JVM 内存结构
JVM 内存结构
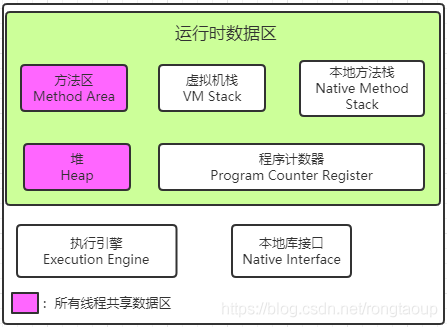
运行时数据区
博客:(41条消息) 一文搞懂JVM内存结构_xiaokanfuchen86的博客-CSDN博客_jvm内存结构
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分为若干个不同的数据区域。每个区域都有各自的作用。JVM 的运行时数据区主要包括:堆、栈、方法区、程序计数器等。而 JVM 的优化问题主要在线程共享的数据区中:堆、方法区。
程序计数器
Program Counter Register 程序计数器(寄存器)
作用,是记住下一条jvm指令的执行地址
特点
是线程私有的
不会存在内存溢出
下面给出一个例子:
0: getstatic #20 // PrintStream out = System.out;
3: astore_1 // --
4: aload_1 // out.println(1);
5: iconst_1 // --
6: invokevirtual #26 // --
9: aload_1 // out.println(2);
10: iconst_2 // --
11: invokevirtual #26 // --
14: aload_1 // out.println(3);
15: iconst_3 // --
16: invokevirtual #26 // --
19: aload_1 // out.println(4);
20: iconst_4 // --
21: invokevirtual #26 // --
24: aload_1 // out.println(5);
25: iconst_5 // --
26: invokevirtual #26 // --
29: return
以上代码的右侧是Java的源代码,左侧是二进制字节码,JVM的指令
JVM的执行流程:
JVM指令 -> 解释器 -> 机器码 -> CPU
程序计数器(Program Counter Register)是一块较小的内存空间,可以看作是当前线程所执行字节码的行号指示器,指向下一个将要执行的指令代码,由执行引擎来读取下一条指令。更确切的说,一个线程的执行,是通过字节码解释器改变当前线程的计数器的值,来获取下一条需要执行的字节码指令,从而确保线程的正确执行。
为了确保线程切换后(上下文切换)能恢复到正确的执行位置,每个线程都有一个独立的程序计数器,各个线程的计数器互不影响,独立存储。也就是说程序计数器是线程私有的内存。
如果线程执行 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果执行的是 Native 方法,计数器值为Undefined。
程序计数器不会发生内存溢出(OutOfMemoryError即OOM)问题。
虚拟机栈
定义
Java Virtual Machine Stacks (Java 虚拟机栈)
- 线程私有的
- 声明周期与线程相同
- 每个线程运行时所需要的内存,称为虚拟机栈
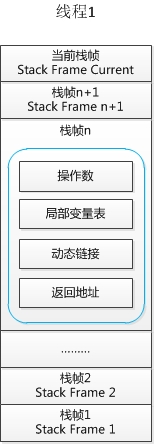
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
栈帧是栈的元素。每个方法在执行时都会创建一个栈帧。栈帧中存储了局部变量表、操作数栈、动态连接和方法出口等信息。每个方法从调用到运行结束的过程,就对应着一个栈帧在栈中压栈到出栈的过程。
局部变量表存放了编译期可知的Java基本数据类型、对象引用(可以理解为指针)和returnAddress 类型(指向了一条字节码指令的地址)。 局部变量表所需内存空间在编译器分配,在运行期间不会改变。
相关参数
JVM虚拟机栈的大小可以通过参数来指定 -Xss size
默认的单位是字节,也可以指定单位,如KB(k,K)、MB(m,M)、GB(g,G)
-Xss1m
-Xss1024KB
栈的大小决定了函数调用的最大深度,如果函数调用的深度大于设置的Xss大小,那么将会抛“java.lang.StackOverflowError“ 异常。
默认的情况下,栈的大小是1024KB(windows系统例外,大小依赖于虚拟内存)
面试题:
垃圾回收是否涉及栈内存?
