JVM 垃圾回收
JVM 垃圾回收
一、介绍
1.1 什么是JVM
Java Virtual Machine Java程序的运行环境
1.2 学习路线
类加载器 -> JVM内存结构 -> 执行引擎
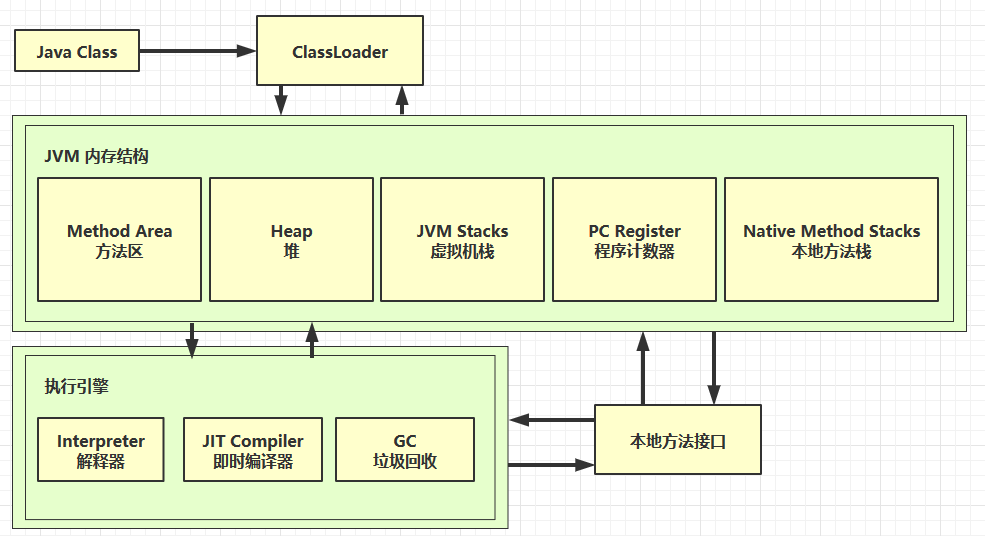
二、JVM内存结构
博客:(41条消息) 一文搞懂JVM内存结构_xiaokanfuchen86的博客-CSDN博客_jvm内存结构
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分为若干个不同的数据区域。每个区域都有各自的作用。
分析 JVM 内存结构,主要就是分析 JVM 运行时数据存储区域。JVM 的运行时数据区主要包括:堆、栈、方法区、程序计数器等。而 JVM 的优化问题主要在线程共享的数据区中:堆、方法区。
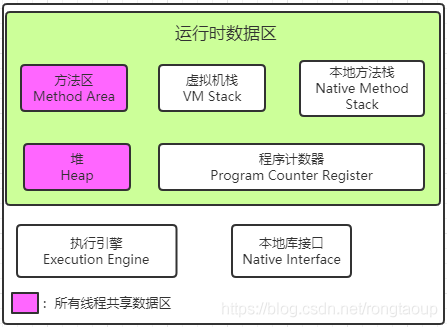
2.1 程序计数器
Program Counter Register 程序计数器(寄存器)
作用,是记住下一条jvm指令的执行地址
特点
是线程私有的
不会存在内存溢出
下面给出一个例子:
0: getstatic #20 // PrintStream out = System.out;
3: astore_1 // --
4: aload_1 // out.println(1);
5: iconst_1 // --
6: invokevirtual #26 // --
9: aload_1 // out.println(2);
10: iconst_2 // --
11: invokevirtual #26 // --
14: aload_1 // out.println(3);
15: iconst_3 // --
16: invokevirtual #26 // --
19: aload_1 // out.println(4);
20: iconst_4 // --
21: invokevirtual #26 // --
24: aload_1 // out.println(5);
25: iconst_5 // --
26: invokevirtual #26 // --
29: return
以上代码的右侧是Java的源代码,左侧是二进制字节码,JVM的指令
JVM的执行流程:
JVM指令 -> 解释器 -> 机器码 -> CPU
程序计数器(Program Counter Register)是一块较小的内存空间,可以看作是当前线程所执行字节码的行号指示器,指向下一个将要执行的指令代码,由执行引擎来读取下一条指令。更确切的说,一个线程的执行,是通过字节码解释器改变当前线程的计数器的值,来获取下一条需要执行的字节码指令,从而确保线程的正确执行。
为了确保线程切换后(上下文切换)能恢复到正确的执行位置,每个线程都有一个独立的程序计数器,各个线程的计数器互不影响,独立存储。也就是说程序计数器是线程私有的内存。
如果线程执行 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果执行的是 Native 方法,计数器值为Undefined。
程序计数器不会发生内存溢出(OutOfMemoryError即OOM)问题。
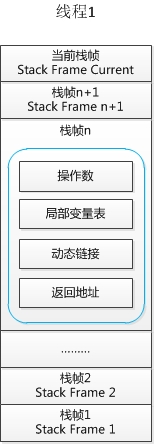
2.2 虚拟机栈
定义
Java Virtual Machine Stacks (Java 虚拟机栈)
线程私有的
每个线程运行时所需要的内存,称为虚拟机栈
每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
栈帧是栈的元素。每个方法在执行时都会创建一个栈帧。栈帧中存储了局部变量表、操作数栈、动态连接和方法出口等信息。每个方法从调用到运行结束的过程,就对应着一个栈帧在栈中压栈到出栈的过程。
JVM虚拟机栈的大小可以通过参数来指定 -Xss size
默认的单位是字节,也可以指定单位,如KB(k,K)、MB(m,M)、GB(g,G)
-Xss1m
-Xss1024KB
栈的大小决定了函数调用的最大深度,如果函数调用的深度大于设置的Xss大小,那么将会抛“java.lang.StackOverflowError“ 异常。
默认的情况下,栈的大小是1024KB(windows系统例外,大小依赖于虚拟内存)
面试题:
垃圾回收是否涉及栈内存?
不需要,栈内存随着栈针的出栈而自动回收掉,所以不需要垃圾回收器来管理。
占内存分配的越大越好么?
占内存过大会导致单线程占用的内存过大,总的线程数变少,不建议调整,使用默认即可。
方法的局部变量是否线程安全?
局部变量是线程私有的,不存在线程安全问题。
虚拟机栈和本地方法栈的区别?
Java 虚拟机栈为 JVM 执行 Java 方法服务,本地方法栈则为 JVM 使用到的 Native 方法服务。
案例1:CPU占用过多
定位过程:
用top定位哪个进程对cpu的占用过高
ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
jstack 进程id。可以根据线程id 找到有问题的线程,进一步定位到问题代码的源码行号
这里注意一下,ps输出的线程号是十进制的,jstack输出的线程编号是十六进制的。
案例2:程序运行很长时间没有结果
2.3 本地方法栈
线程私有。为虚拟机使用到的Native 方法服务。如Java使用c或者c++编写的接口服务时,代码在此区运行。
2.4 堆
堆的作用是存放对象实例和数组。通过new关键字创建的对象,都会使用堆内存。
特点:
- 它是线程共享的,堆中的对象都需要考虑线程安全问题
- 有垃圾回收机制
参数控制:
- -Xms设置堆的最小空间大小。-Xmx设置堆的最大空间大小。
异常情况:
- 如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError 异常
2.5 方法区
方法区同 Java 堆一样是被所有线程共享的区间,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码。在JVM启动时被创建。更具体的说,静态变量+常量+类信息(版本、方法、字段等)+运行时常量池存在方法区中。常量池是方法区的一部分。
方法区在逻辑上是堆的一部分,但在具体实现上不强制方法区的位置,不同的虚拟机厂 商可以有不同的实现,如 JDK1.8 之前使用永久代实现,1.8 后使用元空间实现
注:JDK1.8 使用元空间 MetaSpace 替代方法区,元空间并不在 JVM中,而是使用本地内存。元空间两个参数:
- MetaSpaceSize:初始化元空间大小,控制发生GC阈值
- MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
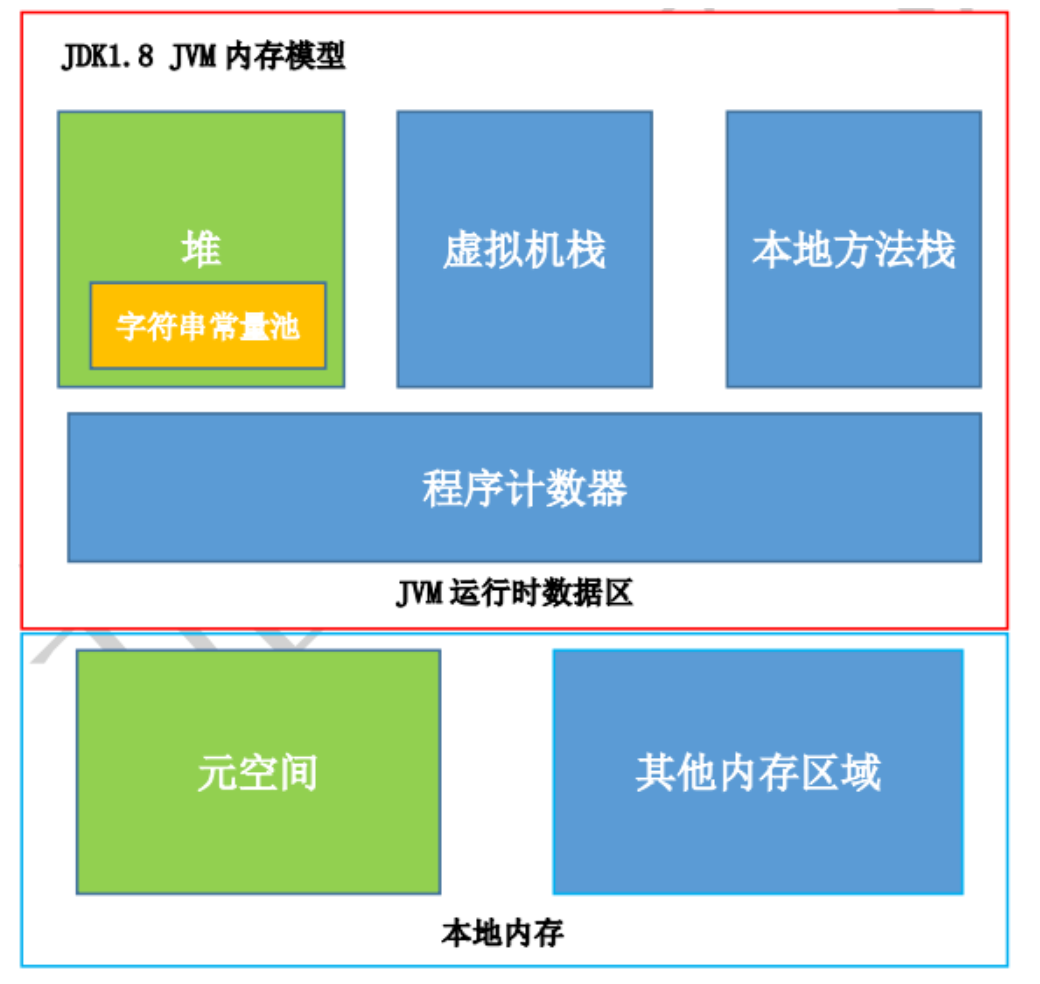
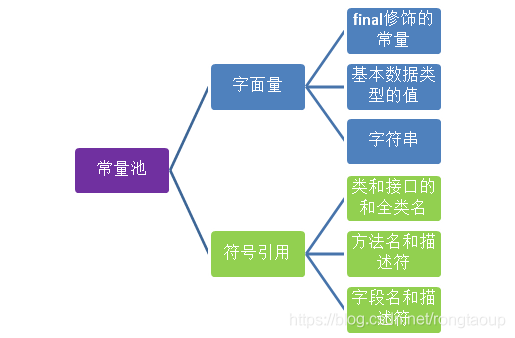
常量池
常量池中存储编译器生成的各种字面量和符号引用。字面量就是Java中常量的意思。比如文本字符串,final修饰的常量等。方法引用则包括类和接口的全限定名,方法名和描述符,字段名和描述符等。
注:JDK8以后,常量池保存在堆中。
优点:
- 常量池避免了频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
Class常量池
定义:Class常量池可以理解为是Class文件中的资源仓库。
**内容:**Class文件中除了包含类的版本、字段、方法、接口等描述信息外, 还有一项信息就是常量池,用于存放编译期生成的各种字面量和符号引用。
首先有如下类文件定义:
public class Test {
public static void main(String[] args) {
System.out.println("hello world");
}
}
我们通过java提供的工具来查看编译后的Test.class文件的详细信息
查看命令:
javap -v Test.class
详细信息如下:
Classfile /D:/developer/gitee/spring-demo/java-demo/data-structure/src/test/java/Test.class
Last modified 2022-5-11; size 413 bytes
MD5 checksum ae5ed4a0ee5b45fd449f77ade8d7bd24
Compiled from "Test.java"
public class Test
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool: 这里就是这个类需要的常量,运行后,会保存到常量池中,#后面的数字也会变为真时的内存地址。
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // hello world
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // Test
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 Test.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 hello world
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 Test
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
public Test();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 4: 0
line 5: 8
}
SourceFile: "Test.java"
字面量
定义:字面量就是指由字母、数字等构成的字符串或者数值常量。
**PS:**字面量只可以右值出现【等号右边的值】如:int a = 1 这里的a为左值,1为右值。在这个例子中1就是字面量。
private int compute() {
int a = 1;//符号引用:a 字面量:1
int b = 2;//符号引用:b 字面量:2
String c = "有梦想的肥宅";//符号引用:c 字面量:有梦想的肥宅
return a + b;
}
符号引用
符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
符号引用只有到运行时被加载到内存后,这些符号才有对应的内存地址信息,这些常量池一旦被装入内存就变成运行时常量池,也就引出了下面动态链接的概念。
**动态链接:**对应的符号引用在程序加载或运行时会被转变为被加载到内存区域的代码的直接引用。
**例:**compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址,主要通过对象头里的类型指针去转换直接引用。
字符串常量池
字符串的分配和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化:
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先查询字符串常量池是否存在该字符串
- 存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
三种字符串操作(Jdk1.7 及以上版本)
直接赋值
String s = "有梦想的肥宅"; // s :指向常量池中的引用**PS:**这种方式创建的字符串对象,只会在常量池中。
创建步骤:
JVM会先去常量池中通过 equals(key) 方法,判断是否有相同的对象:
- 有,则直接返回该对象在常量池中的引用
- 没有,则会在常量池中创建一个新对象,再返回引用
new String()方法创建
String s1 = new String("有梦想的肥宅"); // s1指向内存中的对象引用PS:这种方式会保证字符串常量池和堆中都有这个对象,没有就创建,最后返回堆内存中的对象引用。
创建步骤:
因为有"有梦想的肥宅"这个字面量,所以会先检查字符串常量池中是否存在此字符串:
- 不存在,先在字符串常量池里创建一个字符串对象,再去堆内存中创建一个字符串对象"有梦想的肥宅"
- 存在,就直接去堆内存中创建一个字符串对象"有梦想的肥宅", 最后,将内存中的引用返回
intern()方法
String s1 = new String("有梦想的肥宅"); String s2 = s1.intern(); //s1.intern()返回的串池中的对象,s1引用的是堆中的对象 System.out.println(s1 == s2); //false**PS:**这个方法是尝试将字符串对象放入串池,如果有则不放入,如果没有则放入串池,并把串池中的对象返回。
创建步骤:
还是会去常量池找看有没有"有梦想的肥宅"这个字符串:
- 存在,则返回串池中的对象引用
- 不存在,把字符串放入串池,并返回串池中的对象 引用
**PS:**jdk1.6版本需要将 s1 复制到字符串常量池里
八种基本类型的包装类和对象池
java中基本类型的包装类的大部分都实现了常量池技术(严格来说对象在堆上应该叫对象池),这些类是 Byte、Short、Integer、Long、Character、Boolean,另外两种浮点数类型的包装类则没有实现。
**PS:**Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,因为一般这种比较小的数用到的概率相对较大。
public class Test {
public static void main(String[] args) {
//1、5种整形的包装类Byte,Short,Integer,Long,Character的对象,在值小于127时可以使用对象池
