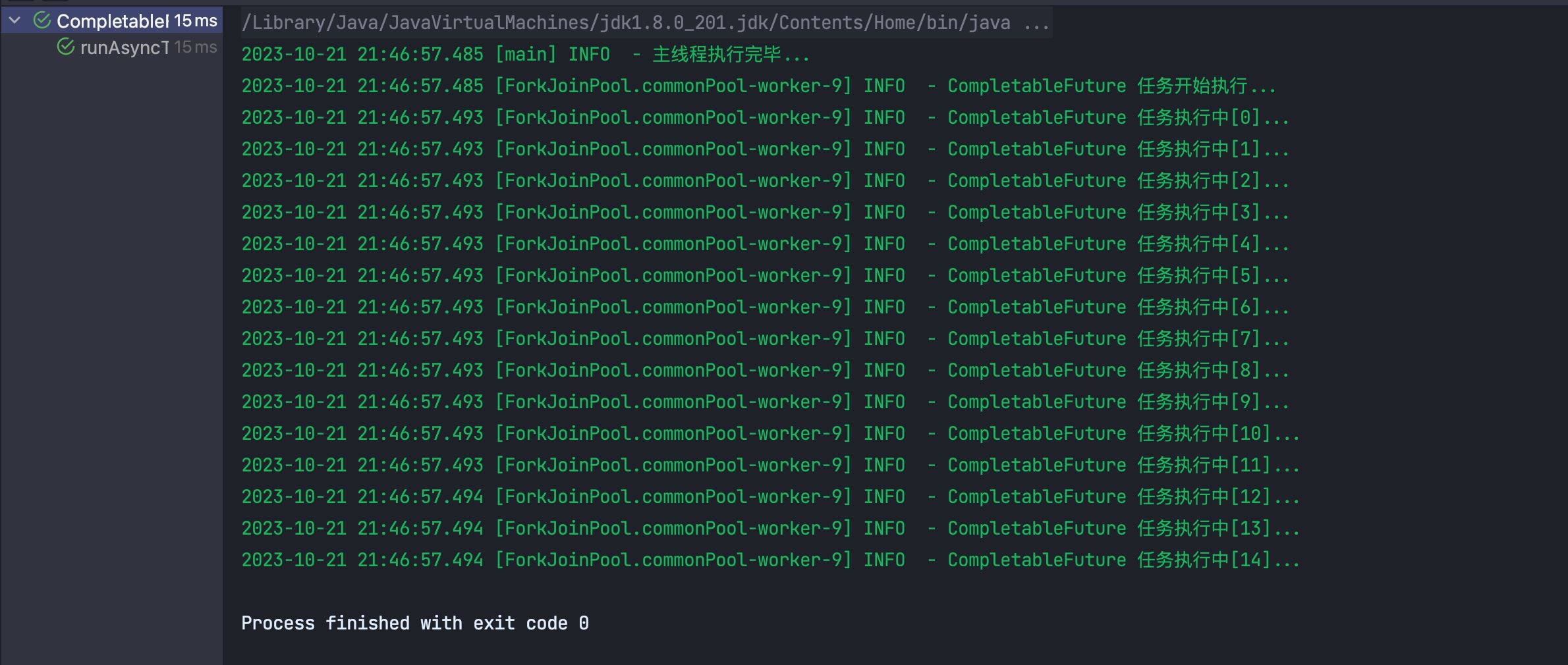
CompletableFuture 任务的 for 循环只执行到 14 就结束了,并没有完成整个任务就被清理掉了。
获取结果
CompletableFuture 提供了 get() 和 join() 方法用于我们获取计算结果:
public T get() throws InterruptedException, ExecutionException
public T get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException
public T join()
get() 有两个重载方法:
get():会阻塞当前线程,直到计算完成并返回结果get(long timeout, TimeUnit unit):有阻塞时间,如果在指定的超时时间内未能获取到结果,会抛出TimeoutException异常。
而 get() 和 join() 的区别则在于:
get()会抛出InterruptedException和ExecutionException这两个受检查异常,我们必须显式地在代码中处理这些异常或将它们抛出。join()不会抛出受检查异常,所以在使用过程中代码会显得更加简洁,但是如果任务执行中发生异常,它会包装在CompletionException中,我们需要在后续代码中处理。
示例:
@Test
public void completedFutureTest() {
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("死磕 Java 就是牛");
System.out.println(completableFuture.join());
try {
System.out.println(completableFuture.get());
} catch (InterruptedException | ExecutionException e) {
// 捕获异常并处理
// 或者直接抛出
}
}
结果、异常处理
当 CompletableFuture 因为异步任务执行完成或者发生异常而完成时,我们可以执行特定的 Action,主要方法有:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
public CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)
whenComplete(BiConsumer<? super T,? super Throwable> action)
接受一个 Consumer 参数,该参数接受计算的结果(如果成功)或异常(如果发生异常)并执行相应的操作。
@Test
public void whenCompleteTest() {
CompletableFuture<String> completableFuture1 = CompletableFuture.supplyAsync(() -> {
log.info("[completableFuture-1] - www.skjava.com 网站就是牛..");
return "[completableFuture-1] - 死磕 Java 新特性";
}).whenComplete((res,ex) -> {
if (ex == null) {
System.out.println("结果是:" + res);
} else {
System.out.println("发生了异常,异常信息是:" + ex.getMessage());
}
});
}
该方法是同步执行,回调函数是在触发它的 CompletableFuture 所在的线程中执行,且它会阻塞当前线程。比如这里我们是在 main 线程去调用它的,所以执行他的线程就是 main 线程,它会阻塞 mian 线程执行。如下:
public class WhenCompleteTest {
private static CompletableFuture<String> future;
public static void main(String[] args) {
future = CompletableFuture.supplyAsync(() ->{
log.info("CompletableFuture 主体执行");
return "死磕 Java 新特性";
});
Thread thread = new Thread(() ->{
log.info("thread 线程开始执行");
future.whenComplete((res,ex) -> {
log.info("whenComplete 主体开始执行");
sleep(5);
if (ex == null) {
log.info("whenComplete 执行结果:{}",res);
} else {
log.info("whenComplete 执行异常:{}",ex.getMessage());
}
log.info("whenComplete 主体执行完毕");
});
log.info("thread 线程执行完成");
});
thread.setName("test-thread");
thread.start();
// 阻塞主线程
sleep(15);
log.info("主线程执行完毕");
}
public static void sleep(long sleep) {
try {
TimeUnit.SECONDS.sleep(sleep);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
结果
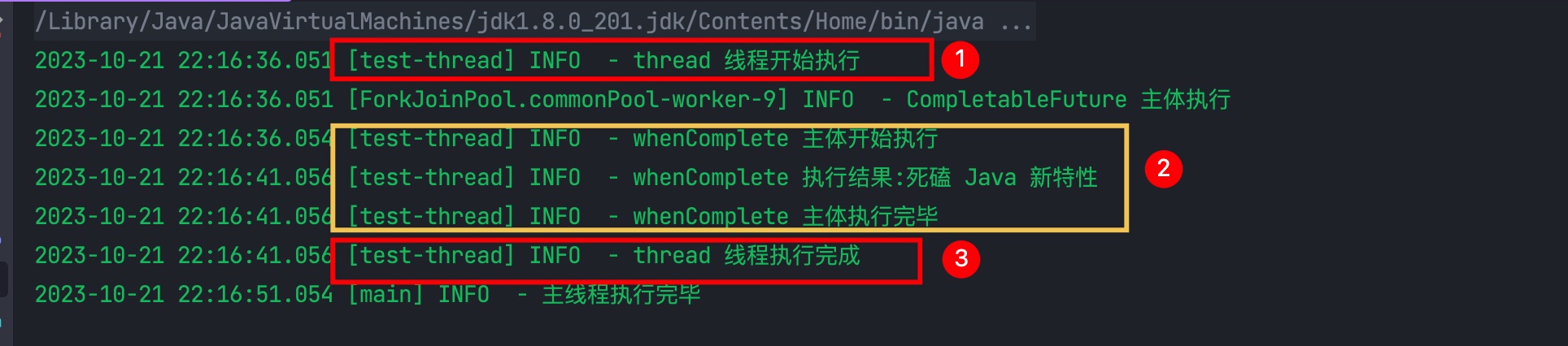
- 首先
test-thread线程先执行,打印 “thread 线程开始执行” - 然后调用
future.whenComplete(),这个时候我们看到执行的线程也是test-thread,在这里面它等待了 5 秒 - 5 秒过后再次打印 “thread 线程执行完成”
从执行结果中可以看出 whenComplete() 就是由调用它的线程来执行,且会阻塞当前线程
whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)
异步执行,回调函数会在默认的 ForkJoinPool 的线程中执行,但是它不会阻塞当前线程。我们将上面例子的 whenComplete() 改成 whenCompleteAsync(),执行结果如下:
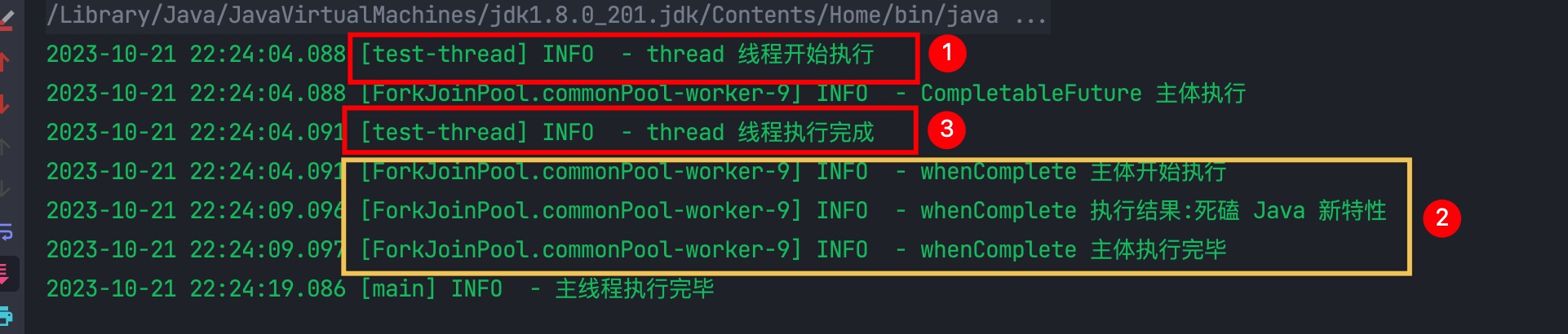
whenCompleteAsync()方法的执行线程是ForkJoinPool.commonPool-worker-9- 没有阻塞
test-tread线程的执行
whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
它与前一个方法相似,只不过我们可以执行执行 Action 执行的线程池。
@Test
public void whenCompleteTest() {
CompletableFuture<String> completableFuture3 = CompletableFuture.supplyAsync(() -> {
log.info("[completableFuture-3] - www.skjava.com 网站就是牛..");
return "[completableFuture-2] - 死磕 Java 新特性";
}).whenCompleteAsync((res,ex) -> {
if (ex == null) {
log.info("结果是:{}",res);
} else {
log.warn("发生了异常,异常信息是:{}",ex.getMessage());
}
},Executors.newFixedThreadPool(4));
}
exceptionally(Function<Throwable, ? extends T> fn)
exceptionally() 用于处理异步操作中的异常情况,当异步操作发生异常时,该回调函数将会被执行,我们可以在该回调函数中处理异常情况。exceptionally() 返回一个新的 CompletableFuture 对象,其中包含了异常处理的结果或者异常对象。
@Test
public void exceptionallyTest() {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
int i = 10 / 0;
return "死磕 Java 并发就是牛";
});
CompletableFuture<String> resultFuture = future.exceptionally((ex) -> {
log.info("发生了异常:{}",ex.getMessage());
return "死磕 Netty 就是牛";
});
try {
System.out.println(future.join());
} catch (Exception ex) {
log.error("异常:{}",ex.getMessage());
}
System.out.println(resultFuture.join());
}
结果

由于 future 抛了异常,所以调用 future.join() 会报错,我们需要 try...catch 处理下 。
结果转换
结果转换,就是将上一段任务的执行结果作为下一阶段任务的入参参与重新计算,产生新的结果。
thenApply()** 和thenApplyAsync():** 用于将一个 CompletableFuture 的结果应用于一个函数,并返回一个新的 CompletableFuture,表示转换后的结果。
@Test
public void thenApplyTest() {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
log.info("执行第一步...");
return "死磕 Java";
}).thenApply(s -> {
log.info("执行第二步,第一步返回结果:{}",s);
return s + " 就是牛..";
});
log.info("结果为:{}",completableFuture.join());
}
// 结果......