不需要,栈内存随着栈针的出栈而自动回收掉,所以不需要垃圾回收器来管理。
占内存分配的越大越好么?
占内存过大会导致单线程占用的内存过大,总的线程数变少,不建议调整,使用默认即可。
方法的局部变量是否线程安全?
局部变量是线程私有的,不存在线程安全问题。
虚拟机栈和本地方法栈的区别?
Java 虚拟机栈为 JVM 执行 Java 方法服务,本地方法栈则为 JVM 使用到的 Native 方法服务。
案例1:CPU占用过多
定位过程:
用top定位哪个进程对cpu的占用过高
ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
jstack 进程id。可以根据线程id 找到有问题的线程,进一步定位到问题代码的源码行号
这里注意一下,ps输出的线程号是十进制的,jstack输出的线程编号是十六进制的。
案例2:程序运行很长时间没有结果
本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈的作用非常相似,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
Java堆
几乎所有的对象实例以及数组都在堆里分配内存。通过new关键字创建的对象,都会使用堆内存。
特点:
- 它是线程共享的,堆中的对象都需要考虑线程安全问题
- 有垃圾回收机制
参数控制:
- -Xms设置堆的最小空间大小。-Xmx设置堆的最大空间大小。
异常情况:
- 如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError 异常
方法区
方法区同 Java 堆一样是被所有线程共享的区间,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
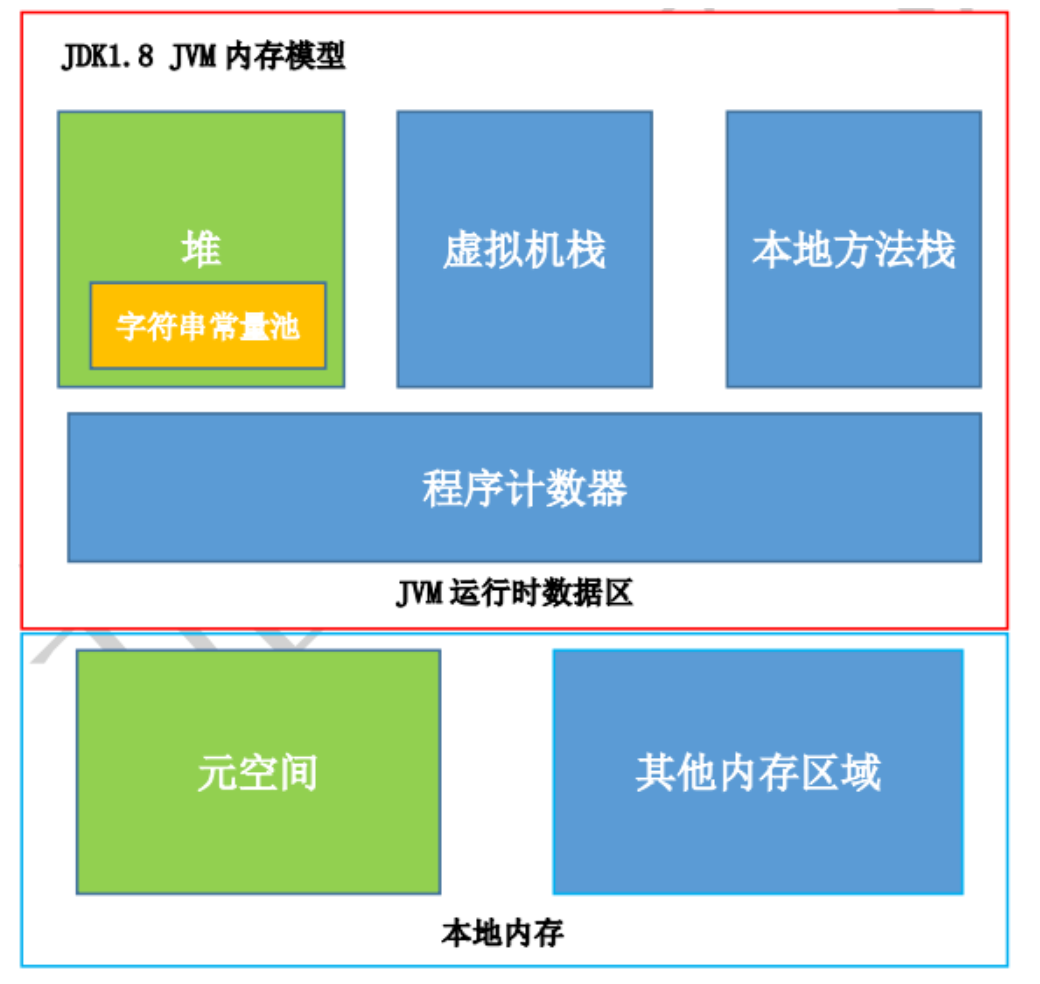
注:JDK1.8 使用元空间 MetaSpace 替代方法区,元空间并不在 JVM中,而是使用本地内存。元空间两个参数:
- MetaSpaceSize:初始化元空间大小,控制发生GC阈值
- MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
运行时常量池
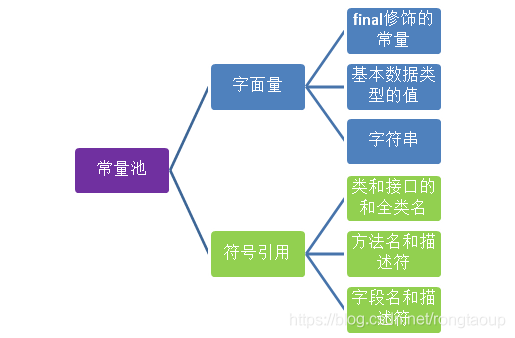
Class文件中除了类的版本,字段,方法,接口等,还有常量池表。常量池表中用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
当常量池无法再申请到内存时会抛出OutOfMemoryError异常。
注:JDK8以后,常量池保存在堆中。
优点:
- 常量池避免了频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
Class常量池
定义:Class常量池可以理解为是Class文件中的资源仓库。
**内容:**Class文件中除了包含类的版本、字段、方法、接口等描述信息外, 还有一项信息就是常量池,用于存放编译期生成的各种字面量和符号引用。
首先有如下类文件定义:
public class Test {
public static void main(String[] args) {
System.out.println("hello world");
}
}
我们通过java提供的工具来查看编译后的Test.class文件的详细信息
查看命令:
javap -v Test.class
详细信息如下:
Classfile /D:/developer/gitee/spring-demo/java-demo/data-structure/src/test/java/Test.class
Last modified 2022-5-11; size 413 bytes
MD5 checksum ae5ed4a0ee5b45fd449f77ade8d7bd24
Compiled from "Test.java"
public class Test