Integer i1 = 127; //PS:这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
Integer i2 = 127;
System.out.println(i1 == i2);//输出true
//2、当值大于127时,不会从对象池中取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//输出false
//3、用new关键词新生成对象不会使用对象池
Integer i5 = new Integer(127);
Integer i6 = new Integer(127);
System.out.println(i5 == i6);//输出false
//4、Boolean类也实现了对象池技术
Boolean bool1 = true;
Boolean bool2 = true;
System.out.println(bool1 == bool2);//输出true
//5、浮点类型的包装类没有实现对象池技术
Double d1 = 1.0D;
Double d2 = 1.0D;
System.out.println(d1 == d2);//输出false
}
}
2.6 StringTable详解(就是串池)
首先来看一个代码示例:
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
public static void main(String[] args) {
String s1 = "a"; // 懒惰的
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
// new String 会在常量池和堆内存中同时创建对象,但引用的是堆内存中的引用
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5);
String ap = new String("a")+new String("b");
// 这里注意一下,通过new 相加,这里a,b都会检查常量池,但是最后生成的结果"ab"不会保存到常量池
}
}
编译过程中遇到编码问题,可以通过-encoding来指定编码,如下:
javac -encoding utf-8 Demo1_22.java
来查看一下编译后文件的详细信息:
Classfile /D:/path/to/Demo1_22.class
Last modified 2022-5-11; size 776 bytes
MD5 checksum 141d5699097730cd03bba544e9b27e1c
Compiled from "Demo1_22.java"
public class cn.itcast.jvm.t1.stringtable.Demo1_22
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #12.#25 // java/lang/Object."<init>":()V
#2 = String #26 // a
#3 = String #27 // b
#4 = String #28 // ab
#5 = Class #29 // java/lang/StringBuilder
#6 = Methodref #5.#25 // java/lang/StringBuilder."<init>":()V
#7 = Methodref #5.#30 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#8 = Methodref #5.#31 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#9 = Fieldref #32.#33 // java/lang/System.out:Ljava/io/PrintStream;
#10 = Methodref #34.#35 // java/io/PrintStream.println:(Z)V
#11 = Class #36 // cn/itcast/jvm/t1/stringtable/Demo1_22
#12 = Class #37 // java/lang/Object
#13 = Utf8 <init>
#14 = Utf8 ()V
#15 = Utf8 Code
#16 = Utf8 LineNumberTable
#17 = Utf8 main
#18 = Utf8 ([Ljava/lang/String;)V
#19 = Utf8 StackMapTable
#20 = Class #38 // "[Ljava/lang/String;"
#21 = Class #39 // java/lang/String
#22 = Class #40 // java/io/PrintStream
#23 = Utf8 SourceFile
#24 = Utf8 Demo1_22.java
#25 = NameAndType #13:#14 // "<init>":()V
#26 = Utf8 a
#27 = Utf8 b
#28 = Utf8 ab
#29 = Utf8 java/lang/StringBuilder
#30 = NameAndType #41:#42 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#31 = NameAndType #43:#44 // toString:()Ljava/lang/String;
#32 = Class #45 // java/lang/System
#33 = NameAndType #46:#47 // out:Ljava/io/PrintStream;
#34 = Class #40 // java/io/PrintStream
#35 = NameAndType #48:#49 // println:(Z)V
#36 = Utf8 cn/itcast/jvm/t1/stringtable/Demo1_22
#37 = Utf8 java/lang/Object
#38 = Utf8 [Ljava/lang/String;
#39 = Utf8 java/lang/String
#40 = Utf8 java/io/PrintStream
#41 = Utf8 append
#42 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#43 = Utf8 toString
#44 = Utf8 ()Ljava/lang/String;
#45 = Utf8 java/lang/System
#46 = Utf8 out
#47 = Utf8 Ljava/io/PrintStream;
#48 = Utf8 println
#49 = Utf8 (Z)V
{
public cn.itcast.jvm.t1.stringtable.Demo1_22();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=6, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
27: astore 4
29: ldc #4 // String ab
31: astore 5
33: getstatic #9 // Field java/lang/System.out:Ljava/io/PrintStream;
36: aload_3
37: aload 5
39: if_acmpne 46
42: iconst_1
43: goto 47
46: iconst_0
47: invokevirtual #10 // Method java/io/PrintStream.println:(Z)V
50: return
LineNumberTable:
line 11: 0
line 12: 3
line 13: 6
line 14: 9
line 15: 29
line 17: 33
line 21: 50
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 46
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream ]
frame_type = 255 /* full_frame */
offset_delta = 0
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream, int ]
}
SourceFile: "Demo1_22.java"
下面来看几道面试题:
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
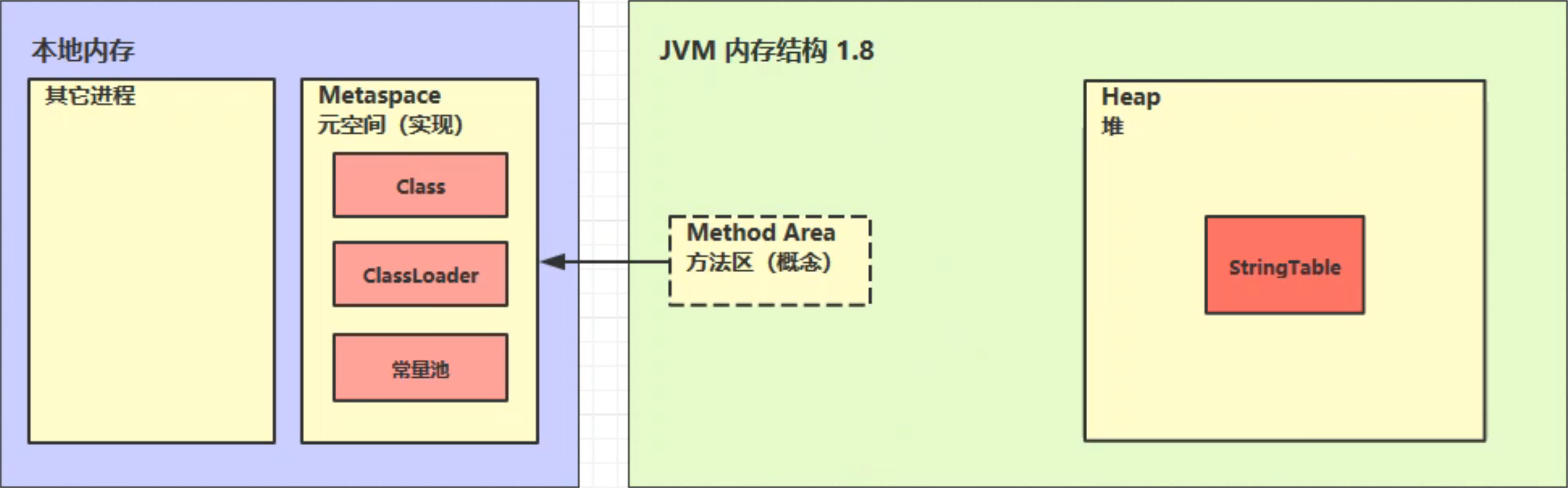
StringTable存储位置
Java 8 中的存储位置:
java 6 中的存储位置:
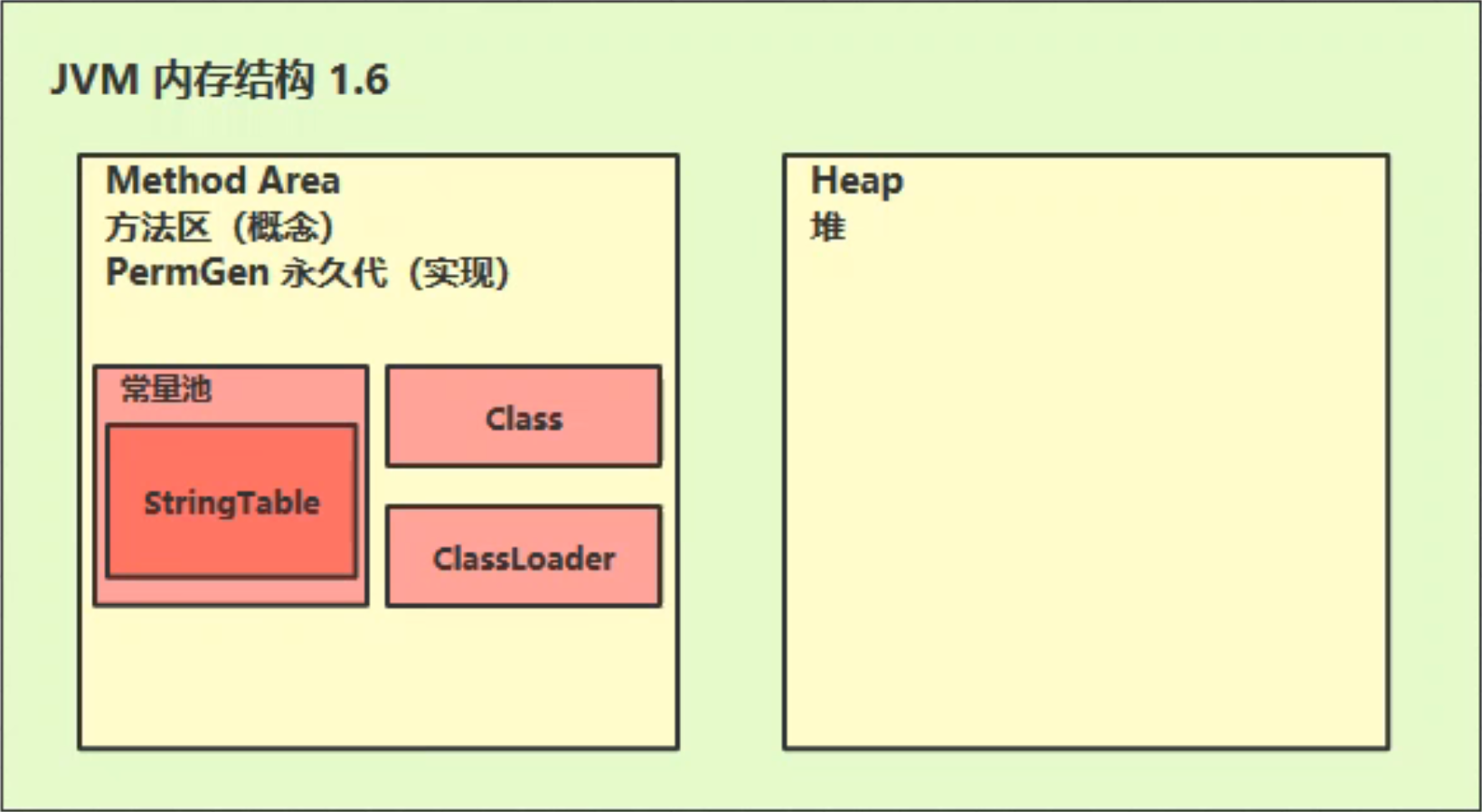
将串池转移到堆内存后,更有利于内存的回收
StringTable的特性
常量池中的字符串仅是符号,第一次用到时才变为对象
利用串池的机制,来避免重复创建字符串对象
字符串变量拼接的原理是 StringBuilder (1.8)
字符串常量拼接的原理是编译期优化
可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
StringTable调优
StringTable的实现类似于Hash表,默认的桶大小是65535(在Java11中),可以使用参数-XX:StringTableSzie=655350 来进行调整。
当项目中字符串变量较多时,可以适当增加StringTable的大小,来提高运行效率。
2.7 直接内存
优点:
常见于 NIO 操作时,用于数据缓冲区
分配回收成本较高,但读写性能高
不受 JVM 内存回收管理
首先来看一个例子:
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "E:\\path\\to\\big-file.mp4";
static final String TO = "E:\\a.mp4";
static final int _1Mb = 1024 * 1024;
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
NIO会快很多
文件读写流程:
直接内存溢出
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
禁用显示的垃圾回收
-XX:DisableExplicitGC
直接内存的申请释放
在Java中分配直接内存,大有如下三种主要方式:
- Unsafe.allocateMemory()
- ByteBuffer.allocateDirect()
- native方法
Unsafe类
在unsafe类中,提供了两个方法来进行直接内存的分配和释放
// 申请直接内存内存
public native long allocateMemory(long var1);
// 释放直接内存
public native void freeMemory(long var1);
下面给出一个使用的例子:
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = Unsafe.getUnsafe();
// 分配内存
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
ByteBuffer类
Unsafe是一个十分原始的底层方法,不适合开发者使用。而ByteBuffer则是留给开发者使用的。下面来看一下其实现:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
可以看到,他创建了一个DirectByteBuffer对象
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
// 计算需要分配内存的大小
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
// 分配直接内存
long base = 0;
try {
base = UNSAFE.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
UNSAFE.setMemory(base, size, (byte) 0);
// 计算内存地址
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 创建cleaner
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
可以看到,DirectByteBuffer也是通过UNSAFE.allocateMemory(size)来申请的直接内存空间。那么释放直接内存的在哪里呢?
可以看到这么一行代码:cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
Cleaner继承自PhantomReference,所以当垃圾回收器在回收DirectByteBuffer这个对象时,就会同步对cleaner进行回收工作;
TODO 补充一下虚引用
Deallocator的实现
private static class Deallocator implements Runnable {
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
UNSAFE.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
三、垃圾回收
3.1 如何判断对象可以被回收?