2023-10-22 15:28:26.882 [ForkJoinPool.commonPool-worker-9] INFO - 执行第一步...
2023-10-22 15:28:26.888 [ForkJoinPool.commonPool-worker-9] INFO - 执行第二步,第一步返回结果:死磕 Java
2023-10-22 15:28:26.888 [main] INFO - 结果为:死磕 Java 就是牛.
thenApply()** 和 **thenApplyAsync() 两个方法的区别就不用大明哥再阐述了吧。
thenCompose()和thenComposeAsync():它用于将一个 CompletableFuture 的结果应用于一个函数,该函数返回一个新的 CompletableFuture。
@Test
public void thenComposeTest() {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
log.info("执行第一步...");
return "死磕 Java";
}).thenCompose((s) -> {
log.info("执行第二步,第一步返回结果:{}",s);
// 注意这里跟 thenApply() 的差异
return CompletableFuture.supplyAsync(() -> s + " 就是牛..");
});
log.info("结果为:{}",completableFuture.join());
}
thenCompose() 与 thenApply() 两者的返回值虽然都是新的 CompletableFuture,但是 thenApply() 由于它的函数的返回值仅仅只是结果,所以它通常用于对异步操作的结果进行简单的转换,而 thenCompose() 则允许我们链式地组合多个异步操作。虽然两者都有可能实现相同的效果(比如上面例子),但是他们的使用场景和意义还是有区别的。
结果消费
结果消费则是只对结果执行 Action,而不返回新的计算值。
thenAccept():用于处理异步操作的结果,但不返回任何结果。
thenAccept() 接受一个 Consumer 函数接口。
@Test
public void thenAcceptTest() throws InterruptedException {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() ->{
return "死磕 Java 新特性";
});
completableFuture.thenAccept(s ->{
System.out.println("CompletableFuture 计算结果是:" + s);
});
TimeUnit.SECONDS.sleep(5);
}
// 结果......
CompletableFuture 计算结果是:死磕 Java 新特性
thenAcceptBoth():用于处理两个不同的 CompletableFuture 异步操作的结果,并执行操作,但不返回新的结果。
方法定义如下:
public CompletableFuture<Void> thenAcceptBoth(CompletableFuture<? extends U> other, BiConsumer<? super T, ? super U> action)
- other:为另外一个 CompletableFuture,它包含了另一个异步操作的结果。
- action:类型为 BiConsumer,它接受两个参数,分别表示第一个 CompletableFuture 的结果和第二个 CompletableFuture 的结果。
@Test
public void thenAcceptBothTest() throws InterruptedException {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 新特性");
future1.thenAcceptBoth(future2,(result1,result2) -> {
System.out.println("future1 的结果是:" + result1);
System.out.println("future2 的结果是:" + result2);
});
TimeUnit.SECONDS.sleep(5);
}
// 结果......
future1 的结果是:死磕 Netty
future2 的结果是:死磕 Java 新特性
thenRun():用于在一个 CompletableFuture 异步操作完成后执行操作,而不关注计算的结果
thenRun() 通常用于执行其他作用的操作、清理工作、或在异步操作完成后触发其他操作。
@Test
public void thenRunTest() throws InterruptedException {
CompletableFuture<String> future = CompletableFuture.completedFuture("死磕 Netty");
future.thenRun(() ->{
System.out.println("CompletableFuture 计算执行完成,开始执行后续操作...");
});
TimeUnit.SECONDS.sleep(5);
}
结果组合
thenCombine() 用于将两个不同的 CompletableFuture 异步操作的结果合并为一个新的结果,并执行操作。该方法允许我们在两个异步操作都完成后执行一个操作,它接受两个结果作为参数,并返回一个新的结果。
方法定义如下:
public <U, V> CompletableFuture<V> thenCombine(CompletableFuture<? extends U> other, BiFunction<? super T, ? super U, ? extends V> action)
- other:表示另外一个 CompletableFuture,它包含了该 CompletableFuture 的计算结果
- action:类型是 BiFunction,它接受两个参数,分别是第一个 CompletableFuture 的计算结果和第二个 CompletableFuture 的计算结果。
@Test
public void thenCombineTest() {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 新特性");
CompletableFuture<String> combineFuture = future1.thenCombine(future2,(result1,result2) ->{
System.out.println("future1 的结果是:" + result1);
System.out.println("future2 的结果是:" + result2);
return result1 + "和" + result1 + " 就是牛...";
});
System.out.println(combineFuture.join());
}
// 结果......
future1 的结果是:死磕 Netty
future2 的结果是:死磕 Java 新特性
死磕 Netty和死磕 Netty 就是牛...
任务交互
applyToEither()
applyToEither() 用于处理两个不同的 CompletableFuture 异异步操作中的任何一个完成后,将其结果应用于一个函数,并返回一个新的 CompletableFuture 表示该函数的输出结果。该方法允许我们在两个异步操作中的任何一个完成时执行操作,而不需要等待它们都完成。
@Test
public void applyToEitherTest() {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 新特性");
CompletableFuture<String> eitherFuture = future1.applyToEither(future2,res ->{
System.out.println("接受的结果是:" + res);
return "eitherFuture 接受的结果是:" +res;
});
System.out.println(eitherFuture.join());
}
// 结果.....
接受的结果是:死磕 Netty
eitherFuture 接受的结果是:死磕 Netty
acceptEither()
acceptEither() 与 applyToEither() 一样,也是等待两个 CompletableFuture 中的任意一个执行完成后执行操作,但是它不返回结果。
@Test
public void acceptEitherTest() {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 新特性");
CompletableFuture<Void> eitherFuture = future1.acceptEither(future2,res ->{
System.out.println("接受的结果是:" + res);
});
eitherFuture.join();
}
// 结果......
接受的结果是:死磕 Java 新特性
runAfterEither()
runAfterEither()用于在两个不同的 CompletableFuture 异步操作中的任何一个完成后执行操作,而不依赖操作的结果。这个方法通常用于在两个异步操作中的任何一个成功完成时触发清理操作或执行某些操作,而不需要返回值。
@Test
public void runAfterEitherTest() {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 并发");
future1.runAfterEither(future2,() ->{
System.out.println("已经有一个任务完成了...");
});
}
runAfterBoth()
runAfterBoth() 用于在两个不同的 CompletableFuture 异步操作都完成后执行操作,而不依赖操作的结果。这个方法通常用于在两个异步操作都完成时触发某些操作或清理工作,而不需要返回值。
@Test
public void runAfterBothTest() {
CompletableFuture<String> future1 = CompletableFuture.completedFuture("死磕 Netty");
CompletableFuture<String> future2 = CompletableFuture.completedFuture("死磕 Java 并发");
future1.runAfterBoth(future2,() ->{