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool: 这里就是这个类需要的常量,运行后,会保存到常量池中,#后面的数字也会变为真时的内存地址。
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // hello world
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // Test
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 Test.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 hello world
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 Test
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
public Test();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 4: 0
line 5: 8
}
SourceFile: "Test.java"
字面量
定义:字面量就是指由字母、数字等构成的字符串或者数值常量。
**PS:**字面量只可以右值出现【等号右边的值】如:int a = 1 这里的a为左值,1为右值。在这个例子中1就是字面量。
private int compute() {
int a = 1;//符号引用:a 字面量:1
int b = 2;//符号引用:b 字面量:2
String c = "有梦想的肥宅";//符号引用:c 字面量:有梦想的肥宅
return a + b;
}
符号引用
符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
符号引用只有到运行时被加载到内存后,这些符号才有对应的内存地址信息,这些常量池一旦被装入内存就变成运行时常量池,也就引出了下面动态链接的概念。
**动态链接:**对应的符号引用在程序加载或运行时会被转变为被加载到内存区域的代码的直接引用。
**例:**compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址,主要通过对象头里的类型指针去转换直接引用。
字符串常量池
字符串的分配和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化:
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先查询字符串常量池是否存在该字符串
- 存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
三种字符串操作(Jdk1.7 及以上版本)
直接赋值
String s = "有梦想的肥宅"; // s :指向常量池中的引用**PS:**这种方式创建的字符串对象,只会在常量池中。
创建步骤:
JVM会先去常量池中通过 equals(key) 方法,判断是否有相同的对象:
- 有,则直接返回该对象在常量池中的引用
- 没有,则会在常量池中创建一个新对象,再返回引用
new String()方法创建
String s1 = new String("有梦想的肥宅"); // s1指向内存中的对象引用PS:这种方式会保证字符串常量池和堆中都有这个对象,没有就创建,最后返回堆内存中的对象引用。
创建步骤:
因为有"有梦想的肥宅"这个字面量,所以会先检查字符串常量池中是否存在此字符串:
- 不存在,先在字符串常量池里创建一个字符串对象,再去堆内存中创建一个字符串对象"有梦想的肥宅"
- 存在,就直接去堆内存中创建一个字符串对象"有梦想的肥宅", 最后,将内存中的引用返回
intern()方法