3.1.1 引用计数法
每个对象有一个引用计数器,当对象被引用一次则计数器加1,当对象引用失效一次则计数器减1,对于为0的对象意味着是垃圾对象,可以被GC回收。
3.1.2 可达性分析
从GC Roots作为起点开始搜索,那么整个连通图中的对象便都是活对象,对于GC Roots无法到达的对象便成了垃圾回收的对象,随时可被GC回收
3.1.3 对引用计数和可达性分析算法的分析
目前虚拟机基本都是采用可达性算法,为什么不采用引用计数算法呢?下面就说说引用计数法是如何统计所有对象的引用计数的,再对比分析可达性算法是如何解决引用技术算法的不足。先简单说说这两个算法:
- 引用计数算法(reference-counting) :每个对象有一个引用计数器,当对象被引用一次则计数器加1,当对象引用失效一次则计数器减1,对于计数器为0的对象意味着是垃圾对象,可以被GC回收。
- 可达性算法(GC Roots Tracing):从GC Roots作为起点开始搜索,那么整个连通图中的对象便都是活对象,对于GC Roots无法到达的对象便成了垃圾回收的对象,随时可被GC回收。
采用引用计数算法的系统只需在每个实例对象创建之初,通过计数器来记录所有的引用次数即可。而可达性算法,则需要再次GC时,遍历整个GC根节点来判断是否回收。
下面通过一段代码来对比说明:
public class GcDemo {
public static void main(String[] args) {
//分为6个步骤
GcObject obj1 = new GcObject(); //Step 1
GcObject obj2 = new GcObject(); //Step 2
obj1.instance = obj2; //Step 3
obj2.instance = obj1; //Step 4
obj1 = null; //Step 5
obj2 = null; //Step 6
}
}
class GcObject{
public Object instance = null;
}
很多文章以及Java虚拟机相关的书籍,都会告诉你如果采用引用计数算法,上述代码中obj1和obj2指向的对象已经不可能再被访问,彼此互相引用对方导致引用计数都不为0,最终无法被GC回收,而可达性算法能解决这个问题。
但这些文章和书籍并没有真正从内存角度来阐述这个过程是如何统计的,很多时候大家都在相互借鉴、翻译,却也都没有明白。或者干脆装作讲明白,或者假定读者依然明白。 其实很多人并不明白为什么引用计数法不为0,引用计数到底是如何维护所有对象引用的,可达性是如何可达的? 接下来结合实例,从Java内存模型以及数学的图论知识角度来说明,希望能让大家彻底明白该过程。
情况(一):引用计数算法
如果采用的是引用计数算法:
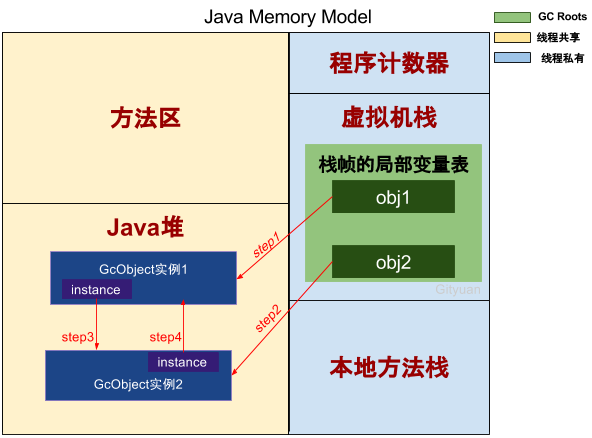
再回到前面代码GcDemo的main方法共分为6个步骤:
- Step1:GcObject实例1的引用计数加1,实例1的引用计数=1;
- Step2:GcObject实例2的引用计数加1,实例2的引用计数=1;
- Step3:GcObject实例2的引用计数再加1,实例2的引用计数=2;
- Step4:GcObject实例1的引用计数再加1,实例1的引用计数=2;
执行到Step 4,则GcObject实例1和实例2的引用计数都等于2。
接下来继续结果图:
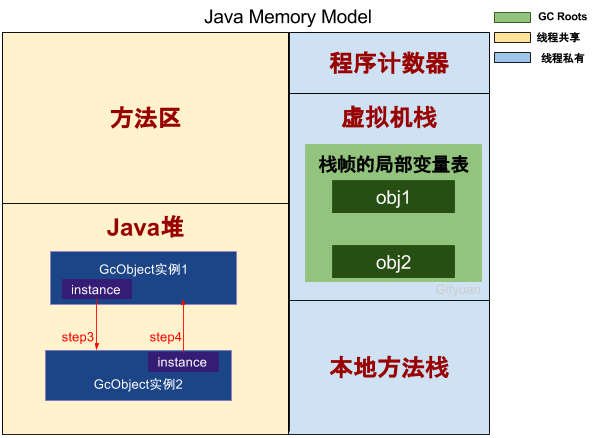
- Step5:栈帧中obj1不再指向Java堆,GcObject实例1的引用计数减1,结果为1;
- Step6:栈帧中obj2不再指向Java堆,GcObject实例2的引用计数减1,结果为1。
到此,发现GcObject实例1和实例2的计数引用都不为0,那么如果采用的引用计数算法的话,那么这两个实例所占的内存将得不到释放,这便产生了内存泄露。
情况(二):可达性算法
这是目前主流的虚拟机都是采用GC Roots Tracing算法,比如Sun的Hotspot虚拟机便是采用该算法。 该算法的核心算法是从GC Roots对象作为起始点,利用数学中图论知识,图中可达对象便是存活对象,而不可达对象则是需要回收的垃圾内存。这里涉及两个概念,一是GC Roots,一是可达性。
那么可以作为GC Roots的对象(见下图):
- 虚拟机栈的栈帧的局部变量表所引用的对象;
- 本地方法栈的JNI所引用的对象;
- 方法区的静态变量和常量所引用的对象;
关于可达性的对象,便是能与GC Roots构成连通图的对象,如下图:
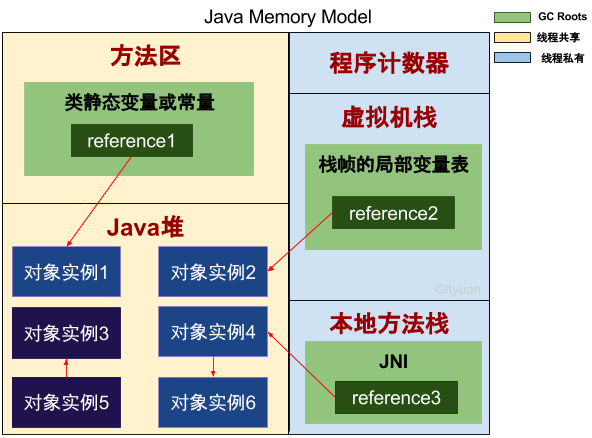
从上图,reference1、reference2、reference3都是GC Roots,可以看出:
- reference1-> 对象实例1;
- reference2-> 对象实例2;
- reference3-> 对象实例4;
- reference3-> 对象实例4 -> 对象实例6;
可以得出对象实例1、2、4、6都具有GC Roots可达性,也就是存活对象,不能被GC回收的对象。
而对于对象实例3、5直接虽然连通,但并没有任何一个GC Roots与之相连,这便是GC Roots不可达的对象,这就是GC需要回收的垃圾对象。
到这里,相信大家应该能彻底明白引用计数算法和可达性算法的区别吧**。**
再回过头来看看最前面的实例,GcObject实例1和实例2虽然从引用计数虽然都不为0,但从可达性算法来看,都是GC Roots不可达的对象。
总之,对于对象之间循环引用的情况,引用计数算法,则GC无法回收这两个对象,而可达性算法则可以正确回收。
3.1.4 引用类型
在JVM中,引用类型主要分为强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)这 4 种引用强度依次逐渐减弱。除强引用外,其他 3 种引用均可以在 java.lang.ref 包中找到它们的身影。如下图,显示了这 3 种引用类型对应的类,开发人员可以在应用程序中直接使用它们。
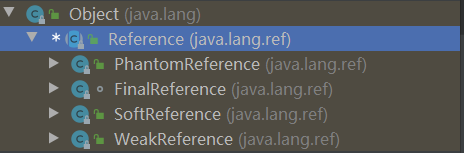
Reference 子类中只有终结器引用是包内可见的,其他 3 种引用类型均为 public,可以在应用程序中直接使用
强引用(StrongReference):最传统的“引用”的定义,是指在程序代码之中普遍存在的引用赋值,即类似“Object obj = new Object()”这种引用关系。无论任何情况下,只要强引用关系还存在,垃圾收集器就永远不会回收掉被引用的对象。
软引用(SoftReference):在系统将要发生内存溢出之前,将会把这些对象列入回收范围之中进行第二次回收。如果这次回收后还没有足够的内存,才会抛出内存流出异常。
弱引用(WeakReference):被弱引用关联的对象只能生存到下一次垃圾收集之前。当垃圾收集器工作时,无论内存空间是否足够,都会回收掉被弱引用关联的对象。
虚引用(PhantomReference):一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来获得一个对象的实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
强引用(Strong Reference)
强引用(Strong Reference) — 不回收
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。 ps:强引用其实也就是我们平时A a = new A()这个意思
强引用具备以下特点:
- 强引用可以直接访问目标对象。
- 强引用所指向的对象在任何时候都不会被系统回收,虚拟机宁愿抛出 OOM 异常,也不会回收强引用所指向对象。
- 强引用可能导致内存泄漏。
软引用(Soft Reference)
软引用(Soft Reference)——内存不足即回收
软引用是用来描述一些还有用,但非必需的对象。只被软引用关联着的对象,在系统将要发生内存溢出异常前,会把这些对象列进回收范围之中进行第二次回收,如果这次回收还没有足够的内存,才会抛出内存溢出异常。
软引用通常用来实现内存敏感的缓存。比如:高速缓存就有用到软引用。如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
垃圾回收器在某个时刻决定回收软可达的对象的时候,会清理软引用,并可选地把引用存放到一个引用队列(Reference Queue)。
类似弱引用,只不过 Java 虚拟机会尽量让软引用的存活时间长一些,迫不得已才清理。
注意:Java 垃圾回收器准备对SoftReference所指向的对象进行回收时,调用对象的 finalize() 方法之前,SoftReference对象自身会被加入到这个 ReferenceQueue 对象中,此时可以通过 ReferenceQueue 的 poll() 方法取到它们。
软引用的使用示例:
/**
* 软引用:对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收( 因为是在第一次回收后才会发现内存依旧不充足,才有了这第二次回收 )。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
* 对于软引用关联着的对象,如果内存充足,则垃圾回收器不会回收该对象,如果内存不够了,就会回收这些对象的内存。
* 通过debug发现,软引用在pending状态时,referent就已经是null了。
*
* 启动参数:-Xmx5m
*
*/
public class SoftReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
Thread.sleep(3000);
MyObject object = new MyObject();
SoftReference<MyObject> softRef = new SoftReference(object, queue);
new Thread(new CheckRefQueue()).start();
object = null;
System.gc();
System.out.println("After GC : Soft Get = " + softRef.get());
System.out.println("分配大块内存");
/**
* ====================== 控制台打印 ======================
* After GC : Soft Get = I am MyObject.
* 分配大块内存
* MyObject's finalize called
* Object for softReference is null
* After new byte[] : Soft Get = null
* ====================== 控制台打印 ======================
*
* 总共触发了 3 次 full gc。第一次由System.gc();触发;第二次在在分配new byte[5*1024*740]时触发,然后发现内存不够,于是
* 将softRef列入回收返回,接着进行了第三次full gc。
*/
// byte[] b = new byte[5*1024*740];
/**
* ====================== 控制台打印 ======================
* After GC : Soft Get = I am MyObject.