System.out.println("future1 和 future2 两个异步任务都完成了...");
});
}
anyOf()
anyOf() 是用于处理多个 CompletableFuture 对象的静态方法,它允许我们等待多个异步操作中的任何一个完成,并执行相应的操作。它类似于多个异步操作的并发执行,只要有一个操作完成,它就会返回一个新的 CompletableFuture 对象,表示第一个完成的操作。
anyOf() 是一个可变参数,我们可以传入任意数量的 CompletableFuture 对象。
@Test
public void anyOfTest() {
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() ->{
sleep(1);
log.info("死磕 Netty 执行完成...");
return "死磕 Netty";
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() ->{
sleep(2);
log.info("死磕 Java 并发 执行完成...");
return "死磕 Java 并发";
});
CompletableFuture<String> future3 = CompletableFuture.supplyAsync(() ->{
sleep(3);
log.info("死磕 Redis 执行完成...");
return "死磕 Redis";
});
CompletableFuture<String> future4 = CompletableFuture.supplyAsync(() ->{
sleep(4);
log.info("死磕 Java 新特性 执行完成...");
return "死磕 Java 新特性";
});
CompletableFuture<String> future5 = CompletableFuture.supplyAsync(() ->{
sleep(5);
log.info("死磕 Spring 执行完成...");
return "死磕 Spring";
});
CompletableFuture<Object> anyOfFuture = CompletableFuture.anyOf(future1,future2,future3,future4,future5);
anyOfFuture.thenAccept(result -> {
log.info("接收到的结果为:" + result);
});
sleep(10);
}
结果
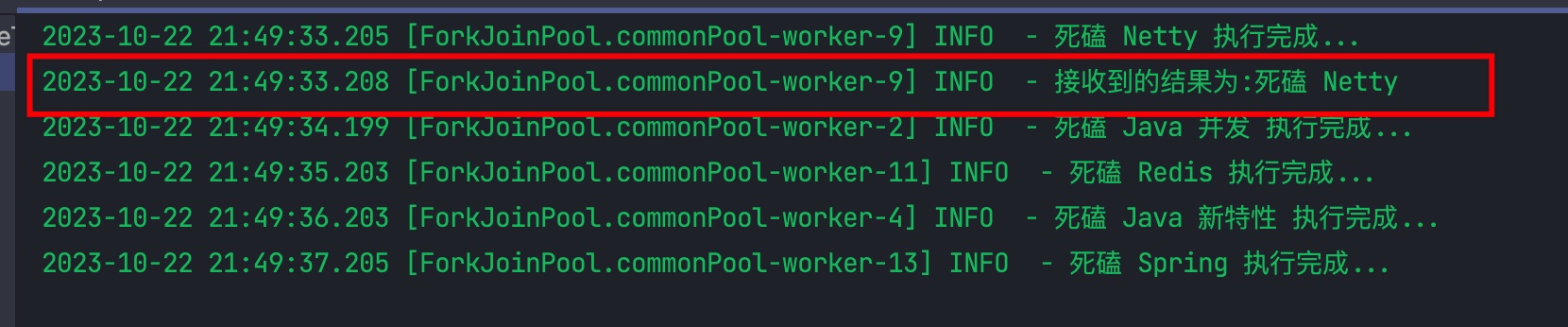
anyOf() 比较有用,当我们需要并行执行多个异步操作,并在其中任何一个完成时执行操作时,就可以使用它,大明哥在生产过程中应用过几次。
allOf()
anyOf() 是任一一个异步任务完成就会触发,而 allOf() 则需要所有异步都要完成。我们将上面方法改为 allOf() 得到结果如下:
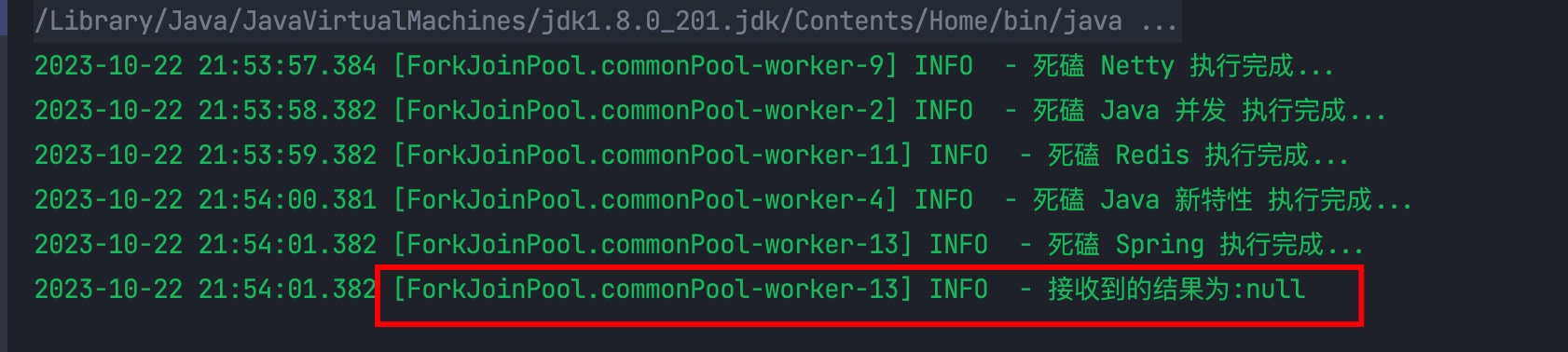
这里得到结果为 null,是因为 allOf() 是没有返回值的。
CompletableFuture 的任务编排
著名数学家华罗庚先生在《统筹方法》这篇文章里介绍了一个烧水泡茶的例子,最优解如下:
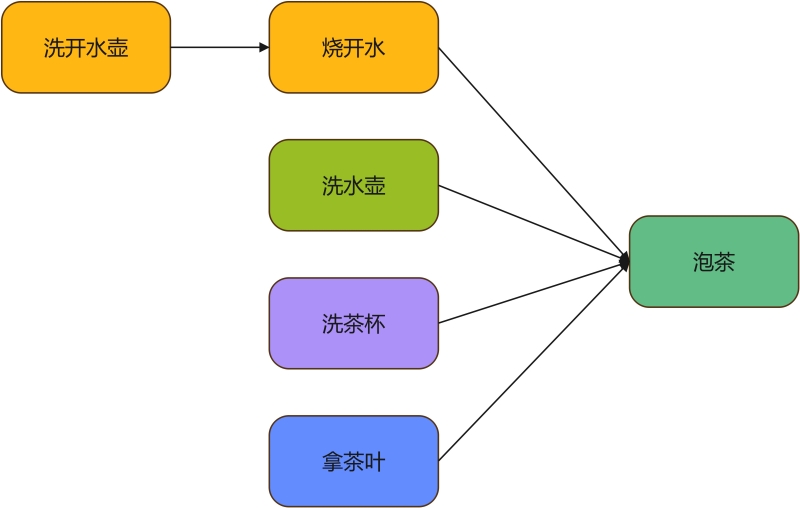
但是我们为了能够更好地验证 CompletableFuture 的任务编排功能,我们将其进行扩展:
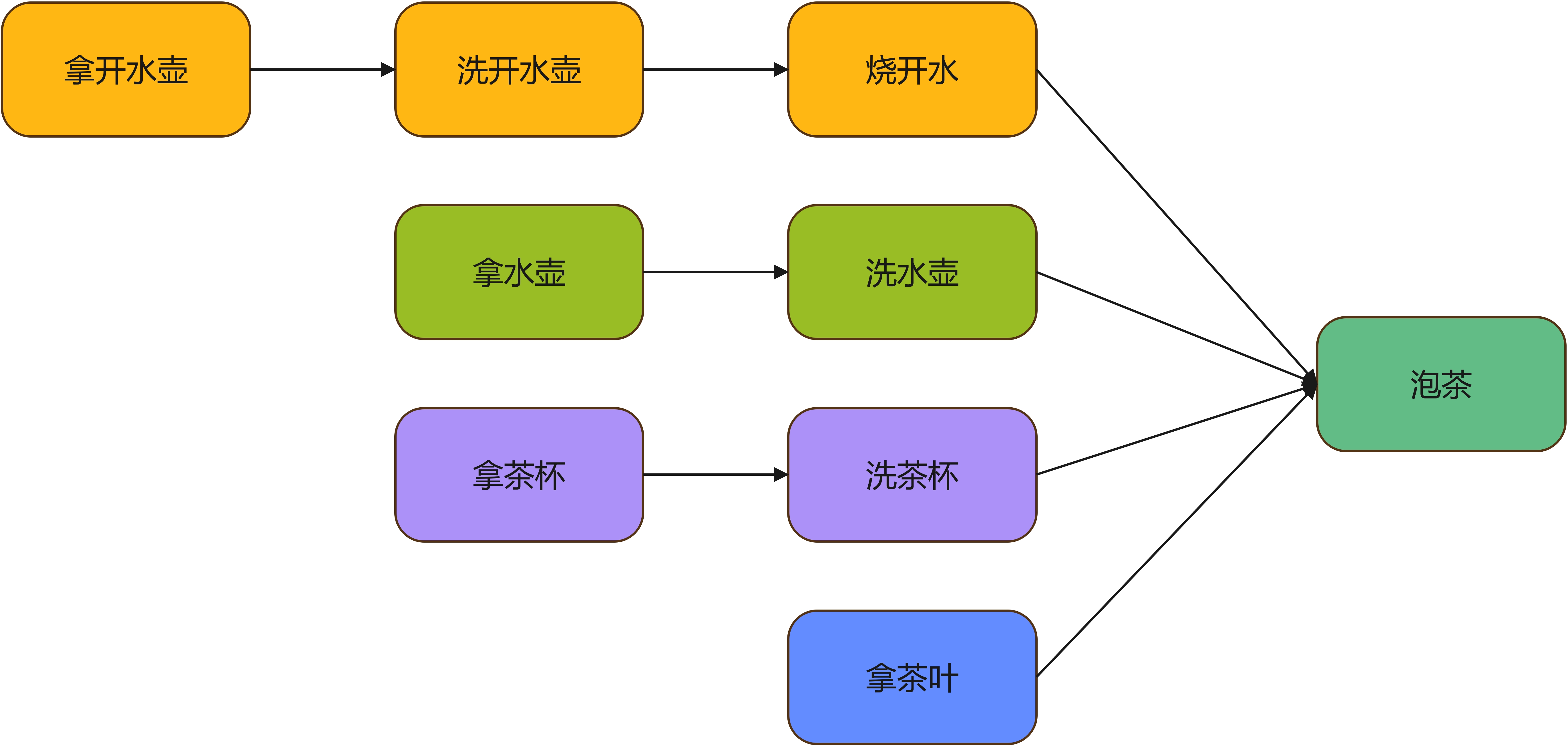
public class Tea {
public static void main(String[] args) throws InterruptedException {
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(()->{
log.info("拿开水壶");
return "开水壶";
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
log.info("拿水壶");
return "水壶";
});
CompletableFuture<String> future3 = CompletableFuture.supplyAsync(() ->{
log.info("拿茶杯");
return "茶杯";
});
CompletableFuture<String> future4 = CompletableFuture.supplyAsync(() -> {
log.info("拿茶叶");
return "西湖龙井";
});
CompletableFuture<String> future11 = future1.thenApply((result) -> {
log.info("拿到" + result + ",开始洗" + result);
return "干净的开水壶";
});
CompletableFuture<String> future12 = future11.thenApply((result) -> {
log.info("拿到" + result + ",开始烧开水");
return "烧开水了";
});
CompletableFuture<String> future21 = future2.thenApply((result) -> {
log.info("拿到" + result + ",开始洗" + result);
return "干净的水壶";
});
CompletableFuture<String> future31 = future3.thenApply((result) -> {
log.info("拿到" + result + ",开始洗" + result);
return "干净的茶杯";
});
CompletableFuture<Void> future5 = CompletableFuture.allOf(future4,future12,future21,future31);
future5.thenRun(() -> {
log.info("泡好了茶,还是喝美味的西湖龙井茶");
});
TimeUnit.SECONDS.sleep(5);
}
}
执行结果:
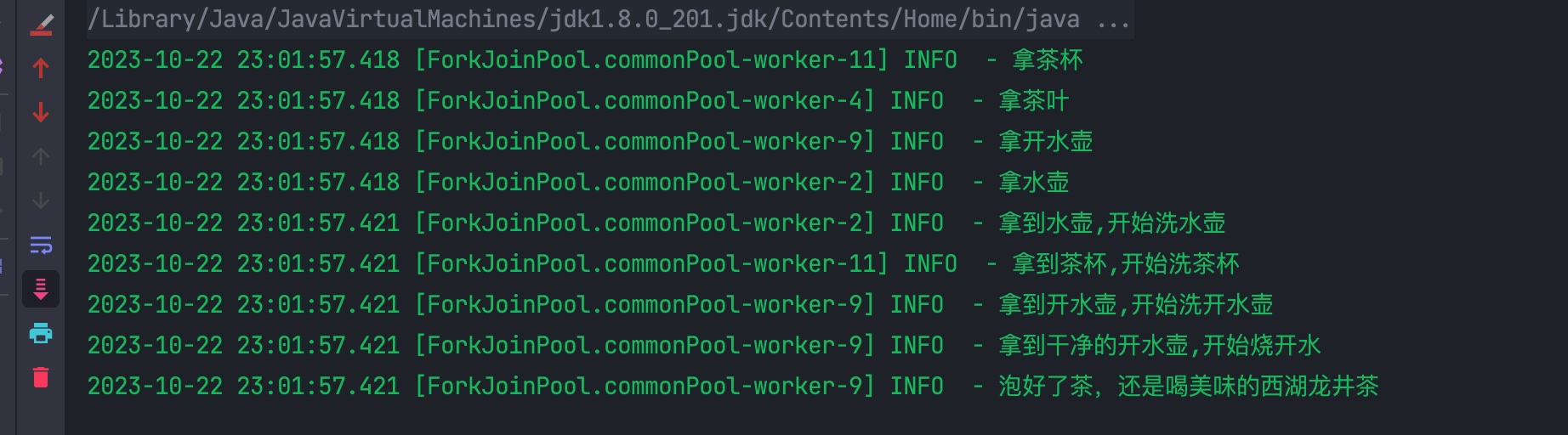
结果大明哥就不分析了,各位小伙伴好好对照下就明白了。通过这个例子我们清晰的见识到 CompletableFuture 任务编排的能力。
CompletableFuture API 总结
CompletableFuture的 API 比较多,不同的方法有不同的使用场景,大明哥也不可能将所有的 API 都介绍和举一个示例,就简单列一个表格吧。
构建异步操作
| 方法 | 说明 | 有无返回值 |
|---|---|---|
runAsync | 异步执行任务,默认 ForkJoinPool 线程池 | 无返回值 |
supplyAsync | 异步执行任务,默认 ForkJoinPool 线程池 | 有返回值 |
completedFuture | 创建一个已经完成的 CompletableFuture 对象 | 有返回值 |
两个线程依次执行
| 方法 | 说明 | 有无返回值 |
|---|---|---|
thenApply | 获取前一个线程的执行结果,第二个线程处理该结果,生成一个新的 CompletableFuture 对象 | 有返回值 |
thenAccept | 获取前一个线程的执行结果,第二个线程消费结果,不会返还给调用端 | 无返回值 |
thenRun | 第一个线程执行完后,再执行,它忽略第一个线程的执行结果,也不返回结果 | 无返回值 |
thenCompose | 获取前一个线程的执行结果,对其进行组合,返回新的 CompletableFuture 对象 | 有返回值 |
whenComplete | 获取前一个线程的结果或异常,消费 | 不影响上一线程返回值 |
exceptionally | 线程异常执行,配合whenComplete 使用 | 有返回值 |
handle | 相当于whenComplete + exceptionally | 有返回值 |
等待2个线程都执行完
| 方法 | 说明 | 有无返回值 |
|---|---|---|
thenCombine | 2个线程都要有返回值,等待都结束,结果合并转换 | 有返回值 |
thenAcceptBoth | 2个线程都要有返回值,等待都结束,结果合并消费 | 无返回值 |
runAfterBoth | 2个线程无需要有返回值,等待都结束,执行其他逻辑 | 无返回值 |
等待2个线程任一执行完
| 方法 | 说明 | 有无返回值 |
|---|---|---|
applyToEither | 2个线程都要有返回值,等待任一结束,转换其结果 | 有返回值 |
acceptEither | 2个线程都要有返回值,等待任一结束,消费其结果 | 无返回值 |
runAfterEither | 2个线程无需有返回值,等待任一结束,执行其他逻辑 | 无返回值 |
多个线程等待
| 方法 | 说明 | 有无返回值 |
|---|---|---|
anyOf | 多个线程任一执行完返回 | 有返回值 |
allOf | 多个线程全部执行完返回 | 无返回值 |
Java 8 新特性—重复注解@Repeatable

Java 8 之前如何使用重复注解
在 Java 8 之前我们是无法在一个类型重复使用多次同一个注解,比如我们常用的 @PropertySource,如果我们在 Java 8 版本以下这样使用:
@PropertySource("classpath:config.properties")
@PropertySource("classpath:application.properties")
public class PropertyTest {
}
编译会报错,错误信息是:Duplicate annotation。
那怎么解决这个问题呢?在 Java 8 之前想到一个方案来解决 Duplicate annotation 错误:新增一个注解 @PropertySources,该注解包裹 @PropertySource,如下:
public @interface PropertySources {
PropertySource[] value();
}
然后就可以利用 @PropertySources 来完成了:
@PropertySources({
@PropertySource("classpath:config.properties"),
@PropertySource("classpath:application.properties")
})
public class PropertyTest {
}
利用这种嵌套的方式来规避重复注解的问题,怎么获取呢?