String s1 = new String("有梦想的肥宅"); String s2 = s1.intern(); //s1.intern()返回的串池中的对象,s1引用的是堆中的对象 System.out.println(s1 == s2); //false**PS:**这个方法是尝试将字符串对象放入串池,如果有则不放入,如果没有则放入串池,并把串池中的对象返回。
创建步骤:
还是会去常量池找看有没有"有梦想的肥宅"这个字符串:
- 存在,则返回串池中的对象引用
- 不存在,把字符串放入串池,并返回串池中的对象 引用
**PS:**jdk1.6版本需要将 s1 复制到字符串常量池里
八种基本类型的包装类和对象池
java中基本类型的包装类的大部分都实现了常量池技术(严格来说对象在堆上应该叫对象池),这些类是 Byte、Short、Integer、Long、Character、Boolean,另外两种浮点数类型的包装类则没有实现。
**PS:**Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,因为一般这种比较小的数用到的概率相对较大。
public class Test {
public static void main(String[] args) {
//1、5种整形的包装类Byte,Short,Integer,Long,Character的对象,在值小于127时可以使用对象池
Integer i1 = 127; //PS:这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
Integer i2 = 127;
System.out.println(i1 == i2);//输出true
//2、当值大于127时,不会从对象池中取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//输出false
//3、用new关键词新生成对象不会使用对象池
Integer i5 = new Integer(127);
Integer i6 = new Integer(127);
System.out.println(i5 == i6);//输出false
//4、Boolean类也实现了对象池技术
Boolean bool1 = true;
Boolean bool2 = true;
System.out.println(bool1 == bool2);//输出true
//5、浮点类型的包装类没有实现对象池技术
Double d1 = 1.0D;
Double d2 = 1.0D;
System.out.println(d1 == d2);//输出false
}
}
StringTable详解(就是串池)
首先来看一个代码示例:
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
public static void main(String[] args) {
String s1 = "a"; // 懒惰的
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
// new String 会在常量池和堆内存中同时创建对象,但引用的是堆内存中的引用
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5);
String ap = new String("a")+new String("b");
// 这里注意一下,通过new 相加,这里a,b都会检查常量池,但是最后生成的结果"ab"不会保存到常量池
}
}
编译过程中遇到编码问题,可以通过-encoding来指定编码,如下:
javac -encoding utf-8 Demo1_22.java
来查看一下编译后文件的详细信息:
Classfile /D:/path/to/Demo1_22.class
Last modified 2022-5-11; size 776 bytes
MD5 checksum 141d5699097730cd03bba544e9b27e1c
Compiled from "Demo1_22.java"
public class cn.itcast.jvm.t1.stringtable.Demo1_22