* 分配大块内存
* Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
* at com.bayern.multi_thread.part5.SoftReferenceDemo.main(SoftReferenceDemo.java:21)
* MyObject's finalize called
* Object for softReference is null
* ====================== 控制台打印 ======================
*
* 也是触发了 3 次 full gc。第一次有System.gc();触发;第二次在在分配new byte[5*1024*740]时触发,然后发现内存不够,
* 于是将softRef列入回收返回,接着进行了第三次full gc。当第三次 full gc 后发现内存依旧不够用于分配
* new byte[5*1024*740],则就抛出了OutOfMemoryError异常。
*/
byte[] b = new byte[5*1024*790];
System.out.println("After new byte[] : Soft Get = " + softRef.get());
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>) queue.remove();
} catch (InterruptedException e) {
e.printStackTrace();
}
if (obj != null) {
System.out.println("Object for softReference is " + obj.get());
}
}
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject.";
}
}
}
弱引用(Weak Reference)
弱引用(Weak Reference)——发现即回收
弱引用也是用来描述那些非必需对象,只被弱引用关联的对象只能生存到下一次垃圾收集发生为止。在系统 GC 时,只要发现弱引用,不管系统堆空间使用是否充足,都会回收掉只被弱引用关联的对象。
但是,由于垃圾回收器的线程通常优先级很低,因此,并不一定能很快地发现持有弱引用的对象。在这种情况下,弱引用对象可以存在较长的时间。
弱引用和软引用一样,在构造弱引用时,也可以指定一个引用队列,当弱引用对象被回收时,就会加入指定的引用队列,通过这个队列可以跟踪对象的回收情况。
软引用、弱引用都非常适合来保存那些可有可无的缓存数据。如果这么做,当系统内存不足时,这些缓存数据会被回收,不会导致内存溢出。而当内存资源充足时,这些缓存数据又可以存在相当长的时间,从而起到加速系统的作用。
**注意:**Java 垃圾回收器准备对WeakReference所指向的对象进行回收时,调用对象的 finalize() 方法之前,WeakReference对象自身会被加入到这个 ReferenceQueue 对象中,此时可以通过 ReferenceQueue 的 poll() 方法取到它们。
/**
* 用来描述非必须的对象,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发送之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。一旦一个弱引用对象被垃圾回收器回收,便会加入到一个注册引用队列中。
*/
public class WeakReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) {
MyObject object = new MyObject();
Reference<MyObject> weakRef = new WeakReference<>(object, queue);
System.out.println("创建的弱引用为 : " + weakRef);
new Thread(new CheckRefQueue()).start();
object = null;
System.out.println("Before GC: Weak Get = " + weakRef.get());
System.gc();
System.out.println("After GC: Weak Get = " + weakRef.get());
/**
* ====================== 控制台打印 ======================
* 创建的弱引用为 : java.lang.ref.WeakReference@1d44bcfa
* Before GC: Weak Get = I am MyObject
* After GC: Weak Get = null
* MyObject's finalize called
* 删除的弱引用为 : java.lang.ref.WeakReference@1d44bcfa , 获取到的弱引用的对象为 : null
* ====================== 控制台打印 ======================
*/
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>)queue.remove();
} catch (InterruptedException e) {
e.printStackTrace();
}
if(obj != null) {
System.out.println("删除的弱引用为 : " + obj + " , 获取到的弱引用的对象为 : " + obj.get());
}
}
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject";
}
}
}
虚引用(Phantom Reference)
虚引用(Phantom Reference)——对象回收跟踪
也称为“幽灵引用”或者“幻影引用”,是所有引用类型中最弱的一个。
一个对象是否有虚引用的存在,完全不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它和没有引用几乎是一样的,随时都可能被垃圾回收器回收。它不能单独使用,也无法通过虚引用来获取被引用的对象。当试图通过虚引用的 get()方法取得对象时,总是 null
为一个对象设置虚引用关联的唯一目的在于跟踪垃圾回收过程。比如:能在这个对象被收集器回收时收到一个系统通知。
虚引用必须和引用队列一起使用。虚引用在创建时必须提供一个引用队列作为参数。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象后,将这个虚引用加入引用队列,以通知应用程序对象的回收情况。
由于虚引用可以跟踪对象的回收时间,因此,也可以将一些资源释放操作放置在虚引用中执行和记录。
**注意:PhantomReference 只有当 Java 垃圾回收器对其所指向的对象真正进行回收时,会将其加入到这个 ReferenceQueue 对象中,这样就可以追综对象的销毁情况。这里referent对象的finalize()方法已经调用过了。**所以具体用法和之前两个有所不同,它必须传入一个 ReferenceQueue 对象。当虚引用所引用对象准备被垃圾回收时,虚引用会被添加到这个队列中。
/**
* 虚引用也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个持有虚引用的对象,和没有引用几乎是一样的,随时都有可能被垃圾回收器回收。
* 虚引用必须和引用队列一起使用,它的作用在于跟踪垃圾回收过程。
* 当phantomReference被放入队列时,说明referent的finalize()方法已经调用,并且垃圾收集器准备回收它的内存了。
*/
public class PhantomReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
MyObject object = new MyObject();
Reference<MyObject> phanRef = new PhantomReference<>(object, queue);
System.out.println("创建的虚拟引用为 : " + phanRef);
new Thread(new CheckRefQueue()).start();
object = null;
int i = 1;
while (true) {
System.out.println("第" + i++ + "次GC");
System.gc();
TimeUnit.SECONDS.sleep(1);
}
/**
* ====================== 控制台打印 ======================
* 创建的虚拟引用为 : java.lang.ref.PhantomReference@1d44bcfa
* 第1次GC
* MyObject's finalize called
* 第2次GC
* 删除的虚引用为: java.lang.ref.PhantomReference@1d44bcfa , 获取虚引用的对象 : null
* ====================== 控制台打印 ======================
*
* 再经过一次GC之后,系统找到了垃圾对象,并调用finalize()方法回收内存,但没有立即加入PhantomReference Queue中。因为MyObject对象重写了finalize()方法,并且该方法是一个非空实现,所以这里MyObject也是一个Final Reference。所以第一次GC完成的是Final Reference的事情。
* 第二次GC时,该对象(即,MyObject)对象会真正被垃圾回收器进行回收,此时,将PhantomReference加入虚引用队列( PhantomReference Queue )。
* 而且每次gc之间需要停顿一些时间,已给JVM足够的处理时间;如果这里没有TimeUnit.SECONDS.sleep(1); 可能需要gc到第5、6次才会成功。
*/
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject";
}
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>)queue.remove();
System.out.println("删除的虚引用为: " + obj + " , 获取虚引用的对象 : " + obj.get());
System.exit(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
终结器引用(Final Reference)
它用于实现对象的 finalize() 方法,也可以称为终结器引用。无需手动编码,其内部配合引用队列使用。
在 GC 时,终结器引用入队。由 Finalizer 线程通过终结器引用找到被引用对象调用它的 finalize()方法,第二次 GC 时才回收被引用的对象
当前类是否是finalizer类,注意这里finalizer是由JVM来标志的( 后面简称f类 ),并不是指java.lang.ref.Finalizer类。但是f类是会被JVM注册到java.lang.ref.Finalizer类中的。
GC 回收问题
- 对象因为Finalizer的引用而变成了一个临时的强引用,即使没有其他的强引用,还是无法立即被回收;
- 对象至少经历两次GC才能被回收,因为只有在FinalizerThread执行完了f对象的finalize方法的情况下才有可能被下次GC回收,而有可能期间已经经历过多次GC了,但是一直还没执行对象的finalize方法;
- CPU资源比较稀缺的情况下FinalizerThread线程有可能因为优先级比较低而延迟执行对象的finalize方法;
- 因为对象的finalize方法迟迟没有执行,有可能会导致大部分f对象进入到old分代,此时容易引发old分代的GC,甚至Full GC,GC暂停时间明显变长,甚至导致OOM;
- 对象的finalize方法被调用后,这个对象其实还并没有被回收,虽然可能在不久的将来会被回收。
使用示例
软引用的例子:
public class SoftReferenceDemo {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
List<SoftReference<byte[]>> list = new ArrayList<>();
// 引用队列
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
for (int i = 0; i < 5; i++) {
// 关联了引用队列, 当软引用所关联的 byte[]被回收时,软引用自己会加入到 queue 中去
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);
System.out.println(ref.get());
list.add(ref);
System.out.println(list.size());
}
// 从队列中获取无用的 软引用对象,并移除
Reference<? extends byte[]> poll = queue.poll();
while( poll != null) {
list.remove(poll);
poll = queue.poll();
}
System.out.println("===========================");
for (SoftReference<byte[]> reference : list) {
System.out.println(reference.get());
}
}
}
弱引用的例子:
/**
* 演示弱引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class WeakReferenceDemo {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// list --> WeakReference --> byte[]
List<WeakReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);
list.add(ref);
for (WeakReference<byte[]> w : list) {
System.out.print(w.get()+" ");
}
System.out.println();
}
System.out.println("循环结束:" + list.size());
}
}
关于System.gc()
了解下System.gc()操作,如果连续调用,若前一次没完成,后一次可能会失效,所以连接调用System.gc()作用不大?
关于上面例子的问题我们要补充两点
首先我们先来看下System.gc()的doc文档:
/** * Runs the garbage collector. * <p> * Calling the <code>gc</code> method suggests that the Java Virtual * Machine expend effort toward recycling unused objects in order to * make the memory they currently occupy available for quick reuse. * When control returns from the method call, the Java Virtual * Machine has made a best effort to reclaim space from all discarded * objects. * <p> * The call <code>System.gc()</code> is effectively equivalent to the * call: * <blockquote><pre> * Runtime.getRuntime().gc() * </pre></blockquote> * * @see java.lang.Runtime#gc() */ public static void gc() { Runtime.getRuntime().gc(); }当这个方法返回的时候,Java虚拟机已经尽最大努力去回收所有丢弃对象的空间了。因此不存在这System.gc()操作连续调用时,若前一次没完成,后一次可能会失效的情况。以及“所以连接调用System.gc()其实作用不大”这个说法不对,应该说连续调用System.gc()对性能可定是有影响的,但作用之一就是可以清除“漂浮垃圾”。
同时需要特别注意的是对于已经没有地方引用的这些f对象,并不会在最近的那一次gc里马上回收掉,而是会延迟到下一个或者下几个gc时才被回收,因为执行finalize方法的动作无法在gc过程中执行,万一finalize方法执行很长呢,所以只能在这个gc周期里将这个垃圾对象重新标活,直到执行完finalize方法将Final Reference从queue里删除,这样下次gc的时候就真的是漂浮垃圾了会被回收。
public class PhantomReferenceDemo2 { public static void main(String[] args) { ReferenceQueue<MyObject> queue = new ReferenceQueue<>(); MyObject object = new MyObject(); Reference<MyObject> phanRef = new PhantomReference<>(object, queue); System.out.println("创建的虚拟引用为 : " + phanRef); object = null; System.out.println(phanRef.get()); System.gc(); System.out.println("referent : " + phanRef); System.out.println(queue.poll() == phanRef); //true /** * ====================== 控制台打印 ====================== * 创建的虚拟引用为 : java.lang.ref.PhantomReference@1d44bcfa * null * referent : java.lang.ref.PhantomReference@1d44bcfa * true * ====================== 控制台打印 ====================== * * 这里因为MyObject没有重写finalize()方法,所以这里的在System.gc()后就会处理PhantomReference加入到PhantomReference Queue中。 */ } public static class MyObject { @Override public String toString() { return "I am MyObject"; } } }
关于ReferenceQueue
引用队列,在检测到适当的可到达性更改后,垃圾回收器将已注册的引用对象添加到该队列中
实现了一个队列的入队(enqueue)和出队(poll还有remove)操作,内部元素就是泛型的Reference,并且Queue的实现,是由Reference自身的链表结构( 单向循环链表 )所实现的。
ReferenceQueue名义上是一个队列,但实际内部并非有实际的存储结构,它的存储是依赖于内部节点之间的关系来表达。可以理解为queue是一个类似于链表的结构,这里的节点其实就是reference本身。可以理解为queue为一个链表的容器,其自己仅存储当前的head节点,而后面的节点由每个reference节点自己通过next来保持即可。
- 属性 head:始终保存当前队列中最新要被处理的节点,可以认为queue为一个后进先出的队列。当新的节点进入时,采取以下的逻辑:
r.next = (head == null) ? r : head;
head = r;
然后,在获取的时候,采取相应的逻辑:
Reference<? extends T> r = head;
if (r != null) {
head = (r.next == r) ? null : r.next; // Unchecked due to the next field having a raw type in Reference
r.queue = NULL;
r.next = r;
}
- 方法enqueue():待处理引用入队
boolean enqueue(Reference<? extends T> r) { /* Called only by Reference class */
synchronized (lock) {
// Check that since getting the lock this reference hasn't already been
// enqueued (and even then removed)
ReferenceQueue<?> queue = r.queue;
if ((queue == NULL) || (queue == ENQUEUED)) {
return false;
}
assert queue == this;
r.queue = ENQUEUED;
r.next = (head == null) ? r : head;
head = r;
queueLength++;
if (r instanceof FinalReference) {
sun.misc.VM.addFinalRefCount(1);
}
lock.notifyAll(); // ①
return true;
}
}
① lock.notifyAll(); 👈通知外部程序之前阻塞在当前队列之上的情况。( 即之前一直没有拿到待处理的对象,如ReferenceQueue的remove()方法 )
关于Reference
java.lang.ref.Reference 为 软(soft)引用、弱(weak)引用、虚(phantom)引用的父类。
因为Reference对象和垃圾回收密切配合实现,该类可能不能被直接子类化。可以理解为Reference的直接子类都是由jvm定制化处理的,因此在代码中直接继承于Reference类型没有任何作用。但可以继承jvm定制的Reference的子类。例如:Cleaner 继承了 PhantomReference
public class Cleaner extends PhantomReference<Object>
构造函数
其内部提供2个构造函数,一个带queue,一个不带queue。其中queue的意义在于,我们可以在外部对这个queue进行监控。即如果有对象即将被回收,那么相应的reference对象就会被放到这个queue里。我们拿到reference,就可以再作一些事务。
而如果不带的话,就只有不断地轮询reference对象,通过判断里面的get是否返回null( phantomReference对象不能这样作,其get始终返回null,因此它只有带queue的构造函数 )。这两种方法均有相应的使用场景,取决于实际的应用。如weakHashMap中就选择去查询queue的数据,来判定是否有对象将被回收。而ThreadLocalMap,则采用判断get()是否为null来作处理。
/* -- Constructors -- */
Reference(T referent) {
this(referent, null);
}
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
如果我们在创建一个引用对象时,指定了ReferenceQueue,那么当引用对象指向的对象达到合适的状态(根据引用类型不同而不同)时,GC 会把引用对象本身添加到这个队列中,方便我们处理它,因为**“引用对象指向的对象 GC 会自动清理,但是引用对象本身也是对象(是对象就占用一定资源),所以需要我们自己清理。”**
Reference链表结构内部主要的成员有
① pending 和 discovered
/* List of References waiting to be enqueued. The collector adds
* References to this list, while the Reference-handler thread removes
* them. This list is protected by the above lock object. The
* list uses the discovered field to link its elements.
*/
private static Reference<Object> pending = null;
/* When active: next element in a discovered reference list maintained by GC (or this if last)
* pending: next element in the pending list (or null if last)
* otherwise: NULL
*/
transient private Reference<T> discovered; /* used by VM */
可以理解为jvm在gc时会将要处理的对象放到这个静态字段上面。同时,另一个字段discovered:表示要处理的对象的下一个对象。即可以理解要处理的对象也是一个链表,通过discovered进行排队,这边只需要不停地拿到pending,然后再通过discovered不断地拿到下一个对象赋值给pending即可,直到取到了最有一个。因为这个pending对象,两个线程都可能访问,因此需要加锁处理。
if (pending != null) {
r = pending;
// 'instanceof' might throw OutOfMemoryError sometimes
// so do this before un-linking 'r' from the 'pending' chain...
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;
}

② referent
private T referent; /* Treated specially by GC */
👆referent字段由GC特别处理
referent:表示其引用的对象,即我们在构造的时候需要被包装在其中的对象。对象即将被回收的定义:此对象除了被reference引用之外没有其它引用了( 并非确实没有被引用,而是gcRoot可达性不可达,以避免循环引用的问题 )。如果一旦被回收,则会直接置为null,而外部程序可通过引用对象本身( 而不是referent,这里是reference#get() )了解到回收行为的产生( PhntomReference除外 )。
③ next
/* When active: NULL
* pending: this
* Enqueued: next reference in queue (or this if last)
* Inactive: this
*/
@SuppressWarnings("rawtypes")
Reference next;
next:即描述当前引用节点所存储的下一个即将被处理的节点。但next仅在放到queue中才会有意义( 因为,只有在enqueue的时候,会将next设置为下一个要处理的Reference对象 )。为了描述相应的状态值,在放到队列当中后,其queue就不会再引用这个队列了。而是引用一个特殊的ENQUEUED。因为已经放到队列当中,并且不会再次放到队列当中。
④ discovered
/* When active: next element in a discovered reference list maintained by GC (or this if last)
* pending: next element in the pending list (or null if last)
* otherwise: NULL
*/
transient private Reference<T> discovered; /* used by VM */
👆被VM使用
discovered:当处于active状态时:discoverd reference的下一个元素是由GC操纵的( 如果是最后一个了则为this );当处于pending状态:discovered为pending集合中的下一个元素( 如果是最后一个了则为null );其他状态:discovered为null
⑤ lock
static private class Lock { }
private static Lock lock = new Lock();
lock:在垃圾收集中用于同步的对象。收集器必须获取该锁在每次收集周期开始时。因此这是至关重要的:任何持有该锁的代码应该尽快完成,不分配新对象,并且避免调用用户代码。
⑥ pending
/* List of References waiting to be enqueued. The collector adds
* References to this list, while the Reference-handler thread removes
* them. This list is protected by the above lock object. The
* list uses the discovered field to link its elements.