@Test
public void test() {
PropertySources propertySources = PropertyTest.class.getAnnotation(PropertySources.class);
for (PropertySource propertySource : propertySources.value()) {
System.out.println(propertySource.value()[0]);
}
}
// 结果......
classpath:config.properties
classpath:application.properties
Java 8 重复注解 @Repeatable
通过上述那种方式确实是可以解决重复注解的问题,但是使用有点儿啰嗦,所以 Java 8 为了解决这个问题引入了注解 @Repeatable 来解决这个问题。
@Repeatable注解允许在同一个类型上多次使用相同的注解,它提供了更灵活的注解使用方式。
下面我们来看看如何使用重复注解。
如何使用重复注解
1、重复注解声明
在使用重复注解之前,需要在自定义注解类型上使用@Repeatable注解,以指定该注解可重复使用的容器注解类型。容器注解类型本身也是一个注解,通常具有一个value属性,其值是一个数组,用于存储重复使用的注解。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Repeatable(MyAnnotations.class) // 声明重复注解
public @interface MyAnnotation {
String name() default "";
}
/**
* 重复注解容器
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface MyAnnotations {
MyAnnotation[] value();
}
2、使用重复注解
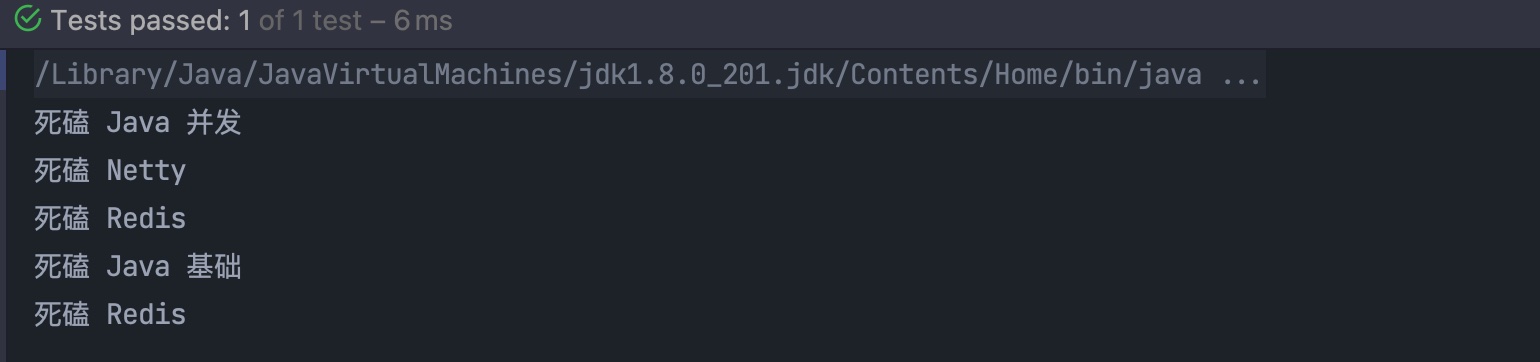
定义了重复注解,我们就可以在一个类型上面使用多个相同的注解,如下:
@MyAnnotation(name = "死磕 Java 并发")
@MyAnnotation(name = "死磕 Netty")
@MyAnnotation(name = "死磕 Redis")
@MyAnnotation(name = "死磕 Java 基础")
@MyAnnotation(name = "死磕 Redis")
public class MyAnnotationTest {
}
3、获取重复注解的值
使用放射获取元素上面的重复注解,由于我们这里有多个所以需要根据 getAnnotationsByType() 来获取所有重复注解的数组:
@Test
public void test() {
MyAnnotation[] myAnnotations = MyAnnotationTest.class.getAnnotationsByType(MyAnnotation.class);
for (MyAnnotation myAnnotation : myAnnotations) {
System.out.println(myAnnotation.name());
}
}
我们还可以直接获取它的容器注解:
@Test
public void test() {
MyAnnotations myAnnotations = MyAnnotationTest.class.getAnnotation(MyAnnotations.class);
for (MyAnnotation myAnnotation : myAnnotations.value()) {
System.out.println(myAnnotation.name());
}
}
依然可以获取到值。
重复注解很容易就理解了,知道如何自定义注解,然后变换下思路就行了。
Java 8 新特性—接口默认方法和静态方法
接口默认方法
在 Java 8 之前,接口中可以申明方法和变量的,只不过变量必须是 public、static、final 的,方法必须是 public、abstract的。我们知道接口的设计是一项巨大的工作,因为如果我们需要在接口中新增一个方法,需要对它的所有实现类都进行修改,如果它的实现类比较少还可以接受,如果实现类比较多则工作量就比较大了。
为了解决这个问题,Java 8 引入了默认方法,默认方法允许在接口中添加具有默认实现的方法,它使得接口可以包含方法的实现,而不仅仅是抽象方法的定义。
默认方法允许接口在不破坏实现类的情况下进行演进。这对于标准化库的维护和扩展非常重要,因为可以添加新的方法来满足新的需求,而不会影响已存在的实现。同时默认方法使得接口可以通过通用的方法实现,这可以减少代码的重复性,提供了代码的可维护性,是不是有点儿像抽象类了?
默认方法是通过在接口中使用 default 关键字来定义的,后面跟着方法的实现。语法如下:
interface MyInterface {
default void myDefaultMethod() {
// 默认方法的实现
}
}
实现类可以选择性地重写默认方法,如果它们
实现接口的类可以根据自己的需要重写接口的默认方法。当然如果实现类没有提供自己的实现,将使用默认方法的实现。
使用默认方法非常简单,就当做普通的方法调用即可。
// 接口
public interface MyInterface {
default String defaultMethod() {
return "MyInterface-defaultMethod";
}
}
// 实现类-1
public class MyInterfaceImpl1 implements MyInterface{
}
// 实现类-2
public class MyInterfaceImpl2 implements MyInterface{
@Override
public String defaultMethod() {
return "MyInterfaceImpl2-defaultMethod";
}
}
@Test
public void test() {
MyInterface myInterface1 = new MyInterfaceImpl1();
MyInterface myInterface2 = new MyInterfaceImpl2();
System.out.println(myInterface1.defaultMethod());
System.out.println(myInterface2.defaultMethod());
}
// 结果......
MyInterface-defaultMethod
MyInterfaceImpl2-defaultMethod
MyInterfaceImpl1 调用 MyInterface 接口内的 defaultMethod(),而 MyInterfaceImpl2 则是调用自己重写的 defaultMethod()。
我们知道 Java 是可以实现多个接口的,如果都包含具有相同方法签名的默认方法呢?这种情况,Java 要求我们实现类必须重写该默认方法来解决冲突,否则编译异常。比如再提供一个接口 MyInterface1 ,MyInterfaceImpl1 实现 MyInterface 和 MyInterface1:
public interface MyInterface1 {
default String defaultMethod() {
return "MyInterface1-defaultMethod";
}
}
public class MyInterfaceImpl1 implements MyInterface,MyInterface1{
}
编译器会提示你有这个错误:

这个时候就需要 MyInterfaceImpl1 重写 defaultMethod():
public class MyInterfaceImpl1 implements MyInterface,MyInterface1{
@Override
public String defaultMethod() {
// return MyInterface.super.defaultMethod(); or
return "MyInterfaceImpl1-defaultMethod()";
}
}
接口静态方法
Java 8 引入了接口静态方法,该特性允许在接口中定义静态方法。
接口静态方法允许在接口中定义静态实用性工具类方法,这些方法与接口的功能相关,但是不依赖于实例,这对于提供该接口的通用方法或工具方法非常有用,可以减少代码重复性,提高代码的可维护性。
接口静态方法的使用和我们平常调用工具类一样的。
public interface MyInterface {
static String staticMethod() {
return "MyInterface-staticMethod";
}
}
@Test
public void test() {
System.out.println(MyInterface.staticMethod());
}
需要注意的是我们是无法在实现类重写接口静态方法的。
Java 8 新特性—Stream API 对元素流进行函数式操作
Java 8 中两个最为重要的的更新:第一个是 Lambda 表达式,另外一个就是 Stream API,这篇文章就来跟随大明哥彻底了解强大的 Stream API。
什么是 Stream API
Stream API 是 Java 8 引入的一个用于对集合数据进行函数式编程操作的强大的库。它允许我们以一种更简洁、易读、高效的方式来处理集合数据,可以极大提高 Java 程序员的生产力,是目前为止对 Java 类库最好的补充。
Stream API 的核心思想是将数据处理操作以函数式的方式链式连接,以便于执行各种操作,如过滤、映射、排序、归约等,而无需显式编写传统的循环代码。
下面是 Stream API 的一些重要概念和操作:
Stream****(流):
Stream是 Java 8 中处理集合的关键抽象概念,它是数据渠道,用于操作数据源所生成的元素序列。这些数据源可以来自集合(
Collection)、数组、
I/O操作等等。它具有如下几个特点:
Stream不会存储数据。Stream不会改变源数据对象,它返回一个持有结果的新的Stream。Stream操作是延迟执行的,这就意味着他们要等到需要结果的时候才会去执行。
中间操作:这些操作允许您在
Stream上执行一系列的数据处理。常见的中间操作有filter(过滤)、map(映射)、distinct(去重)、sorted(排序)、limit(截断)、skip(跳过)等。这些操作返回的仍然是一个 Stream。终端操作:终端操作是对流进行最终处理的操作。当调用终端操作时,流将被消费,不能再进行进一步的中间操作。常见的终端操作包括
forEach(遍历元素)、collect(将元素收集到集合中)、reduce(归约操作,如求和、求最大值)、count(计数)等。惰性求值:Stream 操作是惰性的,只有在调用终端操作时才会执行中间操作。这可以提高性能,因为只处理需要的数据。
为什么要用 Stream API
作为一个 CRUD Boy ,在实际开发中,我们的数据来源大多数都是基于数据库、文件等等,一般情况下这些数据都需要我们用 Java 程序来处理。这时有小伙伴就说,我用 for 循环就能很好的处理集合数据了,为什么偏要用 Stream API 呢?其实相比传统集合处理方式,Stream API 有很多优点:
- 简洁和可读性:Stream API 的链式操作使代码更加简洁、可读。
- 不可变性:Stream 操作不会修改原始数据,而是创建一个新的 Stream,确保了原始数据的不可变性,有助于并发编程。
- 惰性求值:Stream 操作是惰性的,只有在调用终端操作时才会触发中间操作的执行,提高了性能,因为只处理需要的数据。
- 并行处理:Stream API 支持并行处理数据,可以充分利用多核处理器,提高性能。
- 更高的效率:使用 Stream API 可以更快速地编写代码,因为它减少了样板代码的编写,同时提供了丰富的操作。
Stream 与集合的差异是:Stream 讲的是计算,而集合讲的是数据。
Stream 操作三部曲
一个完整的 Stream 操作包括三步
创建 Stream
首先我们需要一个 Stream 对象,常见的创建方式有:
- 使用集合的
stream()方法
在集合中有两个方法可以创建 Stream 对象:
default Stream<E> stream():返回一个顺序流
default Stream<E> parallelStream():返回一个并行流
- 通过数组
Arrays.stream(T[] array),将数组转换为 Stream 对象:
String[] array = {"死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty"};
Stream<String> stream = Arrays.stream(array);
- 使用
Stream.of(T... values)方法
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
这种方式适用于直接提供一组元素来创建Stream。
- 使用
Stream.builder()方法
Stream 提供了一个 builder() 方法来提供构建 Stream 的构造器:
Stream.Builder<String> builder = Stream.builder();
builder.accept("死磕 Java");
builder.accept("死磕 Java 并发");
builder.accept("死磕 Java 新特性");
builder.accept("死磕 Netty");
Stream<String> stream = builder.build();
这种方式适用于需要逐个添加元素到Stream中的情况。
Stream.generate()orStream.iterate(T seed, UnaryOperator<T> f)
这两个方法都是用于生成无限元素的Stream,需要通过limit()方法来限制元素数量。
Stream<String> stream = Stream.generate(() -> "a").limit(3);
这两个方法使用比较少。
中间操作
有了 Stream 对象,就可以在 Stream 上应用中间操作。
中间操作是一系列的操作,对数据源的数据进行处理,例如过滤、映射、排序、去重等等。注意这些操作不会立即执行,而是构建一个操作链。下表是 Stream 中常用中间操作方法。
| 方法名 | 描述 |
|---|---|
filter(Predicate<T> predicate) | 根据给定的谓词条件过滤元素。 |
map(Function<T, R> mapper) | 将元素通过给定的函数映射为另一个类型的元素。 |
flatMap(Function<T, Stream<R>> mapper) | 将每个元素映射为一个流,然后将这些流合并为一个流。 |
distinct() | 去除流中的重复元素。 |
sorted() | 对元素进行排序,默认按自然顺序排序。 |
sorted(Comparator<T> comparator) | 使用自定义比较器对元素进行排序。 |
limit(long maxSize) | 截取流中的前 maxSize 个元素。 |
skip(long n) | 跳过流中的前N个元素。 |
终端操作
做完中间操作后,我们需要调用一个终端操作来触发实际的数据处理。终端操作会遍历 Stream 并执行中间操作并产生结果。下表是一些常见的终端操作方法:
| 方法名 | 方法描述 |
|---|---|
forEach() | 对流中的每个元素执行指定的操作。 |
forEachOrdered() | 与forEach类似,但保留了元素的顺序。 |
toArray() | 将流中的元素收集到数组中。 |
reduce(accumulator) | 通过累积操作将流中的元素归约为单个结果。 |
reduce(identity, accumulator) | 使用初始值和累积操作将流中的元素归约为单个结果。 |
reduce(identity, accumulator, combiner) | 使用初始值、累积操作和组合操作将流中的元素归约为单个结果。 |
collect() | 将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为。 |
min(comparator) | 使用指定的比较器找到流中的最小元素。 |
max(comparator) | 使用指定的比较器找到流中的最大元素。 |
count() | 计算流中元素的数量。 |
anyMatch() | 检查流中是否有任何元素匹配指定的条件。 |
allMatch() | 检查流中的所有元素是否都匹配指定的条件。 |
noneMatch() | 检查流中是否没有元素匹配指定的条件。 |
findFirst() | 返回流中的第一个元素(如果存在),通常与filter操作一起使用。 |
findAny() | 返回流中的任意元素(如果存在),通常与filter操作一起使用。 |
Stream API 介绍
中间操作
筛选与切片
filter(Predicate<T> predicate):根据给定的谓词条件过滤元素。
filter() 接受一个谓词函数作为参数,该函数用于对流中的每个元素进行验证,只有满足谓词条件的元素才会被保留在新的流中,而不满足条件的元素将被过滤掉。
@Test
public void filterTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.filter(x -> x.endsWith("Netty"))
.forEach(System.out::println);
}
// 结果......