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #12.#25 // java/lang/Object."<init>":()V
#2 = String #26 // a
#3 = String #27 // b
#4 = String #28 // ab
#5 = Class #29 // java/lang/StringBuilder
#6 = Methodref #5.#25 // java/lang/StringBuilder."<init>":()V
#7 = Methodref #5.#30 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#8 = Methodref #5.#31 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#9 = Fieldref #32.#33 // java/lang/System.out:Ljava/io/PrintStream;
#10 = Methodref #34.#35 // java/io/PrintStream.println:(Z)V
#11 = Class #36 // cn/itcast/jvm/t1/stringtable/Demo1_22
#12 = Class #37 // java/lang/Object
#13 = Utf8 <init>
#14 = Utf8 ()V
#15 = Utf8 Code
#16 = Utf8 LineNumberTable
#17 = Utf8 main
#18 = Utf8 ([Ljava/lang/String;)V
#19 = Utf8 StackMapTable
#20 = Class #38 // "[Ljava/lang/String;"
#21 = Class #39 // java/lang/String
#22 = Class #40 // java/io/PrintStream
#23 = Utf8 SourceFile
#24 = Utf8 Demo1_22.java
#25 = NameAndType #13:#14 // "<init>":()V
#26 = Utf8 a
#27 = Utf8 b
#28 = Utf8 ab
#29 = Utf8 java/lang/StringBuilder
#30 = NameAndType #41:#42 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#31 = NameAndType #43:#44 // toString:()Ljava/lang/String;
#32 = Class #45 // java/lang/System
#33 = NameAndType #46:#47 // out:Ljava/io/PrintStream;
#34 = Class #40 // java/io/PrintStream
#35 = NameAndType #48:#49 // println:(Z)V
#36 = Utf8 cn/itcast/jvm/t1/stringtable/Demo1_22
#37 = Utf8 java/lang/Object
#38 = Utf8 [Ljava/lang/String;
#39 = Utf8 java/lang/String
#40 = Utf8 java/io/PrintStream
#41 = Utf8 append
#42 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#43 = Utf8 toString
#44 = Utf8 ()Ljava/lang/String;
#45 = Utf8 java/lang/System
#46 = Utf8 out
#47 = Utf8 Ljava/io/PrintStream;
#48 = Utf8 println