*/
private static Reference<Object> pending = null;
pending:等待被入队的引用列表。收集器会添加引用到这个列表,直到Reference-handler线程移除了它们。这个列表被上面的lock对象保护。这个列表使用discovered字段来连接它自己的元素( 即pending的下一个元素就是discovered对象 )。
⑦ queue
volatile ReferenceQueue<? super T> queue;
queue:是对象即将被回收时所要通知的队列。当对象即被回收时,整个reference对象( 而不是被回收的对象 )会被放到queue里面,然后外部程序即可通过监控这个queue拿到相应的数据了。
这里的queue( 即,ReferenceQueue对象 )名义上是一个队列,但实际内部并非有实际的存储结构,它的存储是依赖于内部节点之间的关系来表达。可以理解为queue是一个类似于链表的结构,这里的节点其实就是reference本身。可以理解为queue为一个链表的容器,其自己仅存储当前的head节点,而后面的节点由每个reference节点自己通过next来保持即可。
Reference 实例( 即Reference中的真是引用对象referent )的4种可能的内部状态值
Queue的另一个作用是可以区分不同状态的Reference。Reference有4种状态,不同状态的reference其queue也不同:
- Active:新创建的引用对象都是这个状态,在 GC 检测到引用对象已经到达合适的reachability时,GC 会根据引用对象是否在创建时制定ReferenceQueue参数进行状态转移,如果指定了,那么转移到Pending,如果没指定,转移到Inactive。
- Pending:pending-Reference列表中的引用都是这个状态,它们等着被内部线程ReferenceHandler处理入队(会调用ReferenceQueue.enqueue方法)。没有注册的实例不会进入这个状态。
- Enqueued:相应的对象已经为待回收,并且相应的引用对象已经放到queue当中了。准备由外部线程来询问queue获取相应的数据。调用ReferenceQueue.enqueued方法后的Reference处于这个状态中。当Reference实例从它的ReferenceQueue移除后,它将成为Inactive。没有注册的实例不会进入这个状态。
- Inactive:即此对象已经由外部从queue中获取到,并且已经处理掉了。即意味着此引用对象可以被回收,并且对内部封装的对象也可以被回收掉了( 实际的回收运行取决于clear动作是否被调用 )。可以理解为进入到此状态的肯定是应该被回收掉的。一旦一个Reference实例变为了Inactive,它的状态将不会再改变。
jvm并不需要定义状态值来判断相应引用的状态处于哪个状态,只需要通过计算next和queue即可进行判断。
- Active:queue为创建一个Reference对象时传入的ReferenceQueue对象;如果ReferenceQueue对象为空或者没有传入ReferenceQueue对象,则为ReferenceQueue.NULL;next==null;
- Pending:queue为初始化时传入ReferenceQueue对象;next==this(由jvm设置);
- Enqueue:当queue!=null && queue != ENQUEUED 时;设置queue为ENQUEUED;next为下一个要处理的reference对象,或者若为最后一个了next==this;
- Inactive:queue = ReferenceQueue.NULL; next = this.
通过这个组合,收集器只需要检测next属性来决定是否一个Reference实例需要特殊的处理:如果next==null,则实例是active;如果next!=null,为了确保并发收集器能够发现active的Reference对象,而不会影响可能将enqueue()方法应用于这些对象的应用程序线程,收集器应通过discovered字段链接发现的对象。discovered字段也用于链接pending列表中的引用对象。


👆外部从queue中获取Reference
- WeakReference对象进入到queue之后,相应的referent为null。
- SoftReference对象,如果对象在内存足够时,不会进入到queue,自然相应的referent不会为null。如果需要被处理( 内存不够或其它策略 ),则置相应的referent为null,然后进入到queue。通过debug发现,SoftReference是pending状态时,referent就已经是null了,说明此事referent已经被GC回收了。
- FinalReference对象,因为需要调用其finalize对象,因此其reference即使入queue,其referent也不会为null,即不会clear掉。
- PhantomReference对象,因为本身get实现为返回null。因此clear的作用不是很大。因为不管enqueue还是没有,都不会清除掉。
Q:👆如果PhantomReference对象不管enqueue还是没有,都不会清除掉reference对象,那么怎么办?这个reference对象不就一直存在这了??而且JVM是会直接通过字段操作清除相应引用的,那么是不是JVM已经释放了系统底层资源,但java代码中该引用还未置null??
A:不会的,虽然PhantomReference有时候不会调用clear,如Cleaner对象 。但Cleaner的clean()方法只调用了remove(this),这样当clean()执行完后,Cleaner就是一个无引用指向的对象了,也就是可被GC回收的对象。
active ——> pending :Reference#tryHandlePending
pending ——> enqueue :ReferenceQueue#enqueue
enqueue ——> inactive :Reference#clear

重要方法
① clear()
/**
* Clears this reference object. Invoking this method will not cause this
* object to be enqueued.
*
* <p> This method is invoked only by Java code; when the garbage collector
* clears references it does so directly, without invoking this method.
*/
public void clear() {
this.referent = null;
}
调用此方法不会导致此对象入队。此方法仅由Java代码调用;当垃圾收集器清除引用时,它直接执行,而不调用此方法。 clear的语义就是将referent置null。 清除引用对象所引用的原对象,这样通过get()方法就不能再访问到原对象了( PhantomReference除外 )。从相应的设计思路来说,既然都进入到queue对象里面,就表示相应的对象需要被回收了,因为没有再访问原对象的必要。此方法不会由JVM调用,而JVM是直接通过字段操作清除相应的引用,其具体实现与当前方法相一致。
② ReferenceHandler线程
static {
ThreadGroup tg = Thread.currentThread().getThreadGroup();
for (ThreadGroup tgn = tg;
tgn != null;
tg = tgn, tgn = tg.getParent());
Thread handler = new ReferenceHandler(tg, "Reference Handler");
/* If there were a special system-only priority greater than
* MAX_PRIORITY, it would be used here
*/
handler.setPriority(Thread.MAX_PRIORITY);
handler.setDaemon(true);
handler.start();
// provide access in SharedSecrets
SharedSecrets.setJavaLangRefAccess(new JavaLangRefAccess() {
@Override
public boolean tryHandlePendingReference() {
return tryHandlePending(false);
}
});
}
其优先级最高,可以理解为需要不断地处理引用对象。
private static class ReferenceHandler extends Thread {
private static void ensureClassInitialized(Class<?> clazz) {
try {
Class.forName(clazz.getName(), true, clazz.getClassLoader());
} catch (ClassNotFoundException e) {
throw (Error) new NoClassDefFoundError(e.getMessage()).initCause(e);
}
}
static {
// pre-load and initialize InterruptedException and Cleaner classes
// so that we don't get into trouble later in the run loop if there's
// memory shortage while loading/initializing them lazily.
ensureClassInitialized(InterruptedException.class);
ensureClassInitialized(Cleaner.class);
}
ReferenceHandler(ThreadGroup g, String name) {
super(g, name);
}
public void run() {
while (true) {
tryHandlePending(true);
}
}
}
③ tryHandlePending()
/**
* Try handle pending {@link Reference} if there is one.<p>
* Return {@code true} as a hint that there might be another
* {@link Reference} pending or {@code false} when there are no more pending
* {@link Reference}s at the moment and the program can do some other
* useful work instead of looping.
*
* @param waitForNotify if {@code true} and there was no pending
* {@link Reference}, wait until notified from VM
* or interrupted; if {@code false}, return immediately
* when there is no pending {@link Reference}.
* @return {@code true} if there was a {@link Reference} pending and it
* was processed, or we waited for notification and either got it
* or thread was interrupted before being notified;
* {@code false} otherwise.
*/
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
// 'instanceof' might throw OutOfMemoryError sometimes
// so do this before un-linking 'r' from the 'pending' chain...
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;
} else {
// The waiting on the lock may cause an OutOfMemoryError
// because it may try to allocate exception objects.
if (waitForNotify) {
lock.wait();
}
// retry if waited
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
// Give other threads CPU time so they hopefully drop some live references
// and GC reclaims some space.
// Also prevent CPU intensive spinning in case 'r instanceof Cleaner' above
// persistently throws OOME for some time...
Thread.yield();
// retry
return true;
} catch (InterruptedException x) {
// retry
return true;
}
// Fast path for cleaners
if (c != null) {
c.clean();
return true;
}
ReferenceQueue<? super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}
这个线程在Reference类的static构造块中启动,并且被设置为高优先级和daemon状态。此线程要做的事情,是不断的检查pending 是否为null,如果pending不为null,则将pending进行enqueue,否则线程进入wait状态。
由此可见,pending是由jvm来赋值的,当Reference内部的referent对象的可达状态改变时,jvm会将Reference对象放入pending链表。并且这里enqueue的队列是我们在初始化( 构造函数 )Reference对象时传进来的queue,如果传入了null( 实际使用的是ReferenceQueue.NULL ),则ReferenceHandler则不进行enqueue操作,所以只有非RefernceQueue.NULL的queue才会将Reference进行enqueue。
ReferenceQueue是作为 JVM GC与上层Reference对象管理之间的一个消息传递方式,它使得我们可以对所监听的对象引用可达发生变化时做一些处理
3.2 垃圾回收算法
3.2.1 标记-清除算法
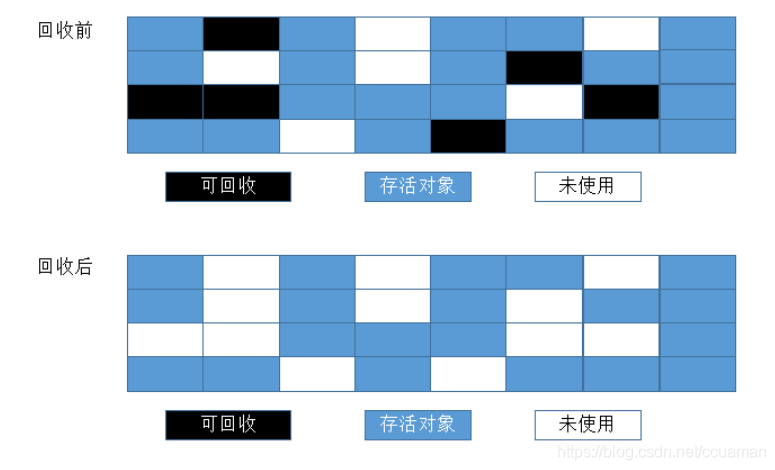
标记/清除算法,就是当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(也被成为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除
标记:标记的过程其实就是,遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。
清除:清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
优点:
- 算法实现简单(好像也不算什么优点)
缺点:
效率比较低(递归与全堆对象遍历),而且在进行GC的时候,需要停止应用程序,
这种方式清理出来的空闲内存是不连续的,内存的布局自然会乱七八糟。而为了应付这一点,JVM就不得不维持一个内存的空闲列表,这又是一种开销。而且在分配数组对象的时候,寻找连续的内存空间会不太好找。
3.2.2 标记-复制算法
复制算法是针对标记—清除算法的缺点,在其基础上进行改进而得到的,它将可用内存按容量分为大小相等的两块,每次只使用其中的一块,当这一块的内存用完了,就将还存活着的对象复制到另外一块内存上面,然后再把已使用过的内存空间一次清理掉。
如果对象的存活率过高,在复制对象时花费的时间就会很长,所以,想要使用复制算法,对象的存活率要非常低才行,而且要客服50%的内存浪费。
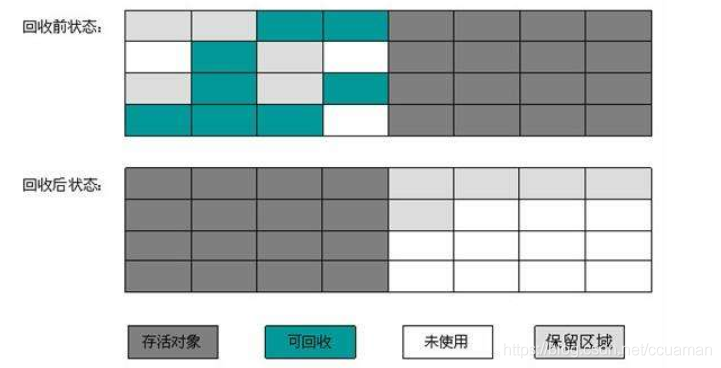
优点:
每次只对一块内存进行回收,运行高效
只需移动栈顶指针,按顺序分配内存即可,实现简单
内存回收时不用考虑内存碎片的出现
缺点:
- 可一次性分配的最大内存缩小了一半
3.2.3 标记-整理算法
为了解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。
与标记/清除算法非常相似,它也是分为两个阶段:标记和整理。
**标记:**它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
**整理:**移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
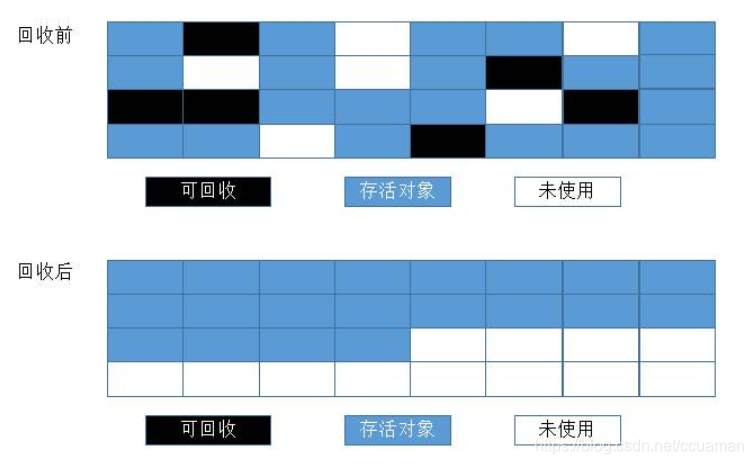
可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
不难看出,标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价,可谓是一举两得,一箭双雕,一石两鸟,一。。。。一女两男?