死磕 Netty
skip(long n):跳过流中的前N个元素。
skip() 通常用于分页或忽略前几个元素的场景。若流中元素不足 N 个,则返回空流。
@Test
public void skipTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.skip(2)
.forEach(System.out::println);
}
// 结果......
死磕 Java 新特性
死磕 Netty
limit(long maxSize):截取流中的前 maxSize个元素。
limit() 通常用于对流进行限制,以获取一定数量的元素,比如分页或筛选操作。如果 maxSize 大于流中元素的总数,那么 limit 方法将返回包含所有元素的新流,不会有任何元素被丢弃。
@Test
public void limitTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.limit(3)
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
distinct():去除流中的重复元素。
distinct() 依赖于元素的 equals() 来检查是否重复,因此对于自定义对象,需要确保正确实现了 equals() 和 hashCode() 方法以实现正确的去重功能。
@Test
public void distinctTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty","死磕 Java","死磕 Java 新特性");
stream.distinct()
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
死磕 Netty
映射
map(Function<T, R> mapper):将元素通过给定的函数映射为另一个类型的元素。
map() 会对流中的每个元素执行一个函数操作,将每个元素映射为另一个类型的元素,然后将映射后的元素作为新的流返回,通常用于数据转换和提取元素的属性。
@Test
public void mapTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.map(String::toUpperCase)
.forEach(System.out::println);
}
比如这个例子,将所有的元素全部转换为大写形式。
再比如,我们有一批学生列表,要获取年龄小于 6 岁所有小朋友的名字,去重:
@Test
public void mapTest() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
stream.filter(x -> x.getAge() < 6) // 过滤年龄小于6岁
.map(Student::getName) // 拿到所有学生的名字
.distinct() // 去重
.forEach(System.out::println);
}
// 结果......
梓涵
子涵
紫涵
map() 是非常有用的,它允许我们对流中的元素执行各种转换操作,如类型转换、属性提取等等,这使得在流处理中进行数据转换变得非常方便。
flatMap(Function<T, Stream<R>> mapper):将每个元素映射为一个流,然后将这些流合并为一个流。
flatMap() 通常用于将嵌套的集合结构扁平化,或者将元素进行扁平映射以进行处理。例如:
@Test
public void flatMapTest() {
List<List<String>> list = Arrays.asList(
Arrays.asList("死磕 Java","死磕 Java 并发"),
Arrays.asList("死磕 Java 基础"),
Arrays.asList("死磕 Java NIO","死磕 Netty"),
Arrays.asList("死磕 Redis","死磕 Spring"),
Arrays.asList("死磕 Java 新特性")
);
list.stream()
.flatMap(List::stream)
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 基础
死磕 Java NIO
死磕 Netty
死磕 Redis
死磕 Spring
死磕 Java 新特性
在这个例子中,flatMap() 接受一个 函数 List::stream,该函数将每个嵌套的集合转换为一个流,然后 flatMap() 将所有流合并成一个单一的流。
我们再来一个稍微复杂点的:
@Data
@AllArgsConstructor
public class User {
private String name;
private List<Order> orderList;
}
@Data
@AllArgsConstructor
public class Order {
private Integer id;
private String name;
}
@Test
public void flatMapTest1() {
List<User> users = Arrays.asList(
new User("张三", Arrays.asList(new Order(1, "iPhone 13"), new Order(2, "iPhone 14"))),
new User("李四", Arrays.asList(new Order(3, "MacBook Pro"))),
new User("王五", Arrays.asList(new Order(4, "iPad"), new Order(5, "MacBook Air")))
);
users.stream()
.flatMap(u -> u.getOrderList().stream())
.map(Order::getName)
.forEach(System.out::println);
}
// 结果......
iPhone 13
iPhone 14
MacBook Pro
iPad
MacBook Air
在这个示例中,flatMap() 首先将每个 User的 OrderList转换为一个流,然后使用 map() 提取订单的名称,最终将所有订单名称打印出来。
排序
sorted():对元素进行排序,默认按自然顺序排序。
sorted() 用于对流中的元素进行自然排序,要求流中的元素必须实现 Comparable 接口。
@Test
public void sortedTest() {
Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.sorted()
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
死磕 Netty
再如:
@Test
public void sortedTest1() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
// 排序
stream.sorted().forEach(System.out::println);
}
这个时候执行就会报错:
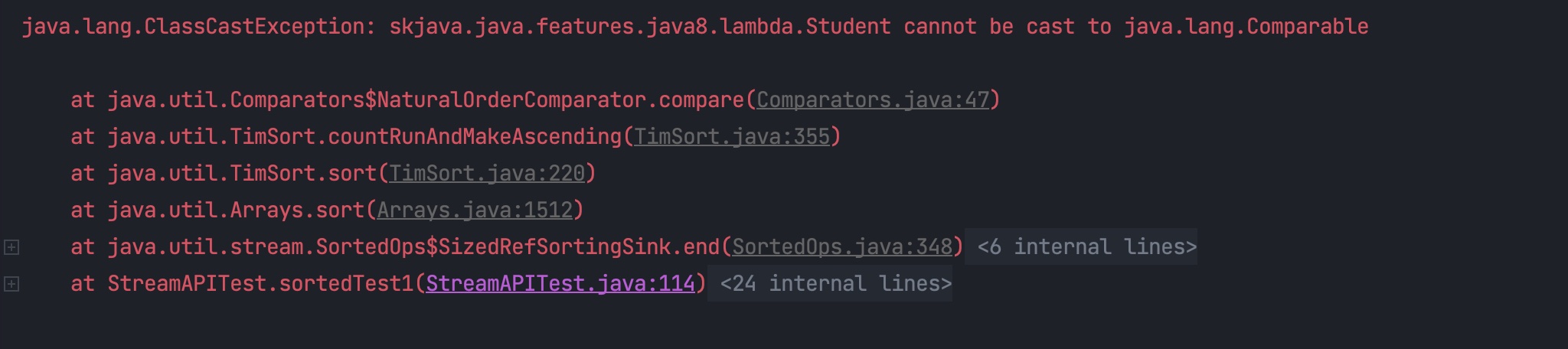
告诉你没有实现 java.lang.Comparable 接口。
sorted(Comparator<? super T> comparator):使用自定义比较器对元素进行排序。
该方法接受一个自定义的比较器Comparator,允许我们根据自定义规则对流中的元素进行排序。
@Test
public void sortedTest1() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
// 排序
stream.sorted(Comparator.comparing(Student::getAge)).forEach(System.out::println);
}
// 结果......
Student(name=子涵, age=4)
Student(name=梓涵, age=5)
Student(name=紫涵, age=5)
Student(name=梓涵, age=5)
Student(name=子晗, age=6)
Student(name=紫晗, age=6)
Student(name=梓晗, age=7)
终端操作
匹配与查找
allMatch():检查流中的所有元素是否都匹配指定的条件。
allMatch() 会遍历流中的每一个元素,检查每一个元素是否符合条件,如果全都符合条件,则返回 true,否则返回 false。如果流为空,则返回 true 。
@Test
public void allMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.allMatch(x -> x.startsWith("死磕"));
System.out.println(result);
}
// 结果......
true
anyMatch():检查流中是否有任何元素匹配指定的条件。
anyMatch() 遍历流中的每一个元素,检查每个元素是否符合条件,如果有一个满足条件则返回 true,否则返回 false。如果流为空,返回 false。
@Test
public void anyMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.anyMatch(x -> x.indexOf("Spring") > 0);
System.out.println(result);
}
// 结果......
false
noneMatch():检查流中是否没有元素匹配指定的条件。
noneMatch() 检查流中每个元素是否都不满足条件,如果都不满足返回 true,否则返回 false,如果为空,则返回 true。
@Test
public void noneMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.noneMatch(x -> x.indexOf("Spring") > 0);
System.out.println(result);
}
// 结果......
true
findFirst():返回流中的第一个元素(如果存在)
findFirst() 结果为Optional,如果流为空,findFirst() 返回的是一个包含null的Optional,否则包含第一个元素。
由于流有可能为无限流,所以 findFirst() 一般都会与其他操作一起使用,例如 filter(),找满足条件的第一个元素。
@Test
public void findFirstTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.indexOf("Java") > 0)
.findFirst();
System.out.println(result.orElse(""));
}
findAny():返回流中的任意元素(如果存在)
findAny() 与 findFirst() 相似,不同的是 findAny 不保证返回流中的第一个元素,而是返回任意一个满足条件的元素。
@Test
public void findAnyTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.contains("死磕"))
.findAny();
System.out.println(result.orElse(""));
}
min():找到流中的最小元素
@Test
public void minTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.min(String::compareTo);
System.out.println(result.orElse(""));
}
max():找到流中的最大元素
@Test
public void maxTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.max(String::compareTo);
System.out.println(result.orElse(""));
}
count():计算流中元素的数量。
count() 通常用于获取流中元素的数量,以便在需要时进行统计、计数或其他操作。
@Test
public void countTest() {
long result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.contains("Java"))
.count();
System.out.println(result);
}
forEach():对流中的每个元素执行指定的操作。
forEach() 主要用于遍历流中的每个元素,并对每个元素应用指定的操作。这可以用于执行各种自定义操作,例如打印元素、将元素存储到集合中等。
@Test
public void forEachTest() {
Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.forEach(x -> System.out.println(x + " 就是牛..."));
}
// 结果......
死磕 Java 新特性 就是牛...
死磕 Java 就是牛...
死磕 Netty 就是牛...
死磕 Java 并发 就是牛...
forEachOrdered():与forEach类似,但保留了元素的顺序。
forEachOrdered() 会保证元素的顺序不会发生变化 ,输出将按原始顺序产生。
@Test
public void forEachOrderedTest() {
List<String> list = Arrays.asList("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发");
System.out.println("================ forEach 结果 ================ ");
list.parallelStream().forEach(System.out::println);
System.out.println("================ forEachOrdered 结果 ================ ");
list.parallelStream().forEachOrdered(System.out::println);
}
// 结果......
================ forEach 结果 ================
死磕 Netty
死磕 Java 并发
死磕 Java 新特性
死磕 Java
================ forEachOrdered 结果 ================
死磕 Java 新特性
死磕 Java
死磕 Netty
死磕 Java 并发
从这个输出结果就可以看出两者的差异了吧?如果我们将 list.parallelStream().forEach(System.out::println); 调整为 list.stream().forEach(System.out::println); 则两个输出结果是一样的,因为 stream() 产生的是一个顺序流。
forEachOrdered() 通常在需要保持元素处理顺序的情况下使用,特别是在使用并行流时,以确保元素按照原始顺序进行处理。
归约
reduce(BinaryOperator<T> accumulator):归约为一个值(无初始值)
accumulator是一个BinaryOperator函数,用于定义归约操作,接受两个参数,合并它们并返回一个结果。比如我们要求1 ~ 10的和:
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Optional<Integer> optional = list.stream().reduce((a,b) -> a + b);
System.out.println(optional.orElse(0));
}
// 结果......