#49 = Utf8 (Z)V
{
public cn.itcast.jvm.t1.stringtable.Demo1_22();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=6, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
27: astore 4
29: ldc #4 // String ab
31: astore 5
33: getstatic #9 // Field java/lang/System.out:Ljava/io/PrintStream;
36: aload_3
37: aload 5
39: if_acmpne 46
42: iconst_1
43: goto 47
46: iconst_0
47: invokevirtual #10 // Method java/io/PrintStream.println:(Z)V
50: return
LineNumberTable:
line 11: 0
line 12: 3
line 13: 6
line 14: 9
line 15: 29
line 17: 33
line 21: 50
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 46
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream ]
frame_type = 255 /* full_frame */
offset_delta = 0
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream, int ]
}
SourceFile: "Demo1_22.java"
下面来看几道面试题:
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
StringTable存储位置
Java 8 中的存储位置:
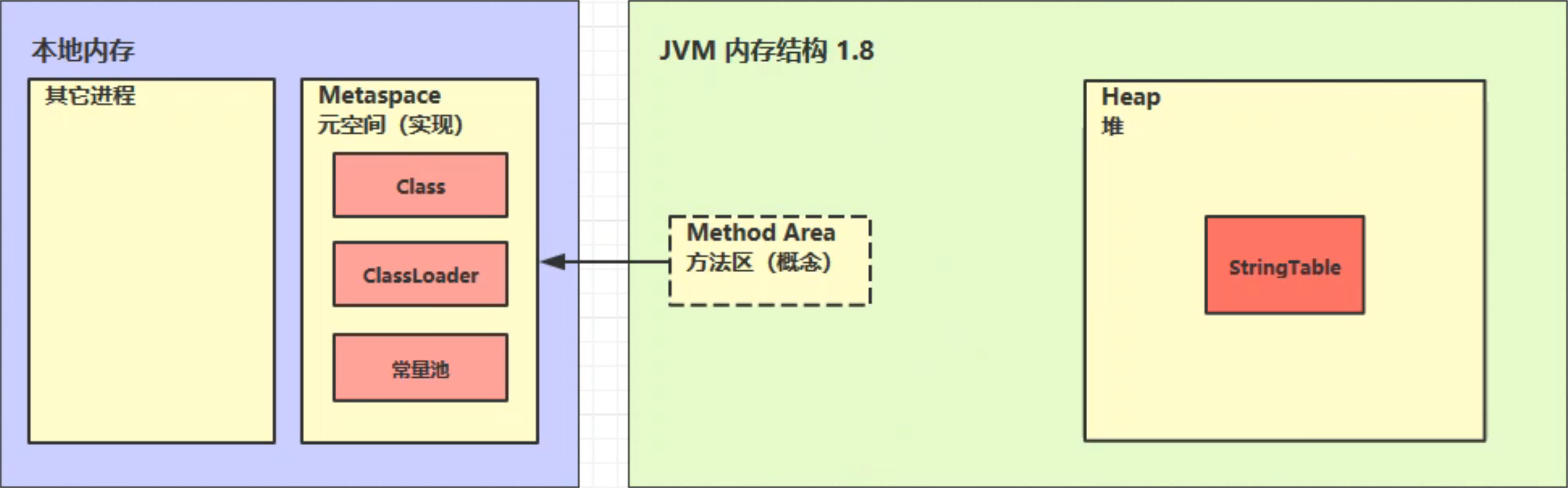
java 6 中的存储位置:
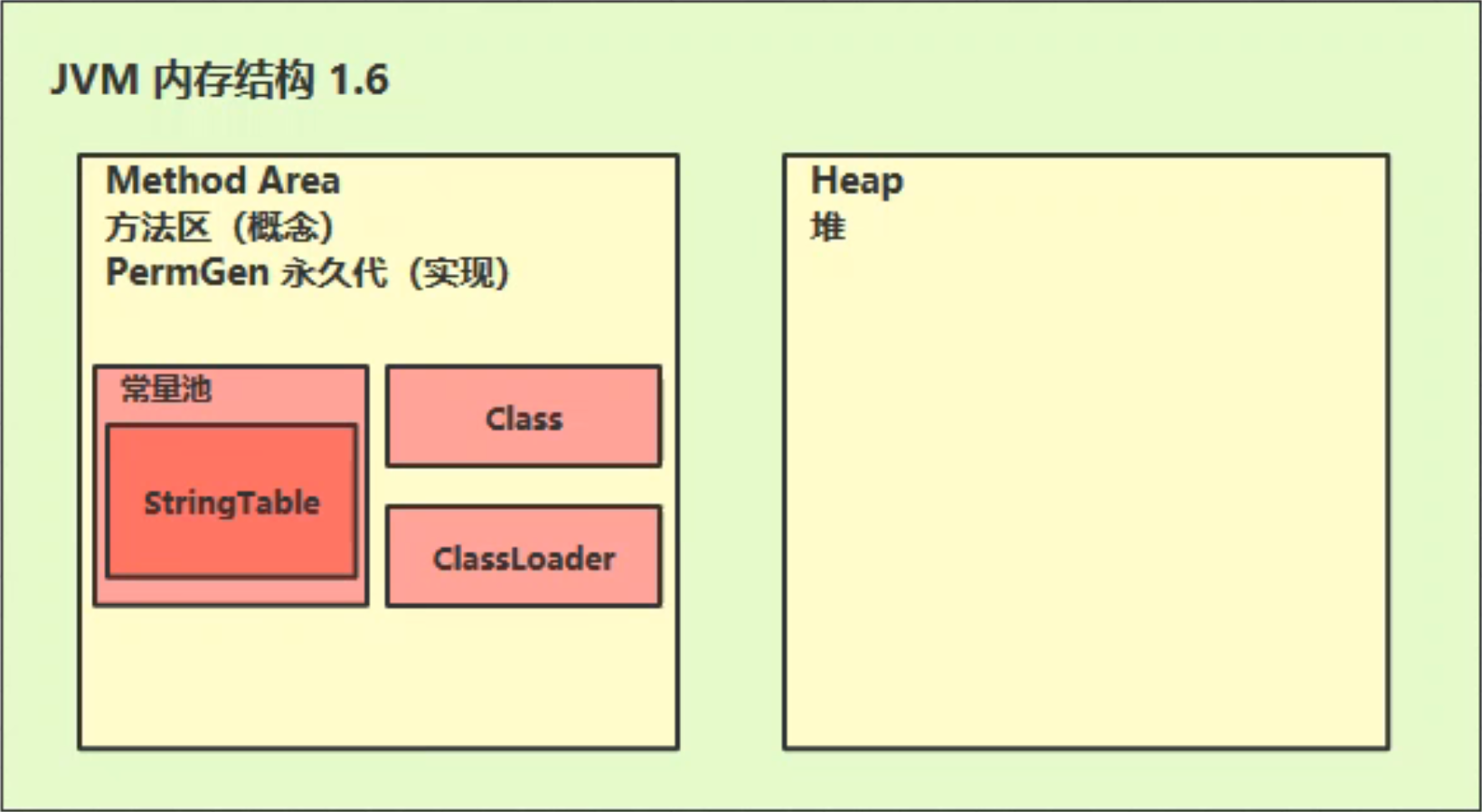
将串池转移到堆内存后,更有利于内存的回收
StringTable的特性
常量池中的字符串仅是符号,第一次用到时才变为对象
利用串池的机制,来避免重复创建字符串对象
字符串变量拼接的原理是 StringBuilder (1.8)
字符串常量拼接的原理是编译期优化
可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
StringTable调优
StringTable的实现类似于Hash表,默认的桶大小是65535(在Java11中),可以使用参数-XX:StringTableSzie=655350 来进行调整。
当项目中字符串变量较多时,可以适当增加StringTable的大小,来提高运行效率。
直接内存
优点:
常见于 NIO 操作时,用于数据缓冲区
分配回收成本较高,但读写性能高
不受 JVM 内存回收管理
首先来看一个例子:
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "E:\\path\\to\\big-file.mp4";
static final String TO = "E:\\a.mp4";
static final int _1Mb = 1024 * 1024;
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
NIO会快很多
文件读写流程:
直接内存溢出
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
禁用显示的垃圾回收
-XX:DisableExplicitGC
直接内存的申请释放
在Java中分配直接内存,大有如下三种主要方式:
- Unsafe.allocateMemory()