不过任何算法都会有其缺点,标记/整理算法唯一的缺点就是效率也不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
3.2.4 三色标记算法
三色标记算法是一种垃圾回收的标记算法。它可以让JVM不发生或仅短时间发生STW(Stop The World),从而达到清除JVM内存垃圾的目的。JVM中的CMS、G1垃圾回收器 所使用垃圾回收算法即为三色标记法。
三色标记的过程
黑色:表示对象已经被垃圾收集器访问过了,且是安全存活的。(当该对象被重复扫描是可以跳过)
灰色:表示该对象被垃圾收集器扫描过,但是对象上还存在没有扫描的引用。(需要在该对象中寻找垃圾)
白色:表示未被垃圾收集器访问过(在刚开始阶段,所有对象都是白色,若分析结束后仍是白色,即代表不可达)
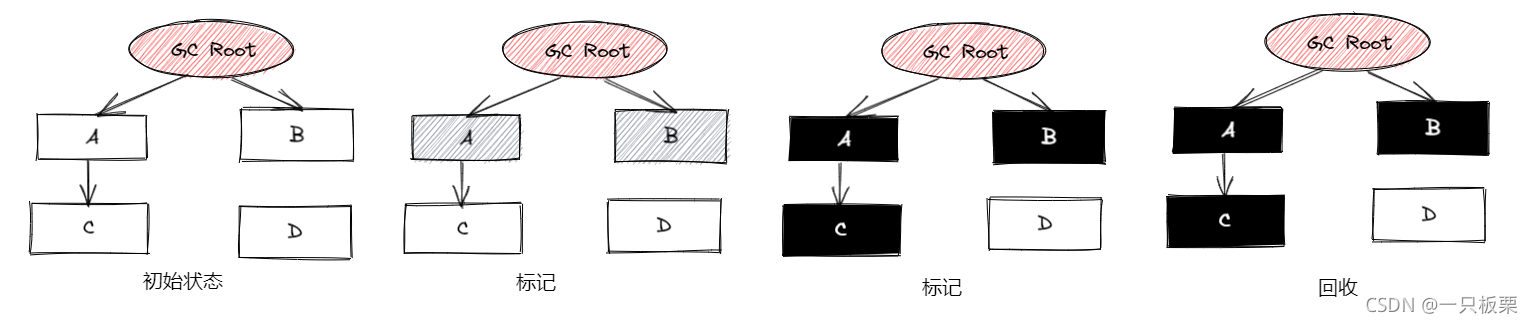
三色标记存在的问题:
如果在垃圾收集器进行标记的过程中,用户线程是暂停的,那么这个标记流程不会有任何问题。坏就坏在标记线程和用户线程是并发执行的(用户线程在修改对象中的引用关系,而垃圾收集器在对对象的引用进行标记),这就可能出现一下两种后果:
- 将原本消亡的对象错误的标记成存活的。
- 将原本存活的对象错误的标记成了消亡。
当且仅当以下两个条件同时满足时,会产生对象消失的问题:
- 赋值器插入了一条或多条从黑色独享到白色对象的新引用
- 赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
如何解决?
通过读写屏障来处理
- 读屏障:在读取一个对象的引用时,记录下引用关系。这个引用可能是从黑色到白色的引用
- 写屏障:在给对象中的变量赋值时,在赋值前和赋值后执行一些逻辑,记录引用关系
在并发标记的过程中通过读写屏障来记录引用关系的变更,在重新标记阶段,去重新标记这些数据。
3.2.5 总结
- 内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度)
- 内存整齐度:复制算法=标记清除算法>标记压缩算法
- 内存利用率:复制算法<标记清除算法=标记压缩算法
3.3 分代垃圾回收
JVM在进行垃圾回收时,并不是只使用某一种算法,而是所有算法都会使用,由此就产生了分代收集算法。
分代收集算法是针对对象的不同特性,而使用适合的算法,这里面并没有实际上的新算法产生。与其说分代搜集算法是第四个算法,不如说它是对前三个算法的实际应用
在内存中对象大致可以分为三类:
- 朝生夕灭:例如方法内的局部变量,循环内的临时变量等
- 老不死:早晚要死的对象,例如缓存。
- 永生:例如常量池,加载的类信息等。
Java堆中内存划分:
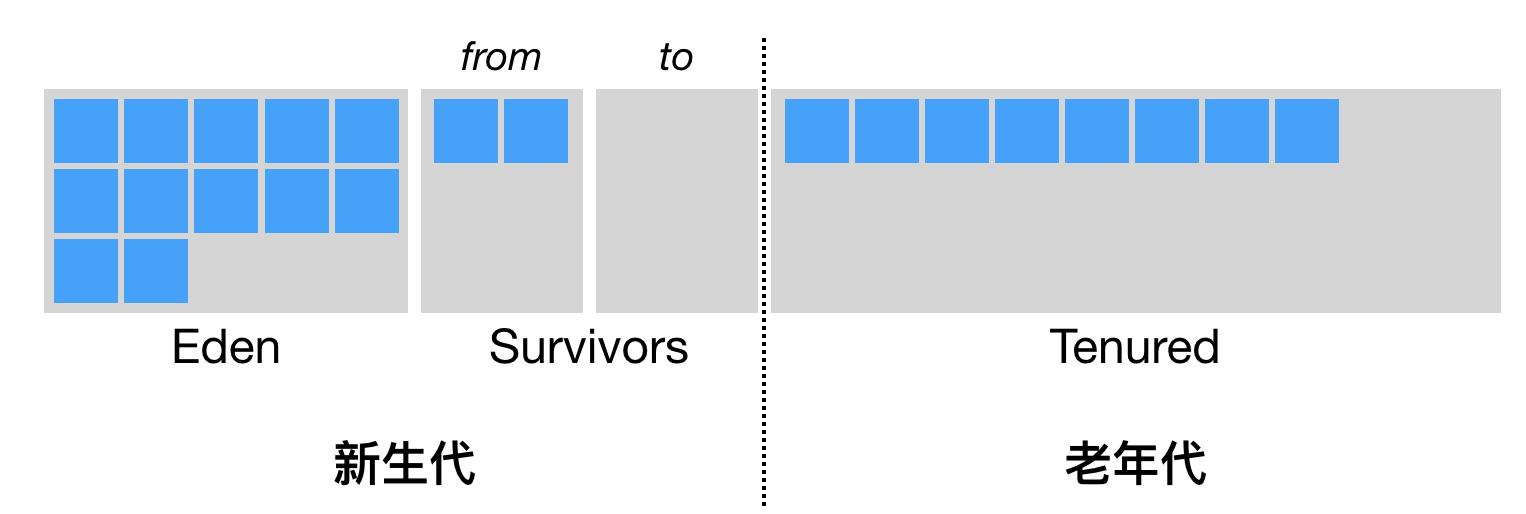
注:在JDK9中开始采用G1回收器,开始采用了新的内存模型,弱化了分新生代和老年代的概念。
3.3.1 新生代内存
Minor GC
对于朝生夕灭类的对象,存活时间短,还记得复制算法的使用要求吗?那就是对象存活率不能太高,因此这类对象是最适合使用复制算法的。
但是50%的内存浪费怎么解决呢?
JVM将新生代内存又划分了3块区域,80%的内存用来给新建对象分配内存,另外两块10%的内存作为对象的幸存区。一旦发生GC,将其中一个10%的幸存区和80%的Eden区的对象转移到另一个10%的幸存区内,每复制一次,年龄加1,接下来,前面90%的内存将全部被释放,(注意这里会一致有一个10%的幸存区是空的,用来在下一次GC保存存对象)
使用这样的方式,我们只浪费了10%的内存,这个是可以接受的,因为我们换来了内存的整齐排列与GC速度。但是这个策略的前提是,每次存活的对象占用的内存不能超过这10%的大小,一旦超过,多出的对象将无法复制。下面老年代开始登场了。
minor GC会触发一次 stop the world (minor gc 通常情况下很快)
3.3.2 老年代内存
通常情况下,以下两种情况发生的时候,对象会从新生代区域转到年老带区域。
在新生代里的每一个对象,都会有一个年龄,当这些对象的年龄到达一定程度时(年龄就是熬过的GC次数,每次GC如果对象存活下来,则年龄加1,最大15次),则会被转到年老代,而这个转入年老代的年龄值,一般在JVM中是可以设置的。
在新生代存活对象占用的内存超过10%时,则多余的对象会放入年老代。这种时候,年老代就是新生代的“备用仓库”。
针对老不死对象的特性,显然不再适合使用复制算法,因为它的存活率太高,而且不要忘了,如果年老代再使用复制算法,它可是没有备用仓库的。因此一般针对老不死对象只能采用标记/整理或者标记/清除算法。
当老年代的空间不足,会先尝试触发minor gc,如果还不足,会触发full gc,full gc所需的时间更长
3.3.3 永久代内存
永久带对应Java内存结构中的方法区,这里没有备用仓库,所以只能使用标记/清除和标记/整理算法。
3.3.4 跨代引用问题
跨代引用是指年轻代的对象引用老年代中的对象,老年代中的对象也会引用年轻代中的对象。那么问题就来了,JVM在进行MinorGC的时候还要去遍历老年代的么?答案当然是不能,那么如何解决?
记忆集
记忆集(Remembered Set),它是在年轻代中建立的一个数据结构,把老年代划分为N个区域,标志出哪个区域会存在跨代引用。这样在进行MinorGC的时候,只要把这些包含了跨代引用的内存区域加入GC Roots一起扫描就行了。
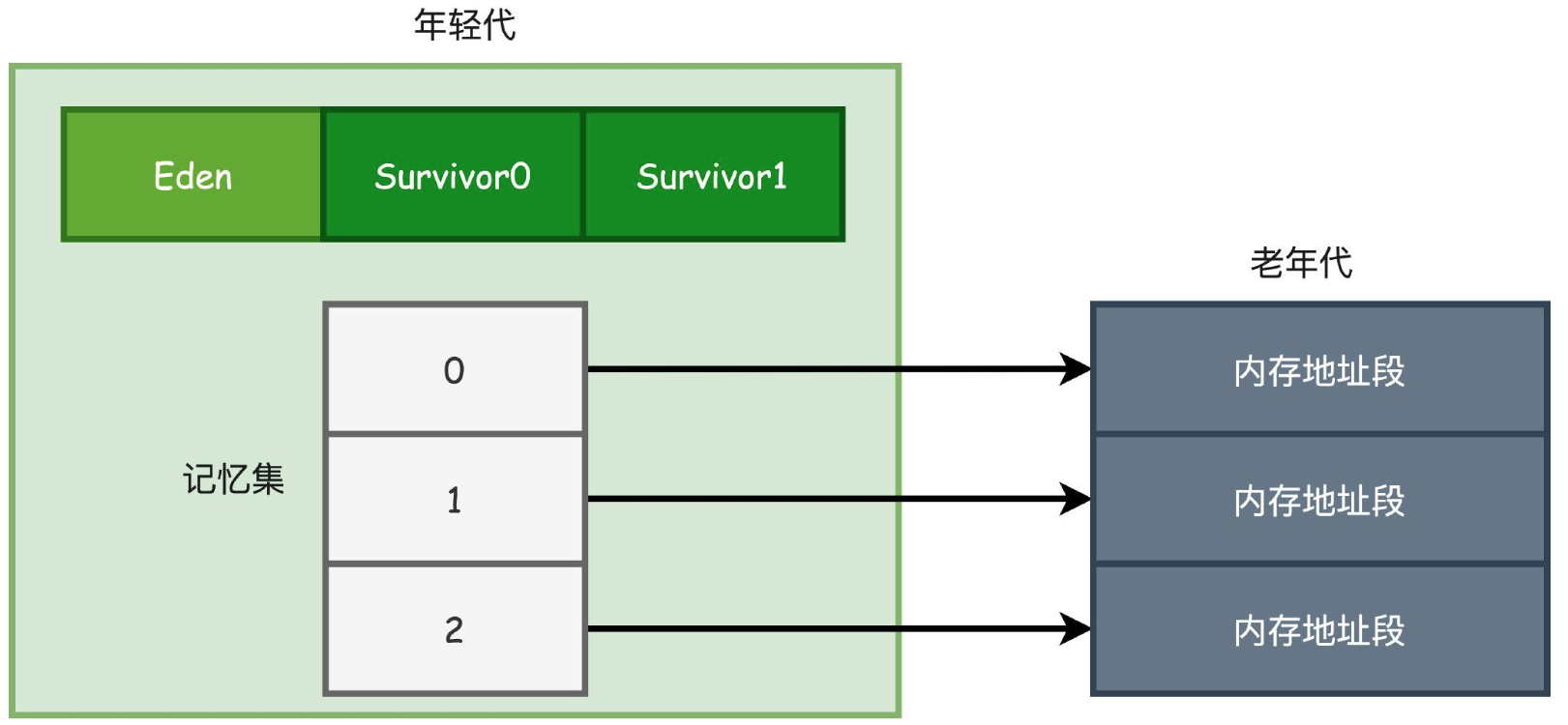
卡表
卡表实际上就是记忆集的一种实现方式,也是目前最常用的一种实现方式。
对于HotSpot虚拟机来说,卡表的实现方式就是一个字节数组。
CARD_TABLE [this address >> 9] = 0;
这段代码代表着卡表标记的的逻辑。实际上卡表就是映射了一块块的内存地址,这些内存地址块称为卡页,从代码可以看出每个卡页的大小就是2^9=512字节。数组的0,1号元素就映射为0x0000~0x01FF(0-511)、0x0200~0x03FF(512-1023)内存地址的卡页。
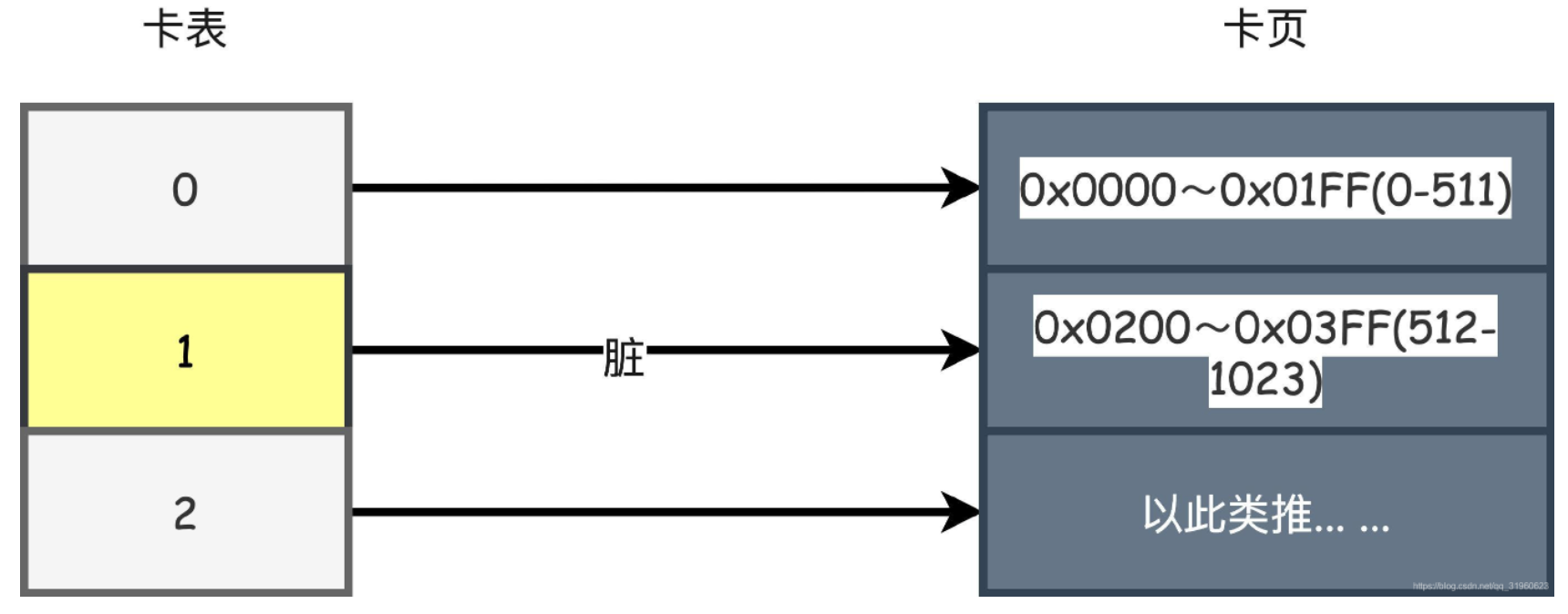
只要一个卡页内的对象存在一个或者多个跨代对象指针,就将该位置的卡表数组元素修改为1,表示这个位置为脏,没有则为0。在GC的时候,就直接把值为1对应的卡页对象指针加入GC Roots一起扫描即可。有了卡表,我们就不需要去在发生MinorGC的时候扫描整个老年代了,性能得到了极大的提升。
写屏障
前面介绍的都是一些思想,JVM是如何实现的呢?