55
reduce(T identity, BinaryOperator<T> accumulator):归约为一个值,有初始值
identity是一个初始值,用作归约的起始值。
该方法从 identity 开始,将 accumulator 函数应用于流中的第一个元素和 identity,然后将结果作为下一个元素的 identity 继续,如此重复,直到所有元素都被处理,最后返回归约后的结果。如果流为空,则返回 identity作为最终结果。
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer reduce = list.stream().reduce(10,(a,b) -> a + b);
System.out.println(reduce);
}
// 结果......
65
T reduce(T identity, BinaryOperator<T> accumulator, BinaryOperator<T> combiner):归约为一个值(有初始值),并提供并行执行时的并行归约操作。
combiner是一个BinaryOperator函数,用于定义并行执行时如何合并归约的部分结果。
该方法用于在并行流的情况下执行归约操作。identity用作初始值,accumulator函数应用于流中的各个部分,然后combiner函数用于合并这些部分结果,最终得到一个归约后的结果。
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer reduce = list.parallelStream().reduce(0,(a,b) -> a + b,(a,b) -> a + b);
System.out.println(reduce);
}
收集
collect():将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为。
方法定义如下:
<R, A> R collect(Collector<? super T, A, R> collector)
R是收集操作的最终结果类型。A是中间累积类型,通常由Collector定义的累积器类型。Collector<? super T, A, R>是一个用于收集元素的Collector,它包含了四种操作:创建累积器、累积元素、合并中间结果和完成收集。它通常由Collectors工具类提供,用于执行常见的收集操作,例如收集到List、Set、Map等容器中,当然我们也可以使用自定义的Collector来执行复杂的收集操作。
另外,Java 8 提供了一个工具类:Collectors,它提供了一系列预定义的静态方法,这些方法可以用于执行各种常见的收集操作,包括将元素收集到列表、集合、映射、分组、统计等等,不需要我们编写复杂的自定义逻辑,是不是很人性化?静态方法如下:
| 方法名 | 描述 |
|---|---|
toList() | 将元素收集到一个List中。 |
toSet() | 将元素收集到一个Set中,去除重复元素。 |
toCollection(Supplier<C> collectionFactory) | 将元素收集到指定类型的集合,使用提供的工厂函数创建集合。 |
toMap(keyMapper, valueMapper) | 将元素收集到一个Map中,指定键和值的映射方式。 |
toMap(keyMapper, valueMapper, mergeFunction) | 将元素收集到一个Map中,指定键和值的映射方式,并提供冲突解决策略。 |
toConcurrentMap(keyMapper, valueMapper) | 将元素收集到一个并发ConcurrentMap中,指定键和值的映射方式。 |
toConcurrentMap(keyMapper, valueMapper, mergeFunction) | 将元素收集到一个并发ConcurrentMap中,指定键和值的映射方式,并提供冲突解决策略。 |
counting() | 计算元素的数量,并返回一个Long。 |
summingInt() | 对Integer属性进行求和。 |
summingLong() | 对Long属性进行求和。 |
summingDouble() | 对Double属性进行求和。 |
averagingInt() | 计算Integer属性的平均值。 |
averagingLong() | 计算Long属性的平均值。 |
averagingDouble() | 计算Double属性的平均值。 |
maxBy(comparator) | 找到最大元素,使用指定的比较器。 |
minBy(comparator) | 找到最小元素,使用指定的比较器。 |
joining() | 将元素拼接成一个字符串,可以指定分隔符、前缀和后缀。 |
mapping() | 对元素进行映射操作,然后将结果收集。 |
partitioningBy(predicate) | 将元素根据给定条件分成两个部分,返回一个Map<Boolean, List<T>>。 |
partitioningBy(predicate, downstream) | 将元素根据给定条件分成两个部分,并对每个部分应用另一个收集器。 |
groupingBy(classifier) | 将元素按照给定的分类器分组,返回一个Map<K, List<T>>。 |
groupingBy(classifier, downstream) | 将元素按照给定的分类器分组,并对每个组应用另一个收集器。 |
collect() 配合 Collectors 使对流中的元素进行灵活的收集和处理变得非常方便,适用于各种数据处理需求。使用技巧很多,大明哥就不列举了,在下篇文章大明哥会列举一些常见使用技巧。
示例
上面大明哥对 Stream 做了一个非常详细的介绍,几乎每个方法都做了说明和举例了,但是这些例子都是比较简单的,而且 API 都是单独使用,然而在实际开发过程中,我们大部分都需要用 Stream 来处理一些复杂的场景,所以下面大明哥用几个复杂点的示例来教你如何正确使用 Stream,玩转集合 的筛选、归约、分组、聚合等操作。
案例使用的基础数据
定义两个类。
- 班级类
@Data
@AllArgsConstructor
public class Class {
/**
* 班级名称
*/
private String name;
/**
* 学生
*/
private List<Student> students;
}
- 学生
@Data
@AllArgsConstructor
public class Student {
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private String gender;
/**
* 成绩
*/
private Integer grade;
}
- 样例数据
public List<Class> getClassList() {
List<Student> students1 = Arrays.asList(
new Student("张三", 18, "男", 456),
new Student("李四", 17, "女", 432),
new Student("王五", 16, "男", 368),
new Student("小红", 18, "女", 511),
new Student("小明", 17, "男", 517)
);
List<Student> students2 = Arrays.asList(
new Student("小丽", 16, "女", 554),
new Student("刘六", 18, "男", 587),
new Student("陈七", 17, "男", 502),
new Student("赵八", 16, "男", 498)
);
List<Student> students3 = Arrays.asList(
new Student("林九", 18, "女", 356),
new Student("郑十", 17, "男", 411),
new Student("孙十一", 16, "男", 435),
new Student("吴十二", 18, "女", 389),
new Student("朱十三", 17, "女", 490),
new Student("许十四", 16, "男", 543)
);
List<Student> students4 = Arrays.asList(
new Student("何十五", 18, "女", 612),
new Student("胡十六", 17, "男", 698) ,
new Student("王十七", 16, "女", 687),
new Student("黄十八", 18, "男", 665),
new Student("马十九", 17, "男", 701),
new Student("周二十", 16, "女", 711),
new Student("郭二一", 18, "男", 689)
);
List<Student> students5 = Arrays.asList(
new Student("林二二", 17, "男", 567),
new Student("吴二三", 16, "男", 587),
new Student("谢二四", 18, "女", 687),
new Student("胡二五", 17, "女", 598),
new Student("何二六", 16, "男", 654),
new Student("王二七", 18, "女", 512),
new Student("徐二八", 17, "男", 633),
new Student("刘二九", 16, "女", 632)
);
return Arrays.asList(
new Class("一班",students1),
new Class("二班",students2),
new Class("三班",students3),
new Class("四班",students4),
new Class("五班",students5)
);
}
01、获取一班中学生的平均年龄
@Test
public void test1() {
double age = getClassList().stream()
.filter(x -> x.getName().equals("一班")) // 过滤一班
.flatMap(cl -> cl.getStudents().stream()) // 获取一班的学生
.mapToInt(Student::getAge) // 拿到一班学生的年龄
.average() // 求平均值
.orElse(0);
System.out.println(age);
}
// 结果......
17.2
首先通过 filter() 将“一班”过滤出来,然后通过 flatMap() 获取“一班”的学生列表,最后 average() 求平均值,由于 average() 返回的 OptionalDouble,利用 orElse(0) 转换下就可以了
02、找出所有班级中的学生中的最高分数
@Test
public void test2() {
Integer maxGrade = getClassList().parallelStream()
.flatMap(cl -> cl.getStudents().stream()) //获取所有班级的所有学生列表
.max(Comparator.comparing(Student::getGrade)) //获取成绩最高的学生
.map(Student::getGrade) // 得到该成绩
.orElse(0);
System.out.println(maxGrade);
}
// 结果......
711
这里创建 Stream 使用的是 parallelStream()。利用 flatMap() 获取所有班级的所有学生,max() 得到分数最高的学生,最后利用 map() 提取这个最高分。
03、获取所有班级中的学生的数量
@Test
public void test3() {
long count = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.count();
System.out.println(count);
}
// 结果......
30
还可以改成这种方式:
@Test
public void test3() {
long count = getClassList().stream()
.mapToLong(cl -> cl.getStudents().size())
.sum();
System.out.println(count);
}
04、获取所有学生中的男女数量
@Test
public void test4() {
Map<String,Long> genderMap = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.collect(Collectors.groupingBy(Student::getGender,Collectors.counting()));
System.out.println(genderMap);
}
// 结果......
{女=13, 男=17}
采用 Collectors.groupingBy() 根据性别分组,然后再利用 collect() 收集。
05、统计每个班级的男女数量
@Test
public void test5() {
Map<String,Map<String,Long>> genderMap = getClassList().stream()
.collect(Collectors.toMap(Class::getName,
cl -> cl.getStudents().stream()
.collect(Collectors.groupingBy(Student::getGender,Collectors.counting()))));
System.out.println(genderMap);
}
// 结果......
{五班={女=4, 男=4}, 一班={女=2, 男=3}, 四班={女=3, 男=4}, 二班={女=1, 男=3}, 三班={女=3, 男=3}}
这个例子稍微有点儿复杂,要分两次分组,第一次按班级来,第二次按性别来。
06、找出所有班级中成绩前10名的学生
@Test
public void test6() {
List<Student> students = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.sorted(Comparator.comparing(Student::getGrade).reversed()) // 根据成绩排序
.limit(10) // 获取前 10 名
.collect(Collectors.toList());
System.out.println(students);
}
// 结果......
[Student(name=周二十, age=16, gender=女, grade=711), Student(name=马十九, age=17, gender=男, grade=701), Student(name=胡十六, age=17, gender=男, grade=698), Student(name=郭二一, age=18, gender=男, grade=689), Student(name=王十七, age=16, gender=女, grade=687), Student(name=谢二四, age=18, gender=女, grade=687), Student(name=黄十八, age=18, gender=男, grade=665), Student(name=何二六, age=16, gender=男, grade=654), Student(name=徐二八, age=17, gender=男, grade=633), Student(name=刘二九, age=16, gender=女, grade=632)]
sorted() 按照成绩排序,要倒序,所以使用 reversed() 来逆序下,最后 limit() 获取前 10 个用户。
07、找出每个班级成绩前 3 名的学生
@Test
public void test7() {
Map<String,List<Student>> result = getClassList().stream()
.collect(Collectors.toMap(Class::getName,
cl -> cl.getStudents().stream()
.sorted(Comparator.comparing(Student::getGrade).reversed())
.limit(3)
.collect(Collectors.toList())));
System.out.println(result);
}
// 结果......
{五班=[Student(name=谢二四, age=18, gender=女, grade=687), Student(name=何二六, age=16, gender=男, grade=654), Student(name=徐二八, age=17, gender=男, grade=633)], 一班=[Student(name=小明, age=17, gender=男, grade=517), Student(name=小红, age=18, gender=女, grade=511), Student(name=张三, age=18, gender=男, grade=456)], 四班=[Student(name=周二十, age=16, gender=女, grade=711), Student(name=马十九, age=17, gender=男, grade=701), Student(name=胡十六, age=17, gender=男, grade=698)], 二班=[Student(name=刘六, age=18, gender=男, grade=587), Student(name=小丽, age=16, gender=女, grade=554), Student(name=陈七, age=17, gender=男, grade=502)], 三班=[Student(name=许十四, age=16, gender=男, grade=543), Student(name=朱十三, age=17, gender=女, grade=490), Student(name=孙十一, age=16, gender=男, grade=435)]}
Java 8 新特性—类型注解
注解,我相信小伙伴应该都使用过,Java 从 Java 5 开始引入该特性,发展到现在已经是遍地开花了,且在很多框架都得到了广泛的使用,用来简化程序中的配置。
但是,在 Java 8 之前,注解仅能用于声明(如方法、类、字段)。这意味着注解无法直接应用于类型本身(例如,方法的返回类型、变量的类型等等)。这种限制减少了注解在代码分析、检查及处理中的潜在用途(虽然不会产生什么问题)。为了提升注解的功能,使其能够更全面地支持各种编程场景(如增强静态代码分析、提供更丰富的编译时检查等等),Java 8 引入了类型注解。
类型注解可以用在哪些地方?