- ByteBuffer.allocateDirect()
- native方法
Unsafe类
在unsafe类中,提供了两个方法来进行直接内存的分配和释放
// 申请直接内存内存
public native long allocateMemory(long var1);
// 释放直接内存
public native void freeMemory(long var1);
下面给出一个使用的例子:
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
Unsafe unsafe = Unsafe.getUnsafe();
// 分配内存
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
ByteBuffer类
Unsafe是一个十分原始的底层方法,不适合开发者使用。而ByteBuffer则是留给开发者使用的。下面来看一下其实现:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
可以看到,他创建了一个DirectByteBuffer对象
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
// 计算需要分配内存的大小
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
// 分配直接内存
long base = 0;
try {
base = UNSAFE.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
UNSAFE.setMemory(base, size, (byte) 0);
// 计算内存地址
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 创建cleaner
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
可以看到,DirectByteBuffer也是通过UNSAFE.allocateMemory(size)来申请的直接内存空间。那么释放直接内存的在哪里呢?
可以看到这么一行代码:cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
Cleaner继承自PhantomReference,所以当垃圾回收器在回收DirectByteBuffer这个对象时,就会同步对cleaner进行回收工作;
TODO 补充一下虚引用
Deallocator的实现
private static class Deallocator implements Runnable {
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
UNSAFE.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
对象的创建于存储
对象的创建
创建之前,先检查对象是否被加载。
类加载后,开始分配内存,分配内存的方式有一下几种
指针碰撞:基于标记整理算法的垃圾回收器使用这种方式
空闲链表:基于标记清除算法的使用这种方式(CMS)
内存分配的线程安全性
- CAS配合失败重试机制
- 本地线程分配缓冲(Thread Local Allocation Buffer,TLAB):每个线程在堆中预先分配一块内存区域,使用完之后在加锁分配另一块。
内存分配完成后,会初始化内存为零值。
设置对象头
经过上面几部,一个新对象已经产生,但是,这个对象的构造方法还没有执行。
对象的内存布局
一个对象在内存空间中分为三个部分:
对象头:
32位虚拟机占32bit,64位虚拟机占64bit
对象头主要包含两类数据
- 存储对象自身的运行时数据,包括哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等
- 存储对象指向它的类型元数据的指针
实例数据
对齐填充:仅是占位符的作用,对象起始地址必须是8字节的整数倍。