没错,就是写屏障。写屏障类似于AOP的思想,在JVM会在引用类型字段赋值这个动作生成一个Around,在赋值前,赋值后都会执行一些逻辑,如更新卡表信息。但是写屏障会带来一些性能开销,不过和扫描老年代相比,这个性能开销还是可以接收的。
写屏障还存在一个伪共享问题,现代处理器通常是以缓存行为存储单位,缓存行通常来说都是64字节,一个卡表元素1个字节,占用的卡页内存大小就是64*512=32KB的大小。如果多线程刚好更新刚好处于这32KB范围内的对象,那么就会对性能产生影响。
JDK7之后新增了一个参数-XX:+UseCondCardMark,他代表是否开启卡表更新的判断,没有被标记过才标记为脏。
if (CARD_TABLE [this address >> 9] != 0)
CARD_TABLE [this address >> 9] = 0;
一个卡业内数据被修改多次,只有第一次修改卡表。从而减少卡表的修改次数
3.4 垃圾回收器
JVM的相关参数:
| 含义 | 参数 |
|---|---|
| 堆初始大小 | -Xms |
| 堆最大大小 | -Xmx 或 -XX:MaxHeapSize=size |
| 新生代大小 | -Xmn 或 (-XX:NewSize=size + -XX:MaxNewSize=size ) |
| 幸存区比例(动态) | -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy |
| 幸存区比例 | -XX:SurvivorRatio=ratio |
| 晋升阈值 | -XX:MaxTenuringThreshold=threshold |
| 晋升详情 | -XX:+PrintTenuringDistribution |
| GC详情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC 前 MinorGC | -XX:+ScavengeBeforeFullGC |
3.4.1 垃圾回收器的分类
垃圾搜集器大致分为以下三类。
串行搜集器(serial collector):它只有一条GC线程,且就像前面说的,它在运行的时候需要暂停用户程序(stop the world)。
并行搜集器(parallel collector):它有多条GC线程,且它也需要暂停用户程序(stop the world)。
并发搜集器(concurrent collector):它有一条或多条GC线程,且它需要在部分阶段暂停用户程序(stop the world),部分阶段与用户程序并发执行。
3.4.2 HotSport中的垃圾回收器
在hotspotJVM中,每一个种类的垃圾搜集器都有对应的实现,如下。
串行搜集器的实现:serial(用于新生代,采用复制算法)、serial old(用于年老代,采用标记/整理算法)
并行搜集器的实现:ParNew(用于新生代,采用复制算法)、Parallel Scavenge(用于新生代,采用复制算法)、Parallel old(用于年老代,采用标记/整理算法)
并发搜集器的实现:concurrent mark sweep[CMS](用于年老代,采用标记/清除算法)
可以看到,上面每一种垃圾搜集器都是针对不同内存区域所设计的,因为它们采用的算法不同,凡是用于新生代的都是使用的复制算法,而用于年老代的都是使用的标记/清除或者标记/整理算法。
在实际应用中,我们需要给JVM的新生代和年老代分别选择垃圾搜集器,可以看到无论是新生代还是年老代都分别有三种实现,换句话说,我们应该有3*3=9种选择。但是,事实并非如此。
事实上,这六种垃圾搜集器只有六种选择,因为有的垃圾搜集器由于具体实现的方式等一系列原因无法在一起工作,如下图。
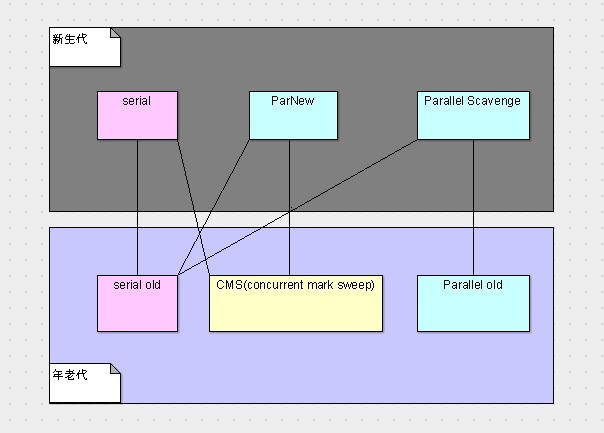
针对上图,红的就是串行搜集器,绿的是并行搜集器,唯一一个黄的是并发搜集器。上面三个是新生代的搜集器,下面三个是年老代的搜集器。两者之间有连线,则表示两者可以配合工作。
这六种组合并没有说哪个组合最强,哪个组合最弱,还是那句话,只有最合适的,没有最好的。因此这就需要我们对每一种组合有一定的认识,才能在使用的时候选择更适合的垃圾搜集器。
下面就开始意义介绍回收器
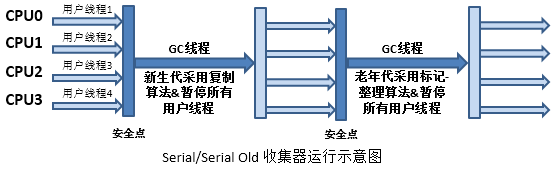
3.4.3 Serial 垃圾回收器
算法:采用复制算法
内存区域:针对新生代设计
执行方式:单线程、串行
执行过程:当新生代内存不够用时,先暂停全部用户程序,然后开启一条GC线程使用复制算法对垃圾进行回收,这一过程中可能会有一些对象提升到年老代
特点:由于单线程运行,且整个GC阶段都要暂停用户程序,因此会造成应用程序停顿时间较长,但对于小规模的程序来说,却非常适合。
适用场景:平时的开发与调试程序使用,以及桌面应用交互程序。
执行流程:
常用参数:
-XX:+UseSerialGC:启用serial垃圾收集器(这个参数会同时启用serial和serial old)
-XX:SurvivorRatio: 调整新生代中的eden比例,默认-XX:SurvivorRatio=8
-XX:+PrintGCDetails: 发生GC是打印日志(JDK9之前有效)
-XX:MaxTenuringThreshold=15: 晋升到老年代的阈值,Parallel默认15,CMS默认6,G1默认15
-XX:PretenureSizeThreshold=3145728: 当对象大于该大小后,直接晋升到老年代。注意这里只能以字节的形式指定
3.4.4 Serial Old 垃圾回收器
算法:标记/整理算法
内存区域:针对新生代设计
其他特性和Serial相似
常用参数:
-XX:+UseSerialGC: Serial + Serial Old
-XX:+UseParallelGC,使用Parallel Scavenge + Serial Old收集器组合。
-XX:+UseConcMarkSweepGC,使用ParNew + CMS + Serial Old收集器组合(JDK9中参数)。
3.4.6 ParNew 垃圾回收器
ParNew收集器其实就是Serial收集器的多线程版本,在JDK9及以后的版本作为CMS默认的新生代垃圾收集器,不在支持单独配置参数。
算法:采用标记复制算法
内存区域:针对新生代设计
执行方式:多线程、并行
执行过程:当新生代内存不够用时,先暂停全部用户程序,然后开启若干条GC线程使用复制算法并行进行垃圾回收,这一过程中可能会有一些对象提升到年老代
特点:采用多线程并行运行,因此会对系统的内核处理器数目比较敏感。同样需要STW。在单核CPU上其性能可不不如Serial 好。
适用场景:在中到大型的堆上,且系统处理器至少多于一个的情况
执行流程:
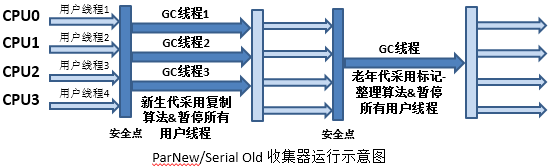
常用参数:
- -XX:+UseParNewGC: 启用ParNew+Serial Old垃圾收集器组合(JDK9取消了该参数)
- -XX:+UseConcMarkSweepGC: 启用ParNew + CMS的垃圾收集器组合(JDK9取消了该参数)
- -XX:ParallelGCThreads=3:代表垃圾回收线程最多可以3条同时运行。
3.4.7 Parallel Scavenge垃圾回收器
Parallel的主要关注点在吞吐量,单位时间内收集的垃圾越多越好。
针对新生代,采用标记复制算法。与ParNew相比,可控制的参数更多。
回收流程:
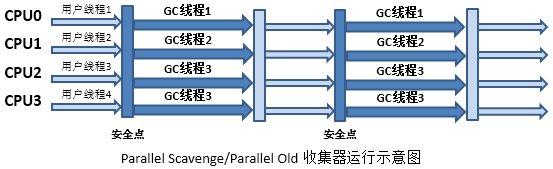
常用参数:
- -XX:+UseParallelGC: 启用Parallel Scavenge + Serial Old组合模式
- -XX:+UseParallelOldGC: 启用Parallel Scavenge + Parallel Old组合模式
- -XX:ParallelGCThreads: 设置垃圾收集线程数
- -XX:MaxGCPauseMillis=200: 指定最大停顿时间,默认200毫秒
- -XX:GCTimeRatio=99: 代表垃圾收集时间所占比例,计算公式1/(1+99),
- -XX:+UseAdaptiveSizePolicy: 这是一个开关参数,开启后,JVM会根据-XX:MaxGCPauseMillis=200和-XX:GCTimeRatio=99这两个参数动态调整-Xmx、-Xms、-Xmn、-XX:SurvivorRatio、-XX:PretenureSizeThreshold等参数,来最大限度的提升吞吐量。
3.4.8 Parallel Old 垃圾回收器
针对年老代设计的并行搜集器,采用标记/整理算法。
可以和serial 、parallel scavenge 搭配使用。在JDK8及以前是默认的垃圾收集器。
执行流程和常用的参数与Parallel Scavenge相同,这里不在介绍。
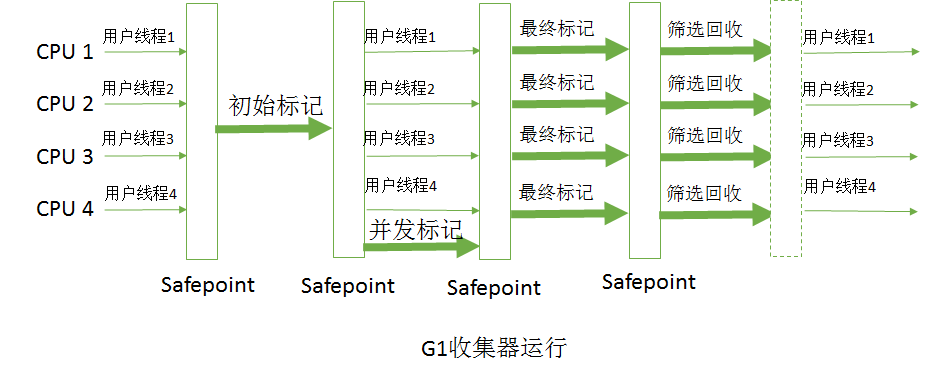
3.4.9 CMS 垃圾回收器
CMS是针对年老代设计的搜集器,并采用标记/清除算法,它也是唯一一个在年老代采用标记/清除算法的搜集器。
CMS垃圾收集器主要分为以下五个阶段。
1、初始标记:只标记和GCRoots直接关联的对象,以及年轻代指向老年代的对象(需要Stop The World)
2、并发标记:和用户线程并行执行,根据初试标记结果做可达性分析。(三色标记)
3、重新标记:需要暂停应用程序,处理并发标记中错标或漏标的对象。(三色标记存在的问题)
4、并发清除:并发清除垃圾对象
5、并发重置:重置本次GC过程中的标记数据。
CMS主要关注点在用户体验,他的终极目标是尽量减少总体的STW的时间
执行流程:
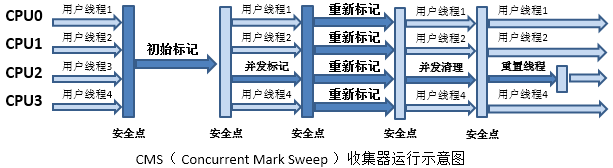
常用参数:
- -XX:+UseConcMarkSweepGC: 使用ParNew + CMS的组合
- -XX:CMSInitiatingOccupancyFraction=92
- -XX:ParallelGCThread=3 垃圾收集线程数
- -XX:SurvivorRatio: 调整新生代中的eden比例,默认-XX:SurvivorRatio=8
- -XX:MaxTenuringThreshold=15: 晋升到老年代的阈值,Parallel默认15,CMS默认6,G1默认15
优点:
- 并发收集,低停顿
缺点:
- 对CPU资源敏感,用户线程和垃圾收集线程会争抢资源,会对垃圾收集的吞吐量造成影响。
- 标记清除会产生内存碎片
- -XX:+UseCMSCompactAtFullCollection:开启在全局Full GC后执行碎片整理工作
- -XX:CMSFullGCsBeforeCompaction:控制在几次Full GC后进行一次碎片整理。(每次都整理开销大)
- 无法处理浮动垃圾:初始标记后,堆内存中会产生一些新的GCRoots,在并发标记的过程中,也会存在一些标记为活动的对象变为垃圾对象的情况。这些垃圾对象在本次垃圾扫描中是无法被回收的。
- 并发失败模式,意思就是内存回收的速度追不上内存分配的速度,导致没有内存可以分配,这时候就会暂停用户线程,全力清理垃圾,知道回收完成才恢复用户线程
- 这里的无内存分配,可能是浮动垃圾造成的。也可能是内存碎片问题。
- -XX:CMSInitiatingOccupancyFraction=90 控制老年代的内存占用比例到达多少时,开启老年代的垃圾回收
3.4.10 Garbage First垃圾回收器
TODO https://blog.csdn.net/u011381576/article/details/79889804
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一。早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术。同优秀的CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器,也同样适合大尺寸堆内存的垃圾收集,官方也推荐使用G1来代替选择CMS。G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。
之前介绍的几组垃圾收集器组合,都有几个共同点:
- 年轻代、老年代是独立且连续的内存块;
- 年轻代收集使用单eden、双survivor进行复制算法;
- 老年代收集必须扫描整个老年代区域;
- 都是以尽可能少而块地执行GC为设计原则。
G1垃圾收集器也是以关注延迟为目标、服务器端应用的垃圾收集器,被HotSpot团队寄予取代CMS的使命,也是一个非常具有调优潜力的垃圾收集器。虽然G1也有类似CMS的收集动作:初始标记、并发标记、重新标记、清除、转移回收,并且也以一个串行收集器做担保机制,但单纯地以类似前三种的过程描述显得并不是很妥当。事实上,G1收集与以上三组收集器有很大不同:
- G1的设计原则是”首先收集尽可能多的垃圾(Garbage First)“。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大;
- G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
- G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
- G1的收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而降低停顿。
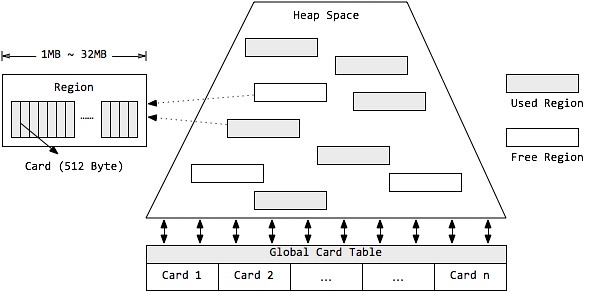