类型注解扩展了注解的应用范围,使其不仅能应用于声明,还能应用于任何使用类型的地方,包括:
1、泛型类型参数
可以在泛型类型中使用注解,如:
List<@NonNull String> strings = new ArrayList<>();
@NonNull 注解表示列表中的字符串不应该为 null。
2、类型转换
在类型转换表达式中使用注解,如:
Object obj = "skjava.com";
String str = (@NonNull String) obj;
将一个对象转换为字符串,并通过 @NonNull 注解标明转换后的字符串不能为 null。
实现语句
在实现接口或扩展类时使用注解,如:
class CustomList implements @ReadOnly List<String> {
// ...
}
@ReadOnly 表示这个实现List接口的 CustomList 是只读的。
方法或构造器的返回类型
方法声明的返回类型前可以添加注解,如:
public @Positive int getPositiveNumber() {
return 42;
}
@Positive 注解表示这个方法应该返回一个正数。
异常声明
在方法抛出的异常类型上也可以添加注解,如:
public void readFile(String path) throws @Critical IOException {
// ...
}
@Critical 注解被用于标记抛出的 IOException 是关键的,可能需要特别处理。
局部变量
@NonNull String skjava = "死磕 Java 新特性";
@NonNull 注解声明局部变量 skjava 不会为 null。
方法或构造器的参数
public void doSomething(@NonEmpty List<String> list) {
// ...
}
@NonEmpty 注解表明方法参数 list 应该是一个非空的列表。
类的实例化
MyObject myObject = new @Interned MyObject();
@Interned 注解可以用来指示 MyObject 的这个实例应该被内部化(interning)处理。
类型注解有什么作用?
Java 8 引入类型注解的主要目的是增强 Java 的类型检查能力,提供更加丰富的代码分析工具,同时帮助避免常见的错误。它的作用包括但不限于数据校验、类型检查、代码分析等等。例如下面一个例子利用类型注解来避免空指针异常:
@Test
public void test() {
printLength("skjava.com");
printLength(null);
}
public void printLength(@NonNull String str) {
System.out.println(str.length());
}
在这个例子中,printLength() 的参数 str被标记为 @NonNull。这意味着在编译时,编译器会检查是否有可能传入一个 null 值。如果有这样的可能性,编译器可以生成一个警告或错误,从而防止可能的 NullPointerException,例如在 idea 中会有这个告警:
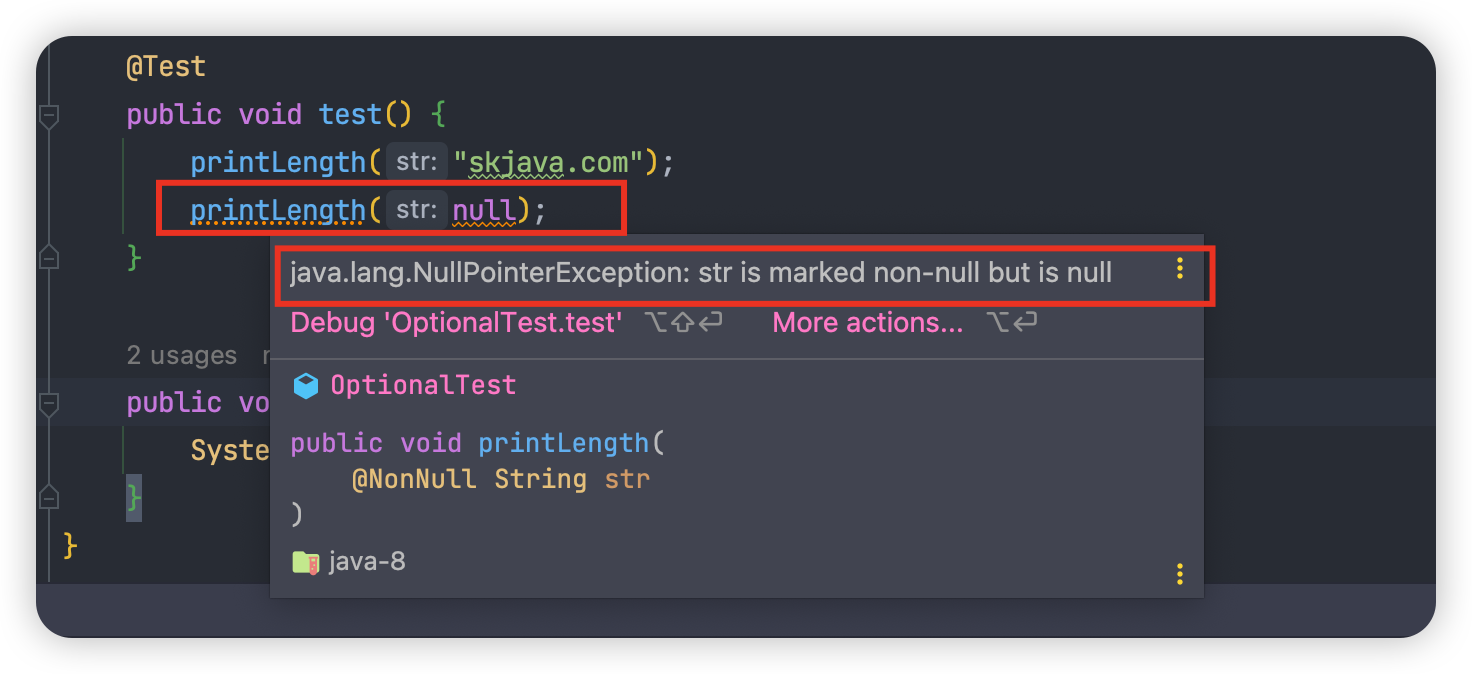
通过使用类型注解,我们可以在编写代码的时候就避免潜在的运行时错误,增强代码的健壮性。
虽然使用类型注解有这些优点,但是它会增加代码的复杂度,如果过度使用或使用不当,类型注解可能会使代码变得更加复杂和难以理解,不如这段代码:
@NotEmpty List<@NonNull String> strings = new ArrayList<@NonNull String>()>
看着就脑袋痛,所以该特性我们需要适当使用,但是在一些核心场景,容易出错的地方,尤其是参数类型检查,大明哥还是推荐使用,可以带来很大的便利。
Java 8 新特性—类型推断优化
理解泛型
在讨论类型推断之间,我们有必要先理解下泛型。
泛型是 Java 1.5 引入的特性,主要目的是增强 Java 程序的类型安全性,同时提高代码的重用性和可读性。比如,在泛型引入之前,所有的集合都是保存 Object 类型的,很容易意外地将错误类型的对象放入集合中,这可能导致运行时异常。
List list = new ArrayList();
list.add("skjava.com");
list.add(1234);
同时,从集合中取出的对象也是 Object 类型的,需要我们显式强制转换为适当的类型:
String str = (String) list.get(0);
通过引入泛型可以解决这两个问题:
- 泛型通过在编译时提供类型检查,能够减少因为存放错误类型的错误。比如:
List<String> list = new ArrayList<String>();
list.add("skjava.com");
list.add(1234); // 这是错误的,1234 不为 String 类型
- 泛型消除显示的强制类型转换,因为编译器能够自动地处理类型转换的细节,比如:
String str = list.get(0); //不需要再强制类型转换了
当然,除了集合外,泛型还能够泛化方法和类,我们可以创建泛型类或泛型方法,它们可以使用多种类型而不是单一的类型。这样就增加了代码的灵活性和可重用性。
泛型虽好,但是它有一个坑,就是每次定义时都要写明泛型的类型,显得非常冗余,比如:
List<String> list = new ArrayList<String>();
list.add("skjava.com");
我明明在定义变量的时候就已经指明了参数类型,为什么在初始化的时候还要我指定呢?这不显得多余吗?
Java 7 类型推断优化
Java 7 为了解决这个冗余的问题,引入“钻石操作符”(即 <>)用来简化泛型实例的创建过程。钻石操作符 <> 允许编译器根据上下文推断出泛型的类型,从而避免了重复的类型声明。比如:
List<String> list = new ArrayList<String>();
可以优化为:
List<String> list = new ArrayList<>();
在这里,new ArrayList<> 中的 <> 操作符使得编译器能够自动推断出其类型为 String。
一定要注意new ArrayList 后面的“<>”,只有加上这个“<>”才表示是自动类型推断,否则就是非泛型类型的 ArrayList,并且在使用编译器编译源代码时会给出一个警告提示。
但是 Java 7 的类型推断还是有缺陷:
- 只有构造器的参数化类型在上下文中被显著的声明了,才可以使用类型推断,否则不行,例如:
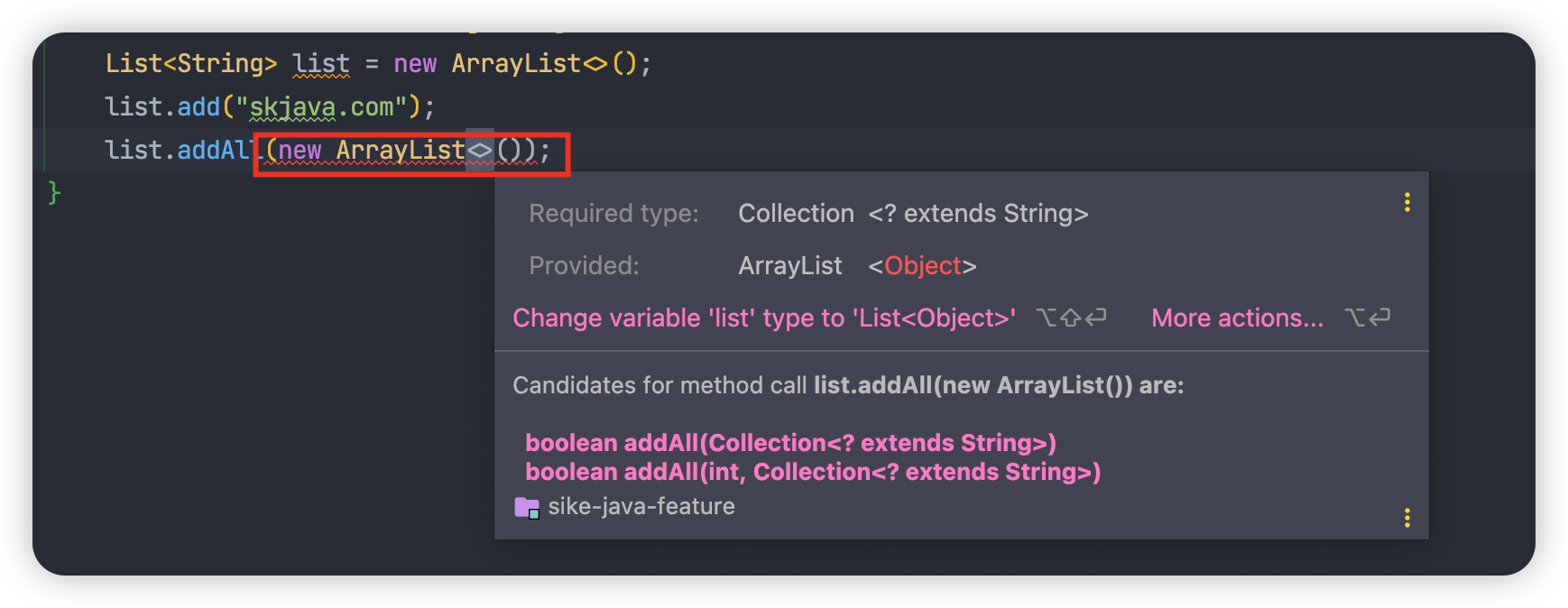
这里 new ArrayList<>() 需要明确指定类型:
List<String> list = new ArrayList<>();
list.add("skjava.com");
list.addAll(new ArrayList<String>());
Java 8 类型推断优化
为了简化代码的编写,减少冗余信息以及 Lambda 表达式,Java 8 对类型推断进行进一步的优化,主要内容有:
- 与 Lambda 表达式和方法引用的协同
- Stream API 中的应用
与 Lambda 表达式和方法引用的协同
Java 8 引入 Lambda 表达式极大地简化代码代码量和代码结构,标志着 Java 向函数式编程迈出了重要的第一步。而简写 Lambda 表示的一个依据就是类型推断,它允许编译器根据上下文自动推断 Lambda 表达式的参数类型,它分为目标类型推断和参数类型推断。
更多关于 Lambda 表达式的请阅读:Java 8 新特性—Lambda 表达式
Stream API 中的应用
Java 8 引入 Stream API 极大地提高了 Java 对集合的操作能力,类型推断使得在使用 Stream API 时让代码更加简介和阅读,比如,不使用类型推断:
Stream<String> stream = list.stream();
stream.filter((String s) -> s.startsWith("sike"));
使用类型推断的写法:
list.stream().filter(s -> s.startsWith("sike"));
在这里,编译器能够从上下文推断出 s 的类型是 String。
Stream API 支持的链式操作,类型推断在这里也发挥着重要作用,使得这些链式调用更加简洁:
List<String> filteredList = list.stream()
.filter(s -> s.startsWith("sike"))
.map(String::toUpperCase)
.collect(Collectors.toList());
filter、map 和 collect 操作形成了一个操作链,每个操作的输出类型自动成为下一个操作的输入类型,无需显式指定。你说,如果这里需要强制转换得要多麻烦?