G1的内存模型
如下图所示:
分区 Region
G1采用了分区(Region)的思路,将整个堆空间分成若干个大小相等的内存区域,每次分配对象空间将逐段地使用内存。因此,在堆的使用上,G1并不要求对象的存储一定是物理上连续的,只要逻辑上连续即可;每个分区也不会确定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,且必须是2的幂),默认将整堆划分为2048个分区。
卡片 Card
在每个分区内部又被分成了若干个大小为512 Byte卡片(Card),标识堆内存最小可用粒度所有分区的卡片将会记录在全局卡片表(Global Card Table)中,分配的对象会占用物理上连续的若干个卡片,当查找对分区内对象的引用时便可通过记录卡片来查找该引用对象(见RSet)。每次对内存的回收,都是对指定分区的卡片进行处理。
堆 Heap
G1同样可以通过-Xms/-Xmx来指定堆空间大小。当发生年轻代收集或混合收集时,通过计算GC与应用的耗费时间比,自动调整堆空间大小。如果GC频率太高,则通过增加堆尺寸,来减少GC频率,相应地GC占用的时间也随之降低;目标参数-XX:GCTimeRatio即为GC与应用的耗费时间比,G1默认为9,而CMS默认为99,因为CMS的设计原则是耗费在GC上的时间尽可能的少。另外,当空间不足,如对象空间分配或转移失败时,G1会首先尝试增加堆空间,如果扩容失败,则发起担保的Full GC。Full GC后,堆尺寸计算结果也会调整堆空间。
G1的分代模型
如下图所示,G1依然使用了分代的思想。与其他垃圾收集器类似,G1将内存在逻辑上划分为年轻代和老年代,其中年轻代又划分为Eden空间和Survivor空间。但年轻代空间并不是固定不变的,当现有年轻代分区占满时,JVM会分配新的空闲分区加入到年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)与最大空间-XX:G1MaxNewSizePercent(默认60%)之间动态变化,且由参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms)、需要扩缩容的大小以及分区的已记忆集合(RSet)计算得到。当然,G1依然可以设置固定的年轻代大小(参数-XX:NewRatio、-Xmn),但同时暂停目标将失去意义。
G1的分区模型
G1对内存的使用以分区(Region)为单位,而对对象的分配则以卡片(Card)为单位。
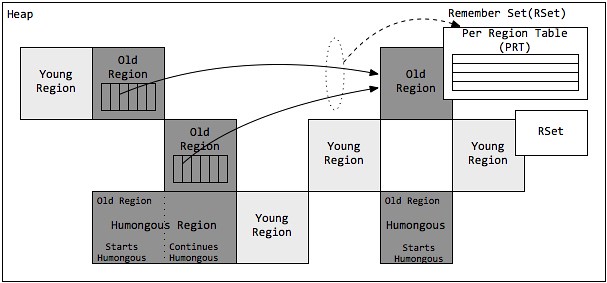
巨型对象 Humongous Region
一个大小达到甚至超过分区大小一半的对象称为巨型对象(Humongous Object)。当线程为巨型分配空间时,不能简单在TLAB进行分配,因为巨型对象的移动成本很高,而且有可能一个分区不能容纳巨型对象。因此,巨型对象会直接在老年代分配,所占用的连续空间称为巨型分区(Humongous Region)。G1内部做了一个优化,一旦发现没有引用指向巨型对象,则可直接在年轻代收集周期中被回收。
巨型对象会独占一个、或多个连续分区,其中第一个分区被标记为开始巨型(StartsHumongous),相邻连续分区被标记为连续巨型(ContinuesHumongous)。由于无法享受Lab带来的优化,并且确定一片连续的内存空间需要扫描整堆,因此确定巨型对象开始位置的成本非常高,如果可以,应用程序应避免生成巨型对象。
记忆集合 Remember Set (RSet)
在串行和并行收集器中,GC通过整堆扫描,来确定对象是否处于可达路径中。然而G1为了避免STW式的整堆扫描,在每个分区记录了一个已记忆集合(RSet),内部类似一个反向指针,记录引用分区内对象的卡片索引。当要回收该分区时,通过扫描分区的RSet,来确定引用本分区内的对象是否存活,进而确定本分区内的对象存活情况。
事实上,并非所有的引用都需要记录在RSet中,如果一个分区确定需要扫描,那么无需RSet也可以无遗漏的得到引用关系。那么引用源自本分区的对象,当然不用落入RSet中;同时,G1 GC每次都会对年轻代进行整体收集,因此引用源自年轻代的对象,也不需要在RSet中记录。最后只有老年代的分区可能会有RSet记录,这些分区称为拥有RSet分区(an RSet’s owning region)。
Per Region Table (PRT)
RSet在内部使用Per Region Table(PRT)记录分区的引用情况。由于RSet的记录要占用分区的空间,如果一个分区非常”受欢迎”,那么RSet占用的空间会上升,从而降低分区的可用空间。G1应对这个问题采用了改变RSet的密度的方式,在PRT中将会以三种模式记录引用:
- 稀少:直接记录引用对象的卡片索引
- 细粒度:记录引用对象的分区索引
- 粗粒度:只记录引用情况,每个分区对应一个比特位
由上可知,粗粒度的PRT只是记录了引用数量,需要通过整堆扫描才能找出所有引用,因此扫描速度也是最慢的。
收集集合 (Collect Set,CSet)
收集集合(CSet)代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
候选老年代分区的CSet准入条件,可以通过活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)进行设置,从而拦截那些回收开销巨大的对象;同时,每次混合收集可以包含候选老年代分区,可根据CSet对堆的总大小占比-XX:G1OldCSetRegionThresholdPercent(默认10%)设置数量上限。
由上述可知,G1的收集都是根据CSet进行操作的,年轻代收集与混合收集没有明显的不同,最大的区别在于两种收集的触发条件。
年轻代收集集合 CSet of Young Collection
应用线程不断活动后,年轻代空间会被逐渐填满。当JVM分配对象到Eden区域失败(Eden区已满)时,便会触发一次STW式的年轻代收集。在年轻代收集中,Eden分区存活的对象将被拷贝到Survivor分区;原有Survivor分区存活的对象,将根据任期阈值(tenuring threshold)分别晋升到PLAB中,新的survivor分区和老年代分区。而原有的年轻代分区将被整体回收掉。
同时,年轻代收集还负责维护对象的年龄(存活次数),辅助判断老化(tenuring)对象晋升的时候是到Survivor分区还是到老年代分区。年轻代收集首先先将晋升对象尺寸总和、对象年龄信息维护到年龄表中,再根据年龄表、Survivor尺寸、Survivor填充容量-XX:TargetSurvivorRatio(默认50%)、最大任期阈值-XX:MaxTenuringThreshold(默认15),计算出一个恰当的任期阈值,凡是超过任期阈值的对象都会被晋升到老年代。
混合收集集合 CSet of Mixed Collection
年轻代收集不断活动后,老年代的空间也会被逐渐填充。当老年代占用空间超过整堆比IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1就会启动一次混合垃圾收集周期。为了满足暂停目标,G1可能不能一口气将所有的候选分区收集掉,因此G1可能会产生连续多次的混合收集与应用线程交替执行,每次STW的混合收集与年轻代收集过程相类似。
为了确定包含到年轻代收集集合CSet的老年代分区,JVM通过参数混合周期的最大总次数-XX:G1MixedGCCountTarget(默认8)、堆废物百分比-XX:G1HeapWastePercent(默认5%)。通过候选老年代分区总数与混合周期最大总次数,确定每次包含到CSet的最小分区数量;根据堆废物百分比,当收集达到参数时,不再启动新的混合收集。而每次添加到CSet的分区,则通过计算得到的GC效率进行安排。
G1的收集周期
并发标记周期是G1中非常重要的阶段,这个阶段将会为混合收集周期识别垃圾最多的老年代分区。整个周期完成根标记、识别所有(可能)存活对象,并计算每个分区的活跃度,从而确定GC效率等级。
当达到IHOP阈值-XX:InitiatingHeapOccupancyPercent(老年代占整堆比,默认45%)时,便会触发并发标记周期。**整个并发标记周期将由初始标记(Initial Mark)、根分区扫描(Root Region Scanning)、并发标记(Concurrent Marking)、重新标记(Remark)、清除(Cleanup)几个阶段组成。**其中,初始标记(随年轻代收集一起活动)、重新标记、清除是STW的,而并发标记如果来不及标记存活对象,则可能在并发标记过程中,G1又触发了几次年轻代收集。
初始标记(Initial Mark)
初始标记(Initial Mark)负责标记所有能被直接可达的根对象(原生栈对象、全局对象、JNI对象),根是对象图的起点,因此初始标记需要将Mutator线程(Java应用线程)暂停掉,也就是需要一个STW的时间段。事实上,当达到IHOP阈值时,G1并不会立即发起并发标记周期,而是等待下一次年轻代收集,利用年轻代收集的STW时间段,完成初始标记,这种方式称为借道(Piggybacking)。
根分区扫描(Root Region Scanning)
在初始标记暂停结束后,年轻代收集也完成的对象复制到Survivor的工作,应用线程开始活跃起来。此时为了保证标记算法的正确性,所有新复制到Survivor分区的对象,都需要被扫描并标记成根,这个过程称为根分区扫描(Root Region Scanning),同时扫描的Suvivor分区也被称为根分区(Root Region)。根分区扫描必须在下一次年轻代垃圾收集启动前完成(并发标记的过程中,可能会被若干次年轻代垃圾收集打断),因为每次GC会产生新的存活对象集合。
并发标记(Concurrent Marking)
并发标记 Concurrent Marking和应用线程并发执行,并发标记线程在并发标记阶段启动,由参数-XX:ConcGCThreads(默认GC线程数的1/4,即-XX:ParallelGCThreads/4)控制启动数量,每个线程每次只扫描一个分区,从而标记出存活对象图。在这一阶段会处理Previous/Next标记位图,扫描标记对象的引用字段。同时,并发标记线程还会定期检查和处理STAB全局缓冲区列表的记录,更新对象引用信息。参数-XX:+ClassUnloadingWithConcurrentMark会开启一个优化,如果一个类不可达(不是对象不可达),则在重新标记阶段,这个类就会被直接卸载。所有的标记任务必须在堆满前就完成扫描,如果并发标记耗时很长,那么有可能在并发标记过程中,又经历了几次年轻代收集。如果堆满前没有完成标记任务,则会触发担保机制,经历一次长时间的串行Full GC。
重新标记
重新标记(Remark)是最后一个标记阶段。在该阶段中,G1需要一个暂停的时间,去处理剩下的SATB日志缓冲区和所有更新,找出所有未被访问的存活对象,同时安全完成存活数据计算。这个阶段也是并行执行的,通过参数-XX:ParallelGCThread可设置GC暂停时可用的GC线程数。同时,引用处理也是重新标记阶段的一部分,所有重度使用引用对象(弱引用、软引用、虚引用、最终引用)的应用都会在引用处理上产生开销。
清除 Cleanup
紧挨着重新标记阶段的清除(Clean)阶段也是STW的。Previous/Next标记位图、以及PTAMS/NTAMS,都会在清除阶段交换角色。清除阶段主要执行以下操作:
1、RSet梳理,启发式算法会根据活跃度和RSet尺寸对分区定义不同等级,同时RSet数理也有助于发现无用的引用。参数-XX:+PrintAdaptiveSizePolicy可以开启打印启发式算法决策细节;
2、整理堆分区,为混合收集周期识别回收收益高(基于释放空间和暂停目标)的老年代分区集合;
3、识别所有空闲分区,即发现无存活对象的分区。该分区可在清除阶段直接回收,无需等待下次收集周期。
常用参数:
- -Xss256k,设置虚拟机栈大小
- -Xmx10m,设置堆最大内存
- -Xms10m,设置堆最小内存
- -XX:ConcGCThreads=2,并发标记阶段使用线程数,可适当高一点。
- -XX:G1NewSizePercen=5,新生代占用堆最小值,默认5%
- -XX:G1MaxNewSizePercent=60,新生代占用最大值,默认60%
- -XX:MetaSpaceSize=10m,方法区最小值(元空间)
- -XX:MaxMetaSpaceSize=10m,方法区最大子,默认-1,没有最大
- -XX:InitiatingHeapOccpancyPercent=92,触发G1的内存使用率
- -XX:SurvivorRatio=8,Eden区域所占10份中的比例
- -XX:ParallelGCThreads=2,收集线程的个数一般与服务器核心数相同
- -XX:MaxTenuringThreshold=15,设置进入老年代对象的年龄。
- -XX:+UseG1GC,使用G1收集器
- -XX:MaxGCPauseMillis=200,设置最大停顿时间,默认就是200毫秒
- -XX:G1HeapRegionSize=2,设置每个Region的大小,该值取值范围是1-32,且必须是2的n次幂,当对象的值达到Region设置的值的一半时,被设为大对象会存入humongous区域,更大的对象存储在N个连续的Humongous Region中,G1中的大多数行为都把Humongous Region看做老年代的一部分。
3.5 对象内存的分配
3.6 垃圾回收调优
相关博客:
https://www.cnblogs.com/zuoxiaolong/category/508918.html