Java 8 新特性—全新的、标准的 Base64 API
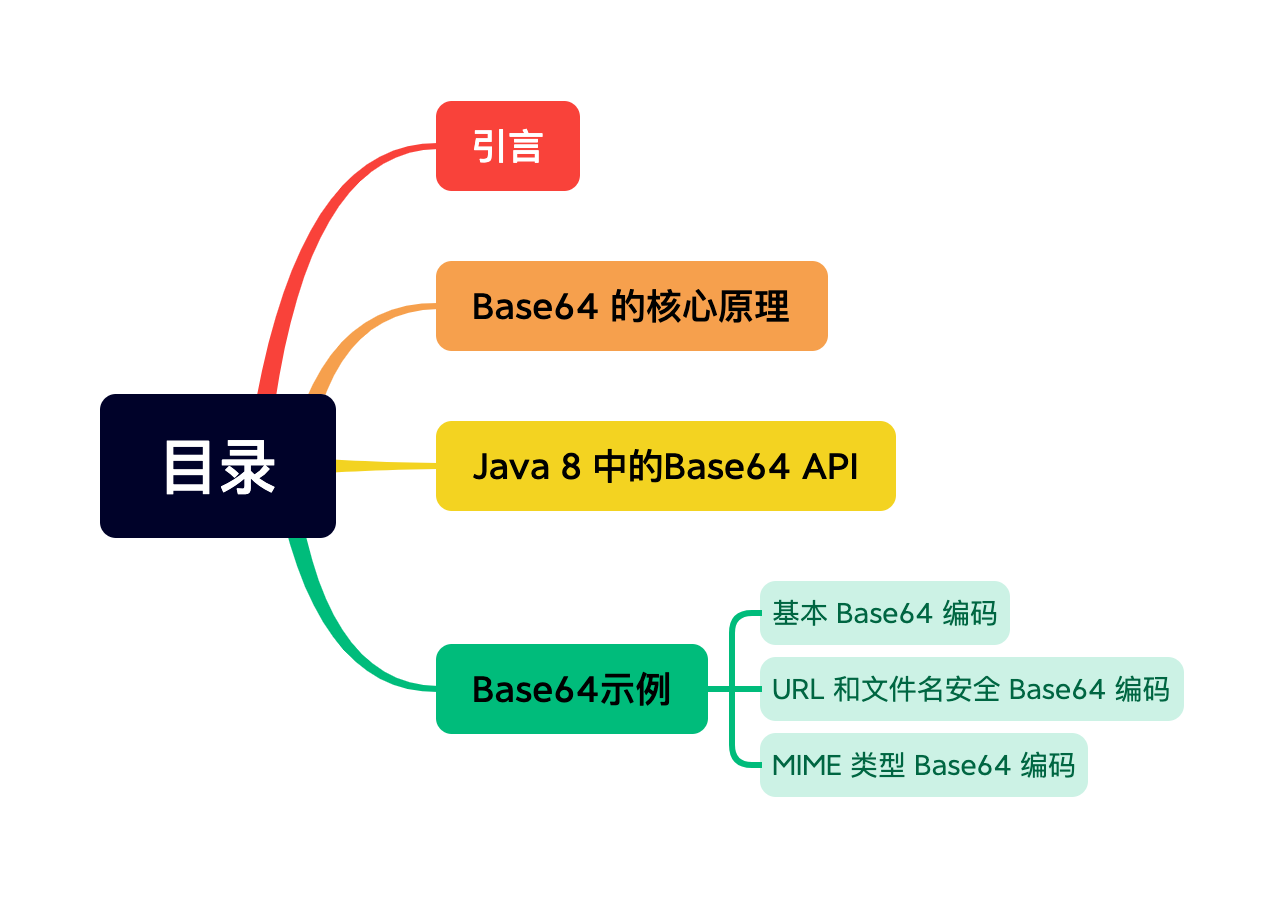
引言
Base64编码是一种用64个字符表示二进制数据的方法,它使用一组64个可打印字符来表示二进制数据,每6个比特位为一个单元,对应某个可打印字符。注意它并不是一种加密算法,所以Base64常用于在不支持二进制数据的系统间传输二进制数据。
但是,Java 8 之前并不支持 Base64,我们需要依赖第三方库如Apache Commons Codec或者在JDK内部类sun.misc.BASE64Encoder和sun.misc.BASE64Decoder等不推荐使用的方式来实现Base64编码解码。
为了能够提供一个更加标准的、更加安全的方法来进行Base64的编码和解码操作,使得开发者们不再需要依赖外部库,Java 8 引入全新的 Base64,同时为了提供更好的性能,Java 为 Base64 的实现做了专门的性能优化。
Base64 的核心原理
在了解 Java 8 中 Base64 API 之前,我们先看 Base64 的实现原理。
Base64 的核心思想是将数据流的每三个字节划分为一组,总共24位,再将这24位分为4组,每组6位。由于每组现在只有6位,因此它可以表示的最大数值是 2^6 - 1 = 63,Base64编码正是利用这64个数字(从0到63)对应到可打印字符的映射关系来工作的。
Base64 编码的步骤如下:
- 分组:输入数据被分成每组3字节(24位)。如果最后一组不足3字节,则用0填充至3字节。
- 映射:每组24位被进一步划分为4个6位的小组。每个6位小组将被映射为一个0-63之间的数字。
- 编码表:这些数字用作Base64编码表中的索引,该表由64个字符组成,包括大小写英文字母、数字和两个额外符号(通常是
+和/),还有一个用于填充的=符号,以确保输出的字符数为4的倍数。 - 转换:每个6位的分组对应的数字转换成相应的Base64字符。
- 填充:如果原始数据字节长度不是3的倍数,最终的编码可能会用
=字符填充至4的倍数长度,这样接收方在解码时能够恢复原始数据。
编码表如下:
| 数值 | 字符 | 数值 | 字符 | 数值 | 字符 | 数值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
有了这个映射表我们就把任意的二进制转换成Base64的编码了,下面大明哥举个例子给大家演示下转换过程。我们将 sikejava 字符串转换为 Base64 编码
步骤1:将字符转换为ASCII值
将每个字符转换为对应一个ASCII值。
s->115i->105k->107e->101j->106a->97v->118a->97
步骤2:将ASCII值转换为二进制
将每个ASCII值转换为8位二进制数。
115->01110011105->01101001107->01101011101->01100101106->0110101097->01100001118->0111011097->01100001
串连起来就是:01110011 01101001 01101011 01100101 01101010 01100001 01110110 01100001
步骤3:将二进制数据划分为6位一组
将连续的二进制位分成6位一组的小块。如果最后一组不足6位,需要用0填充。
上面二进制分为 6 位一组:011100 110110 100101 101011 011001 010110 101001 100001 011101 100110 000100
步骤 4:将6位二进制数转换为十进制
每组6位的二进制数将被转换成十进制数。
011100->28110110->54100101->37101011->43011001->25010110->22101001->41100001->33011101->29100110->38000100->4
步骤5:将十进制数映射到Base64字符
28->c54->237->l43->r25->Z22->W41->p33->h29->d38->m4->E
所以,"sikejava"对应的Base64编码是 c2lrZWphdmE=。最后的=符号用于填充,因为Base64编码的输出应该是4的倍数。
我们用代码验证下 :
System.out.println(Base64.getEncoder().encodeToString("sikejava".getBytes()));
// 结果......
c2lrZWphdmE=
Java 8 中的Base64 API
Java 8 中的 Base64 API 提供了三种主要类型的 Base64 编码和解码,他们分别适用于不同的场景和需求。
基本 Base64 编码和解码
- 编码器: 使用
Base64.getEncoder()获取。 - 解码器: 使用
Base64.getDecoder()获取。
它们提供了基本的 Base64 编码和解码功能,适用于所有需要 Base64 编码的场景。其特点是输出编码字符串不会包含用于换行的字符。
URL 和文件名安全 Base64 编码和解码
- 编码器: 使用
Base64.getUrlEncoder()获取。 - 解码器: 使用
Base64.getUrlDecoder()获取。
该编解码器适用于 URL 和文件名的 Base64 编码。由于 URL 中的某些字符(如 + 和 /)有特殊含义,所以需要使用这种编码方式来替换这些字符。使用该编码器,编码输出中的 + 和 / 字符分别被替换为 - 和 _,使得编码后的字符串可以安全地用在 URL 和文件名中。
MIME 类型 Base64 编码和解码
- 编码器: 使用
Base64.getMimeEncoder()获取。 - 解码器: 使用
Base64.getMimeDecoder()获取。
该编码器适用于 MIME 类型(如电子邮件)的内容,其中可能需要支持多行输出。特点是持按照 MIME 类型的要求将输出格式化为每行固定长度的多行字符串。默认每行长度不超过 76 个字符,并在每行后插入 \r\n。
Base64 提供了多种编解码的方法,大明哥这里列举几个最常用的:
encode(byte[] src): 将给定的字节数组编码为 Base64 字符串。encodeToString(byte[] src): 将给定的字节数组编码为一个 Base64 字符串,并将其直接转换为字符串格式。decode(String src): 将给定的 Base64 字符串解码为字节数组。decode(byte[] src): 将给定的 Base64 编码的字节数组解码为原始字节数组。
Base64示例
基本 Base64 编码
基本编码是最常见的类型,适用于大多数需要 Base64 编码的场景。
@Test
public void base64BasicTest() {
String skStr = "skjava";
// 编码
String encodingStr = Base64.getEncoder().encodeToString(skStr.getBytes());
System.out.println("encodingStr = " + encodingStr);
// 解码
String decodeStr = new String(Base64.getDecoder().decode(encodingStr));
System.out.println("decodeStr = " + decodeStr);
}
// 结果......
encodingStr = c2tqYXZh
decodeStr = skjava
URL 和文件名安全 Base64 编码
URL和文件名安全编码会替换掉一些在 URL 中可能会引起问题的字符,比如 + 和 /。
@Test
public void base64UrlTest() {
String skStr = "https://skjava.com/?series=skjava";
// 编码
String encodingStr = Base64.getUrlEncoder().encodeToString(skStr.getBytes());
System.out.println("encodingStr = " + encodingStr);
// 解码
String decodeStr = new String(Base64.getUrlDecoder().decode(encodingStr));
System.out.println("decodeStr = " + decodeStr);
}
// 结果......
encodingStr = aHR0cHM6Ly9za2phdmEuY29tLz9zZXJpZXM9c2tqYXZh
decodeStr = https://skjava.com/?series=skjava
MIME 类型 Base64 编码
MIME 类型编码适用于电子邮件或其他 MIME 类型的内容,它支持多行输出。
@Test
public void base64MimeTest() {
String skStr = "Hello, MIME-Type Example。\r\n" +
"sike-java,sike-java-feature;" +
"sike-javanio,sike-netty";
// 编码
String encodingStr = Base64.getMimeEncoder().encodeToString(skStr.getBytes());
System.out.println("encodingStr = " + encodingStr);
// 解码
String decodeStr = new String(Base64.getMimeDecoder().decode(encodingStr));
System.out.println("decodeStr = " + decodeStr);
}
// 结果......
encodingStr = SGVsbG8sIE1JTUUtVHlwZSBFeGFtcGxl44CCDQpzaWtlLWphdmEsc2lrZS1qYXZhLWZlYXR1cmU7
c2lrZS1qYXZhbmlvLHNpa2UtbmV0dHk=
decodeStr = Hello, MIME-Type Example。
sike-java,sike-java-feature;sike-javanio,sike-netty
文章标签:[Java 新特性](https://www.skjava.com/label?labelName=Java 新特性)[Java 8 新特性](https://www.skjava.com/label?labelName=Java 8 新特性)